CogAlign
收藏Hugging Face2025-02-18 更新2025-02-19 收录
下载链接:
https://huggingface.co/datasets/Salesforce/CogAlign
下载链接
链接失效反馈官方服务:
资源简介:
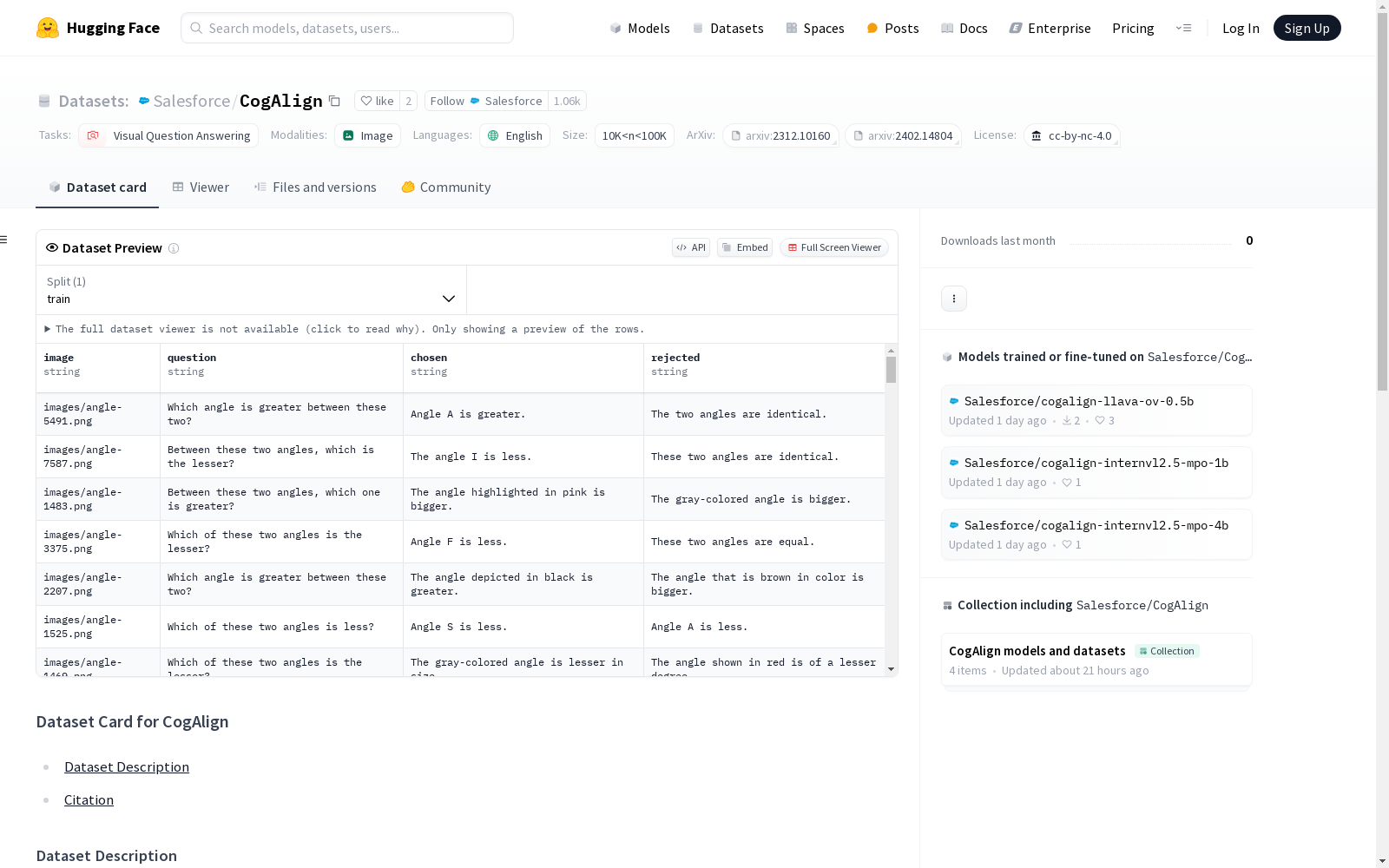
CogAlign是一个针对视觉语言模型(VLMs)的后训练策略,旨在增强其视觉算术能力。该数据集是一个合成的训练数据集,包含64,000个示例,用于促进这种后训练过程。CogAlign受到皮亚杰认知发展理论的启发,专注于提高VLM对守恒和去中心化的理解。每个示例包括一个视觉输入、一个提示比较特定属性的查询、一个与视觉输入一致的积极回应,以及一个与之矛盾的消极回应。训练VLMs使用CogAlign后,在依赖视觉算术的下游任务中性能得到提升,特别是在图表理解和几何问题解决方面。该数据集允许VLMs学习基本的视觉算术,从而在涉及视觉算术的任务中表现更好。重要的是,CogAlign在性能上可以与特定任务的SFT方法相媲美甚至更好,同时所需的训练数据量减少了60%。
提供机构:
Salesforce
创建时间:
2025-02-17
搜集汇总
数据集介绍
构建方式
CogAlign数据集依据皮亚杰认知发展理论设计,旨在通过64,000个合成示例,促进视觉语言模型(VLMs)的视觉算术能力后天训练。每个示例包含一个视觉输入、一个促使比较特定属性的查询、一个与视觉输入一致的正向响应以及一个矛盾的负向响应。
使用方法
用户可通过HuggingFace的接口访问CogAlign数据集,该数据集以JSON格式存储,包含图像路径、问题、选定的答案和被拒绝的答案字段。用户可以按照数据集提供的训练和测试分割,对视觉语言模型进行后天训练,以增强模型在视觉算术任务上的表现。
背景与挑战
背景概述
CogAlign数据集是在视觉语言模型(VLMs)领域的一项重要研究成果,由Huang等人于2025年创建。该数据集以皮亚杰的认知发展理论为灵感,旨在通过后训练策略提升VLMs在视觉运算能力上的表现。包含64000个合成示例的CogAlign数据集,为VLMs提供了视觉输入、比较特定属性的查询、与视觉输入一致的正向响应以及矛盾的负向响应。该数据集不仅对VLMs在视觉运算相关的下游任务中表现出平均性能提升,如在CHOCOLATE图表理解数据集上提高4.6%,在MATH-VISION数据集中的几何问题解决部分提高2.9%,而且其效果可媲美或超越特定任务的学习方法,同时所需数据量减少了60%。
