OpenAnimal
收藏UniTransfer: Video Concept Transfer via Progressive Spatial and Timestep Decomposition
基本信息
- 标题: UniTransfer: Video Concept Transfer via Progressive Spatial and Timestep Decomposition
- 作者: Guojun Lei, Rong Zhang, Chi Wang, Tianhang Liu, Hong Li, Zhiyuan Ma, weiwei xu
- 相关链接:
- arXiv
- NeurIPS2025
- Code
- UniTransfer
摘要
Recent advancements in video generation models have enabled the creation of diverse and realistic videos, with promising applications in advertising and film production. However, as one of the essential tasks of video generation models, video concept transfer remains significantly challenging. Existing methods generally model video as an entirety, leading to limited flexibility and precision when solely editing specific regions or concepts. To mitigate this dilemma, we propose a novel architecture UniTransfer, which introduces both spatial and diffusion timestep decomposition in a progressive paradigm, achieving precise and controllable video concept transfer. Specifically, in terms of spatial decomposition, we decouple videos into three key components: the foreground subject, the background, and the motion flow. Building upon this decomposed formulation, we further introduce a dual-to-single-stream DiT-based architecture for supporting fine-grained control over different components in the videos. We also introduce a self-supervised pretraining strategy based on random masking to enhance the decomposed representation learning from large-scale unlabeled video data. Inspired by the Chain-of-Thought reasoning paradigm, we further revisit the denoising diffusion process and propose a Chain-of-Prompt (CoP) mechanism to achieve the timestep decomposition. We decompose the denoising process into three stages of different granularity and leverage large language models (LLMs) for stage-specific instructions to guide the generation progressively. We also curate an animal-centric video dataset called OpenAnimal to facilitate the advancement and benchmarking of research in video concept transfer. Extensive experiments demonstrate that our method achieves high-quality and controllable video concept transfer across diverse reference images and scenes, surpassing existing baselines in both visual fidelity and editability.
方法概述
- 核心架构: UniTransfer
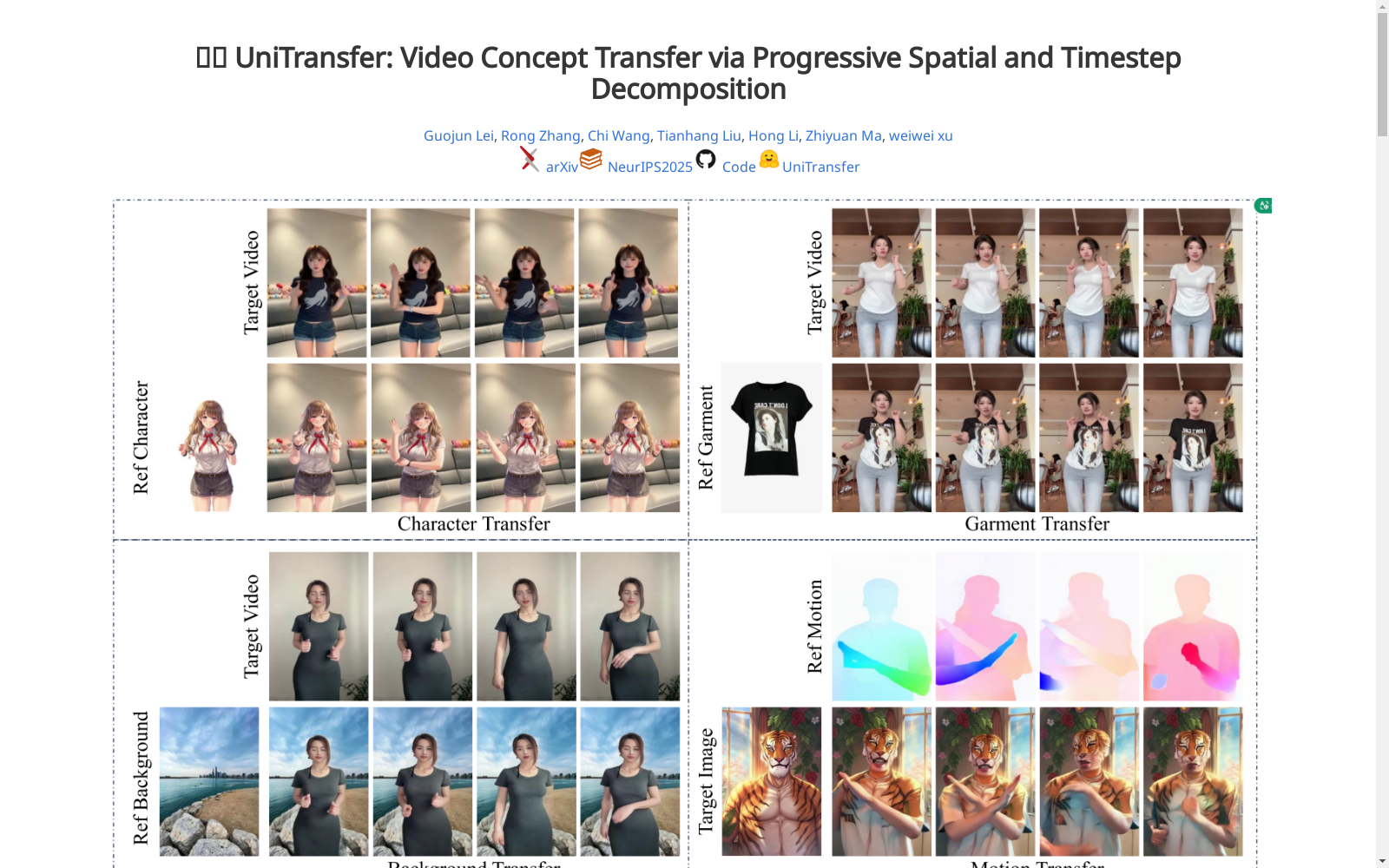
- 空间分解: 将视频解耦为三个关键组成部分:前景主体、背景和运动流。
- 架构设计: 基于DiT的双流到单流架构,支持对视频中不同组件的细粒度控制。
- 预训练策略: 基于随机掩码的自监督预训练策略,从大规模未标记视频数据中增强分解表示学习。
- 时间步分解: 受思维链推理范式启发,提出提示链机制,将去噪过程分解为三个不同粒度的阶段,并利用大型语言模型进行阶段特定指令逐步引导生成。
- 配套数据集: 构建了一个以动物为中心的视频数据集OpenAnimal,以促进视频概念转移研究的进展和基准测试。
可视化结果
人类前景转移
- 包含多组结果对比。
人类背景转移
- 包含多组结果对比。
服装转移
- 包含多组结果对比。
动物转移比较
- 比较方法: MotionClone, Motion-I2V, MOFA-Video, Ours
- 包含与参考视频及多种方法的对比结果。
人类转移比较
- 比较方法: AnyV2V, Control-Video, AnimateAnyone, Champ, UniAnimate, Ours
- 包含与参考视频及多种方法的对比结果。
动物转移
- 包含多组结果展示。
OpenAnimal数据集
- 展示了数据集的多个示例。