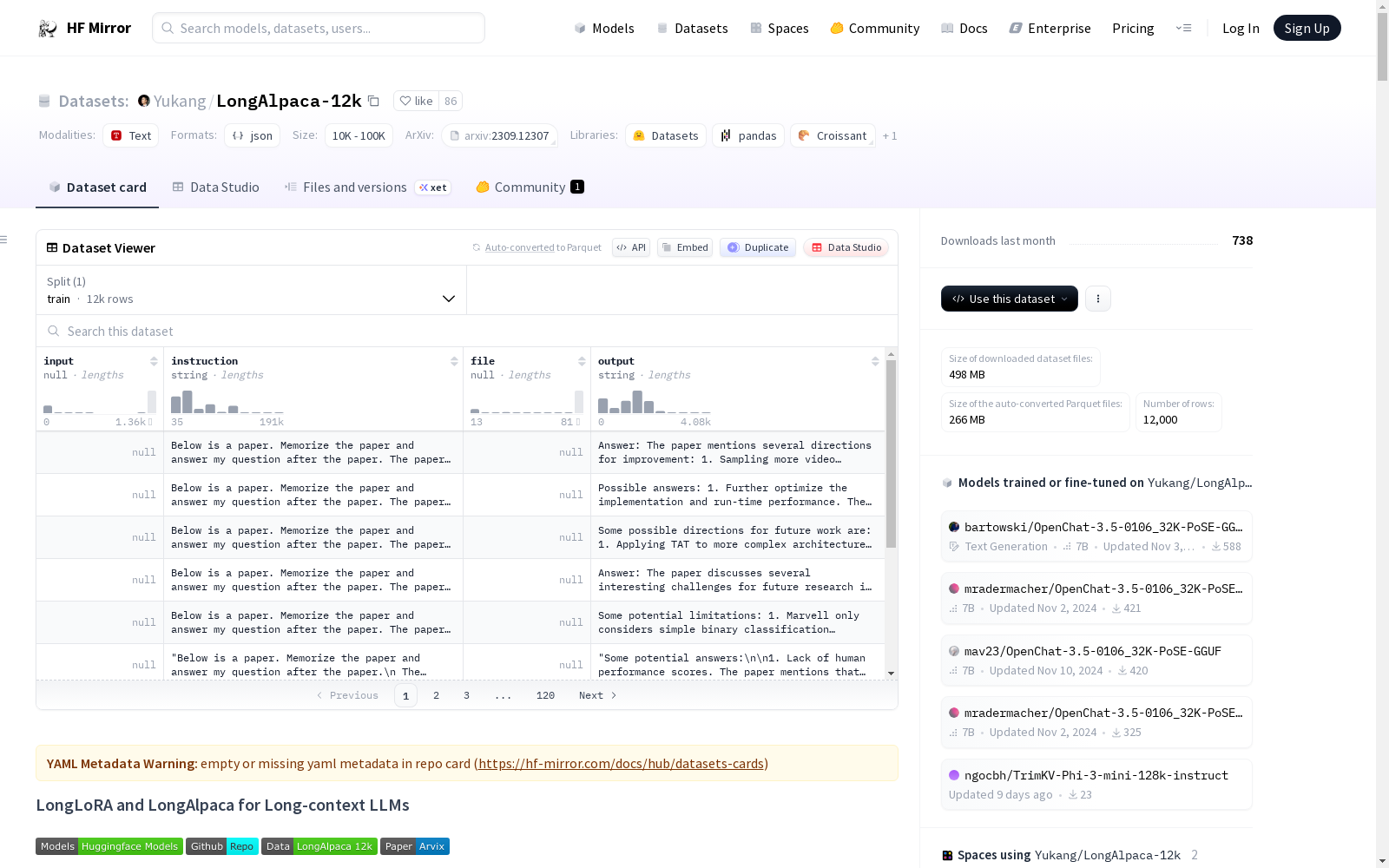
# LongLoRA and LongAlpaca for Long-context LLMs
[](https://huggingface.co/Yukang)
[](https://github.com/dvlab-research/LongLoRA)
[](https://huggingface.co/datasets/Yukang/LongAlpaca-12k)
[](https://arxiv.org/abs/2309.12307)
[](https://github.com/dvlab-research/LongLoRA/blob/main/LICENSE)
[](https://github.com/dvlab-research/LongLoRA/blob/main/DATA_LICENSE)
[](https://github.com/dvlab-research/LongLoRA/blob/main/WEIGHT_LICENSE)
For detailed usage and codes, please visit the [Github project](https://github.com/dvlab-research/LongLoRA).