当前挑战
在CogAlign数据集的构建和应用过程中,研究者面临着多项挑战。首先,如何设计能够有效提升视觉运算能力的数据集结构,保持视觉输入与查询之间的一致性和矛盾性,是一大挑战。其次,数据集在促进VLMs学习基础视觉运算的同时,还需考虑其在不同任务中的泛化能力。此外,如何在保证数据质量的前提下,控制数据规模以满足不同训练需求,也是构建过程中必须考虑的问题。
常用场景
经典使用场景
CogAlign数据集作为视觉语言模型(VLMs)的后训练策略,其经典使用场景在于通过64,000个合成示例,促进VLMs在视觉算术能力上的增强。该数据集的设计理念源自皮亚杰的认知发展理论,旨在提升模型对守恒性和去集中性的理解,进而优化模型在视觉算术相关任务的表现。
解决学术问题
该数据集解决了视觉语言模型在处理视觉算术任务时的性能局限问题。通过训练,模型在图表理解和几何问题解决等下游任务中展现出平均性能提升,具体表现在CHOCOLATE图表理解数据集上平均提高4.6%,在MATH-VISION数据集中几何相关问题上的平均性能增益为2.9%。CogAlign的数据结构和设计理念对于提升VLMs在视觉算术任务上的泛化能力具有显著意义。
实际应用
在实际应用中,CogAlign数据集的应用有助于提升VLMs在处理包含视觉算术需求的应用场景中的表现,例如在智能问答系统中,模型能够更准确地理解并回答与视觉信息相关的算术问题,增强系统的实用性和准确性。
数据集最近研究
最新研究方向
在视觉语言模型的领域,CogAlign数据集的创建旨在通过后训练策略提升模型对视觉算术的理解能力。近期研究聚焦于该数据集在促进视觉语言模型掌握守恒与去中心化概念方面的应用,进而增强模型在图表理解和几何问题解决等下游任务中的性能。研究结果表明,采用CogAlign训练的模型在CHOCOLATE图表理解数据集上平均性能提升4.6%,在MATH-VISION数据集的几何问题解决子集上平均性能提升2.9%。这一发现不仅验证了CogAlign数据集的有效性,而且显示出其在减少训练数据需求方面的优势,为视觉算术相关的任务提供了有力支持。
以上内容由遇见数据集搜集并总结生成