## TABLE OF CONTENTS
1. [News](#news)
2. [Examples](#examples)
3. [Highlights](#highlights)
4. [How to contribute](#how-to-contribute)
5. [Requirements](#usage-requirements)
6. [Installation and quick guide](#installation-and-quick-guide)
7. [LongAlpaca Data](#longalpaca-data)
8. [Models](#models)
9. [Training](#training)
10. [Evaluation](#evaluation)
11. [Demo](#demo)
12. [Data Generation via Pdf2Text](#data-generation-via-pdf2text)
13. [Citation](#citation)
14. [Acknowledgement](#acknowledgement)
15. [License](#license)
## News
- [x] [2023.10.8] **We release the long instruction-following dataset**, [LongAlpaca-12k](https://huggingface.co/datasets/Yukang/LongAlpaca-12k) and **the corresponding models**, [LongAlpaca-7B](https://huggingface.co/Yukang/LongAlpaca-7B), [LongAlpaca-13B](https://huggingface.co/Yukang/LongAlpaca-13B), and [LongAlpaca-70B](https://huggingface.co/Yukang/LongAlpaca-70B).
- (*The previous sft models*, [Llama-2-13b-chat-longlora-32k-sft](https://huggingface.co/Yukang/Llama-2-13b-chat-longlora-32k-sft) and [Llama-2-70b-chat-longlora-32k-sft](https://huggingface.co/Yukang/Llama-2-70b-chat-longlora-32k-sft), *have been depreciated*.)
- [x] [2023.10.3] We add support GPTNeoX models. Please refer to this [PR](https://github.com/dvlab-research/LongLoRA/pull/32) for usage. Thanks for @naubull2 for this contribution.
- [x] [2023.9.22] We release all our fine-tuned [models](https://huggingface.co/Yukang), including **70B-32k models**, [LLaMA2-LongLoRA-70B-32k](https://huggingface.co/Yukang/Llama-2-70b-longlora-32k), [LLaMA2-LongLoRA-7B-100k](https://huggingface.co/Yukang/Llama-2-7b-longlora-100k-ft). Welcome to check them out!
- [x] [2023.9.22] We release [Paper](http://arxiv.org/abs/2309.12307) and this GitHub repo, including training and evaluation code.
**LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models [[Paper](http://arxiv.org/abs/2309.12307)]** <br />
[Yukang Chen](https://scholar.google.com/citations?user=6p0ygKUAAAAJ&hl=en),
[Shengju Qian](https://scholar.google.com/citations?user=QNnWmasAAAAJ),
[Haotian Tang](https://scholar.google.com/citations?user=WxL13BAAAAAJ&hl),
[Xin Lai](https://scholar.google.com/citations?user=tqNDPA4AAAAJ&hl=zh-CN),
[Zhijian Liu](https://scholar.google.com/citations?user=3coYSTUAAAAJ&hl=en),
[Song Han](https://scholar.google.com/citations?user=E0iCaa4AAAAJ&hl=zh-CN),
[Jiaya Jia](https://scholar.google.com/citations?user=XPAkzTEAAAAJ&hl=en)<br />
## Highlights
1. In LongLoRA approach, The proposed shifted short attention is easy to implement, compatible with Flash-Attention, and is not required during inference.
2. We released all our models, including models from 7B to 70B, context length from 8k to 100k, including [LLaMA2-LongLoRA-7B-100k](https://huggingface.co/Yukang/Llama-2-7b-longlora-100k-ft), [LLaMA2-LongLoRA-13B-64k](https://huggingface.co/Yukang/Llama-2-13b-longlora-64k), and [LLaMA2-LongLoRA-70B-32k](https://huggingface.co/Yukang/Llama-2-70b-longlora-32k).
3. We built up a long-context instruction-following dataset, [LongAlpaca-12k](#longalpaca-data). We released the corresponding [LongAlpaca-7B](https://huggingface.co/Yukang/LongAlpaca-7B), [LongAlpaca-13B](https://huggingface.co/Yukang/LongAlpaca-13B) and [LongAlpaca-70B](https://huggingface.co/Yukang/LongAlpaca-70B) models. To our best knowledge, this is the first open-sourced long-context 70B model.
## How to Contribute
- Make sure to have git installed.
- Create your own [fork](https://github.com/dvlab-research/LongLoRA/fork) of the project.
- Clone the repository on your local machine, using git clone and pasting the url of this project.
- Read both the `Requirements` and `Installation and Quick Guide` sections below.
- Commit and push your changes.
- Make a pull request when finished modifying the project.
## Usage Requirements
To download and use the [pre-trained weights](#pre-trained-weights) you will need:
1. Hugging Face (HF) account with valid email. Note, the email used for HF must alse be used for the license agreement.
2. Accept the Meta [license and acceptable use policy](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)
## Installation and Quick Guide
To install and run the application:
1. [Fork this repo](https://github.com/dvlab-research/LongLoRA/fork) on github
2. Clone the repository on your local machine, using git clone and pasting the url of this project.
3. Run the following code:
```
pip install -r requirements.txt
pip install flash-attn --no-build-isolation
```
4. Use either a [Released model](#released-models) or [Fine tune](#fine-tuning) a model to fit your preferences.
5. Test your model by chat.
6. Deploy your own demo.
## LongAlpaca Data
LongAlpaca-12k contains 9k long QA data that we collected and 3k short QA sampled from the original [Alpaca data](https://github.com/tatsu-lab/stanford_alpaca/blob/main/alpaca_data.json). This is to avoid the case that the model might degrade at short instruction following. The data we collect contains various types and amounts as the following figure.
| Data | Short QA | Long QA | Total | Download |
|:---------------|----------|----------|----------|----------|
| LongAlpaca-12k | 3k | 9k | 12k | [Link](https://huggingface.co/datasets/Yukang/LongAlpaca-12k) |
Following the original Alpaca format, our Long QA data uses the following prompts for fine-tuning:
- `instruction`: `str`, describes the task the model should perform. For example, to answer a question after reading a book section or paper. We vary the contents and questions to make instructions diverse.
- `output`: `str`, the answer to the instruction.
We did not use the `input` format in the Alpaca format for simplicity.
## Models
### Models with supervised fine-tuning
| Model | Size | Context | Train | Link |
|:---------------|------|---------|---------|-----------------------------------------------------------------------------------------------------------------------|
| LongAlpaca-7B | 7B | 32768 | Full FT | [Model](https://huggingface.co/Yukang/LongAlpaca-7B) |
| LongAlpaca-13B | 13B | 32768 | Full FT | [Model](https://huggingface.co/Yukang/LongAlpaca-13B) |
| LongAlpaca-70B | 70B | 32768 | LoRA+ | [Model](https://huggingface.co/Yukang/LongAlpaca-70B) [(LoRA-weight)](https://huggingface.co/Yukang/LongAlpaca-70B-lora) |
### Models with context extension via fully fine-tuning
| Model | Size | Context | Train | Link |
|:----------------------------|------|---------|-------|-------------------------------------------------------------------|
| Llama-2-7b-longlora-8k-ft | 7B | 8192 | Full FT | [Model](https://huggingface.co/Yukang/Llama-2-7b-longlora-8k-ft) |
| Llama-2-7b-longlora-16k-ft | 7B | 16384 | Full FT | [Model](https://huggingface.co/Yukang/Llama-2-7b-longlora-16k-ft) |
| Llama-2-7b-longlora-32k-ft | 7B | 32768 | Full FT | [Model](https://huggingface.co/Yukang/Llama-2-7b-longlora-32k-ft) |
| Llama-2-7b-longlora-100k-ft | 7B | 100000 | Full FT | [Model](https://huggingface.co/Yukang/Llama-2-7b-longlora-100k-ft) |
| Llama-2-13b-longlora-8k-ft | 13B | 8192 | Full FT | [Model](https://huggingface.co/Yukang/Llama-2-13b-longlora-8k-ft) |
| Llama-2-13b-longlora-16k-ft | 13B | 16384 | Full FT | [Model](https://huggingface.co/Yukang/Llama-2-13b-longlora-16k-ft) |
| Llama-2-13b-longlora-32k-ft | 13B | 32768 | Full FT | [Model](https://huggingface.co/Yukang/Llama-2-13b-longlora-32k-ft) |
### Models with context extension via improved LoRA fine-tuning
| Model | Size | Context | Train | Link |
|:----------------------------|------|---------|-------|---------------------------------------------------------------------|
| Llama-2-7b-longlora-8k | 7B | 8192 | LoRA+ | [LoRA-weight](https://huggingface.co/Yukang/Llama-2-7b-longlora-8k) |
| Llama-2-7b-longlora-16k | 7B | 16384 | LoRA+ | [LoRA-weight](https://huggingface.co/Yukang/Llama-2-7b-longlora-16k) |
| Llama-2-7b-longlora-32k | 7B | 32768 | LoRA+ | [LoRA-weight](https://huggingface.co/Yukang/Llama-2-7b-longlora-32k) |
| Llama-2-13b-longlora-8k | 13B | 8192 | LoRA+ | [LoRA-weight](https://huggingface.co/Yukang/Llama-2-13b-longlora-8k) |
| Llama-2-13b-longlora-16k | 13B | 16384 | LoRA+ | [LoRA-weight](https://huggingface.co/Yukang/Llama-2-13b-longlora-16k) |
| Llama-2-13b-longlora-32k | 13B | 32768 | LoRA+ | [LoRA-weight](https://huggingface.co/Yukang/Llama-2-13b-longlora-32k) |
| Llama-2-13b-longlora-64k | 13B | 65536 | LoRA+ | [LoRA-weight](https://huggingface.co/Yukang/Llama-2-13b-longlora-64k) |
| Llama-2-70b-longlora-32k | 70B | 32768 | LoRA+ | [LoRA-weight](https://huggingface.co/Yukang/Llama-2-70b-longlora-32k) |
| Llama-2-70b-chat-longlora-32k | 70B | 32768 | LoRA+ | [LoRA-weight](https://huggingface.co/Yukang/Llama-2-70b-chat-longlora-32k) |
## Training
### Pre-trained weights
We use LLaMA2 models as the pre-trained weights and fine-tune them to long context window sizes. Download based on your choices.
| Pre-trained weights |
|:-------------------------------------------------------------------------------------|
| [Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) |
|[Llama-2-13b-hf](https://huggingface.co/meta-llama/Llama-2-13b-hf) |
| [Llama-2-70b-hf](https://huggingface.co/meta-llama/Llama-2-70b-hf) |
| [Llama-2-7b-chat-hf](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf) |
| [Llama-2-13b-chat-hf](https://huggingface.co/meta-llama/Llama-2-13b-chat-hf) |
| [Llama-2-70b-chat-hf](https://huggingface.co/meta-llama/Llama-2-70b-chat-hf) |
This project also supports GPTNeoX models as the base model architecture. Some candidate pre-trained weights may include [GPT-NeoX-20B](https://huggingface.co/EleutherAI/gpt-neox-20b), [Polyglot-ko-12.8B](https://huggingface.co/EleutherAI/polyglot-ko-12.8b) and other variants.
### Fine-tuning
```
torchrun --nproc_per_node=8 fine-tune.py \
--model_name_or_path path_to/Llama-2-7b-hf \
--bf16 True \
--output_dir path_to_saving_checkpoints \
--cache_dir path_to_cache \
--model_max_length 8192 \
--use_flash_attn True \
--low_rank_training False \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 2 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 1000 \
--save_total_limit 2 \
--learning_rate 2e-5 \
--weight_decay 0.0 \
--warmup_steps 20 \
--lr_scheduler_type "constant_with_warmup" \
--logging_steps 1 \
--deepspeed "ds_configs/stage2.json" \
--tf32 True \
--max_steps 1000
```
- Please remember to change `path_to/Llama-2-7b-hf`, `path_to_saving_checkpoints`, `path_to_cache` to your own directory.
- Note that you can change `model_max_length` to other values.
- You could change `ds_configs/stage2.json` to `ds_configs/stage3.json` if you want.
- Please set `use_flash_attn` as `False` if you use V100 machines or do not install flash attention.
- You can set `low_rank_training` as `False` if you want to use fully fine-tuning. It will cost more GPU memory and slower, but the performance will be a bit better.
- When training is finished, to get the full model weight:
```
cd path_to_saving_checkpoints && python zero_to_fp32.py . pytorch_model.bin
```
### Supervised Fine-tuning
```
torchrun --nproc_per_node=8 supervised-fine-tune.py \
--model_name_or_path path_to_Llama2_chat_models \
--bf16 True \
--output_dir path_to_saving_checkpoints \
--model_max_length 32768 \
--use_flash_attn True \
--data_path LongAlpaca-12k.json \
--low_rank_training True \
--num_train_epochs 3 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 2 \
--gradient_accumulation_steps 1 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 1000 \
--save_total_limit 2 \
--learning_rate 2e-5 \
--weight_decay 0.0 \
--warmup_steps 20 \
--lr_scheduler_type "constant_with_warmup" \
--logging_steps 1 \
--deepspeed "ds_configs/stage2.json" \
--tf32 True
```
- There is no need to make supervised fine-tuning upon the fine-tuned context extended models. It is all right to directly use base model as Llama2-chat models, as the amount of long instruction following data is enough for SFT.
- Our long instruction following data can be found in [LongAlpaca-12k.json](https://huggingface.co/datasets/Yukang/LongAlpaca-12k).
### Get trainable weights in low-rank training
In low-rank training, we set embedding and normalization layers as trainable. Please use the following line to extract the trainable weights `trainable_params.bin` from `pytorch_model.bin`
```
python3 get_trainable_weights.py --checkpoint_path path_to_saving_checkpoints --trainable_params "embed,norm"
```
### Merge LoRA Weight
Merge the LoRA weights of `pytorch_model.bin` and trainable parameters `trainable_params.bin`, save the resulting model into your desired path in the Hugging Face format:
```
python3 merge_lora_weights_and_save_hf_model.py \
--base_model path_to/Llama-2-7b-hf \
--peft_model path_to_saving_checkpoints \
--context_size 8192 \
--save_path path_to_saving_merged_model
```
For example,
```
python3 merge_lora_weights_and_save_hf_model.py \
--base_model /dataset/pretrained-models/Llama-2-7b-hf \
--peft_model /dataset/yukangchen/hf_models/lora-models/Llama-2-7b-longlora-8k \
--context_size 8192 \
--save_path /dataset/yukangchen/models/Llama-2-7b-longlora-8k-merged
```
## Evaluation
### Perplexity Validation
To evaluate a model that is trained in the low-rank setting, please set both `base_model` and `peft_model`. `base_model` is the pre-trained weight. `peft_model` is the path to the saved checkpoint, which should contain `trainable_params.bin`, `adapter_model.bin` and `adapter_config.json`. For example,
```
python3 eval.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to/Llama-2-7b-hf --peft_model path_to_saving_checkpoints --data_path pg19/test.bin
```
To evaluate a model that is fully fine-tuned, you only need to set `base_model` as the path to the saved checkpoint, which should contain `pytorch_model.bin` and `config.json`. `peft_model` should be ignored.
```
python3 eval.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to_saving_checkpoints --data_path pg19/test.bin
```
- Note that `--seq_len` is to set the sequence length for evaluation. `--context_size` is to set the context length of the model during fine-tuning. `--seq_len` should not be larger than `--context_size`.
- We have already tokenized the validation and test splits of PG19 and proof-pile dataset into `pg19/validation.bin`, `pg19/test.bin`, and `proof-pile/test_sampled_data.bin`, with the tokenizer of LLaMA. `proof-pile/test_sampled_data.bin` contains 128 documents that are randomly sampled from the total proof-pile test split. For each document, it has at least 32768 tokens. We also release the sampled ids in [proof-pile/test_sampled_ids.bin](https://drive.google.com/file/d/1cnzWODLRQYAd7HeugzLCIhaqzaLZv7J5/view?usp=share_link). You can download them from the links below.
| Dataset | Split | Link |
|:-----------|------------|--------------------------------------------------------------------------------------------------------------|
| PG19 | validation | [pg19/validation.bin](https://drive.google.com/file/d/1rbJvb0qRIf2mQoN2ON7S93TbTzMnlrN6/view?usp=share_link) |
| PG19 | test | [pg19/test.bin](https://drive.google.com/file/d/1QANDMdctpacPAYgS04adDXqByGEq-Ret/view?usp=share_link) |
| Proof-pile | test | [proof-pile/test_sampled_data.bin](https://drive.google.com/file/d/1bUI5lPDvrqzY_XXJJ2sSuvZx0Y9AZClE/view?usp=share_link) |
### Passkey Retrieval
We provide a manner to test the passkey retrieval accuracy. For example,
```
python3 passkey_retrivial.py \
--context_size 32768 \
--base_model path_to/Llama-2-7b-longlora-32k \
--max_tokens 32768 \
--interval 1000
```
- Note that the `context_size` is the context length during fine-tuning.
- `max_tokens` is maximum length for the document in passkey retrieval evaluation.
- `interval` is the interval during the document length increasing. It is a rough number because the document increases by sentences.
## Demo
### Local Inference
To chat with [Llama-2-13b-chat-longlora-32k-sft](https://huggingface.co/Yukang/Llama-2-13b-chat-longlora-32k-sft) or [Llama-2-70b-chat-longlora-32k-sft](https://huggingface.co/Yukang/Llama-2-70b-chat-longlora-32k-sft), you need to run `merge_lora_weights_and_save_hf_model.py` first, and then:
```
python3 inference.py \
--base_model path_to_model \
--question $question \
--context_size $context_length \
--max_gen_len $max_gen_len \
--flash_attn True \
--material $material_content \
--material_type $material_type \
--material_title $material_title
```
To ask a question related to a book:
```
python3 inference.py \
--base_model /data/models/Llama-2-13b-chat-longlora-32k-sft \
--question "Why doesn't Professor Snape seem to like Harry?" \
--context_size 32768 \
--max_gen_len 512 \
--flash_attn True \
--material "materials/Harry Potter and the Philosophers Stone_section2.txt" \
--material_type "book" \
--material_title "Harry Potter and the Philosophers Stone"
```
Note that you can ignore `material_type` or `material_title`.
To ask a question related to a paper:
```
python3 inference.py \
--base_model /data/models/Llama-2-13b-chat-longlora-32k-sft \
--question "What are the main contributions and novelties of this work?" \
--context_size 32768 \
--max_gen_len 512 \
--flash_attn True \
--material "materials/paper1.txt" \
--material_type "paper"
```
### Online Demo
To deploy your own demo run
```
python3 demo.py \
--base_model path_to_model \
--context_size $context_size \
--max_gen_len $max_gen_len \
--flash_attn True
```
Example
```
python3 demo.py \
--base_model /data/models/Llama-2-13b-chat-longlora-32k-sft \
--context_size 32768 \
--max_gen_len 512 \
--flash_attn True
```
- Note that `flash_attn=True` will make the generation slow but save much GPU memory.
## Data Generation via Pdf2text
During our dataset collection, we convert paper and books from pdf to text. The conversion quality has a large influence on the final model quality. We think that this step is non-trivial. We release the tool for the pdf2txt conversion, in the folder `pdf2txt`. It is built upon `pdf2image`, `easyocr`, `ditod` and `detectron2`. Please refer to the [README.md](pdf2txt/README.md) in `pdf2txt` for more details.
## Citation
If you find this project useful in your research, please consider citing:
```
@article{longlora,
title={LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models},
author={Yukang Chen and Shengju Qian and Haotian Tang and Xin Lai and Zhijian Liu and Song Han and Jiaya Jia},
journal={arXiv:2309.12307},
year={2023}
}
```
```
@misc{long-alpaca,
author = {Yukang Chen and Shaozuo Yu and Shengju Qian and Haotian Tang and Xin Lai and Zhijian Liu and Song Han and Jiaya Jia},
title = {Long Alpaca: Long-context Instruction-following models},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/dvlab-research/LongLoRA}},
}
```
## Acknowledgement
- This work is built upon the [LLaMA2](https://ai.meta.com/llama) as the pre-trained models.
- This work can also be built upon the [GPTNeoX-HF](https://huggingface.co/docs/transformers/model_doc/gpt_neox) which is based upon [EleutherAI/GPTNeoX](https://github.com/EleutherAI/gpt-neox) as the pre-trained model architecture.
- This work is based on [DeepSpeed](https://github.com/microsoft/DeepSpeed), [peft](https://github.com/huggingface/peft), and [Flash-Attention2](https://github.com/Dao-AILab/flash-attention) for acceleration.
- Some evaluation code is modified upon [Landmark Attention](https://github.com/epfml/landmark-attention).
- We use [LongChat](https://github.com/DachengLi1/LongChat) for the retrieval evaluation.
## License
- LongLoRA is licensed under the Apache License 2.0. This means that it requires the preservation of copyright and license notices.
- Data and weights are under CC-BY-NC 4.0 License. They are licensed for research use only, and allowed only non-commercial. Models trained using the dataset should not be used outside of research purposes.