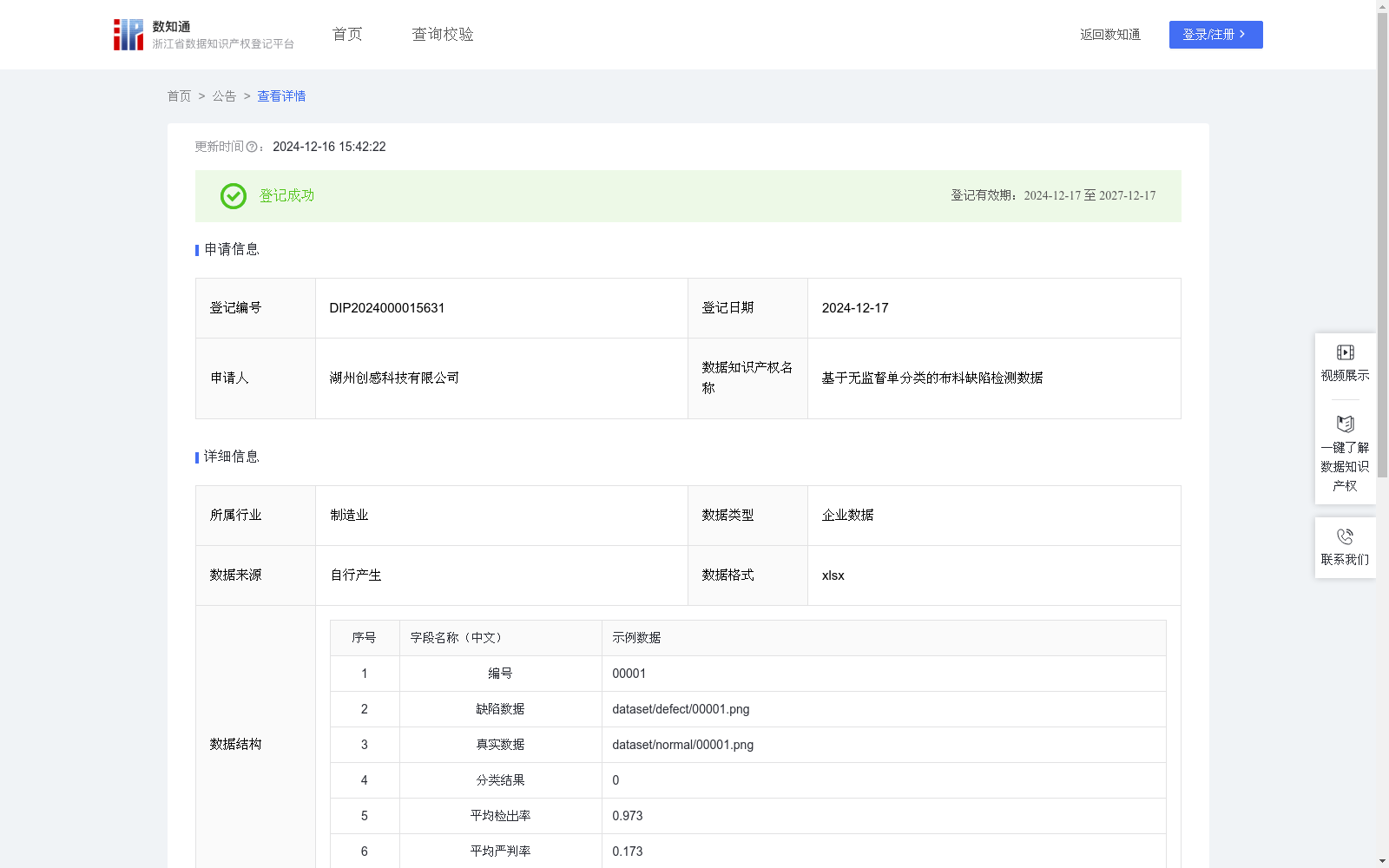
基于无监督单分类的布料缺陷检测数据
收藏浙江省数据知识产权登记平台2024-12-16 更新2024-12-17 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/104923
下载链接
链接失效反馈官方服务:
资源简介:
基于无监督单分类的布料缺陷检测技术在纺织行业中具有重要的实际应用价值。此类检测系统能够在没有缺陷样本或缺陷样本较少的情况下,通过分析正常布料图像的特征,识别出潜在的异常区域。这项技术特别适用于布料生产线的实时质量监控,帮助检测因加工、染色或材料问题而产生的细微瑕疵。相比传统的人工检测,无监督单分类检测能够自动识别异常,提高检测效率和准确性,减少人工干预的成本。数据收集:在该算法中,主要收集正常布料图像和少量缺陷布料图像,以建立单一分类的无监督检测基础。每个样本包含:缺陷数据图像(.png格式)和正常数据图像(.png格式),正常数据作为模型学习的主要样本,用于构建正常布料图像的特征空间,而缺陷数据用于检测模型性能的评估。
数据预处理:对原始布料图像进行预处理操作,包括缩放、归一化等,使得图像符合模型的输入要求。在预处理阶段,重点提取正常布料的特征,以帮助模型构建正常模式的特征分布。
模型构建:利用无监督学习算法构建布料缺陷检测模型。网络输入为正常布料的图像数据,输出为分类结果,0表示正常,1表示缺陷。模型通过对正常样本的特征学习,形成特征空间分布,在检测阶段,偏离正常特征分布的样本即被标记为缺陷。具体算法公式如下:F_normal=Encoder(I_normal),C={0 if D(F_test, F_normal) < T; 1 if D(F_test, F_normal) >= T}。其中Encoder用于提取正常样本I_normal的特征F_normal,D(F_test, F_normal)为测试样本与正常样本特征的距离,当该距离大于阈值T时,分类结果判断为缺陷。模型评估使用平均检出率和平均严判率进行评估,以保证模型的准确性与严格性。
Unsupervised one-class classification-based fabric defect detection technology holds significant practical application value in the textile industry. Such detection systems can identify potential abnormal regions by analyzing the features of normal fabric images, even when there are no defect samples or only a limited number of defect samples available. This technology is particularly suitable for real-time quality monitoring in fabric production lines, helping detect subtle defects caused by processing, dyeing, or material issues. Compared with traditional manual detection, unsupervised one-class classification detection can automatically identify abnormalities, improve detection efficiency and accuracy, and reduce the cost of manual intervention.
Data Collection:
In this algorithm, normal fabric images and a small number of defect fabric images are primarily collected to establish the foundation for unsupervised one-class detection. Each sample includes: defect data images (in .png format) and normal data images (in .png format). Normal data serves as the primary samples for model learning, used to construct the feature space of normal fabric images, while defect data is utilized for evaluating the performance of the detection model.
Data Preprocessing:
Preprocessing operations are performed on the original fabric images, including scaling, normalization, etc., to ensure that the images meet the input requirements of the model. During the preprocessing stage, the features of normal fabrics are primarily extracted to assist the model in building the feature distribution of normal patterns.
Model Construction:
A fabric defect detection model is built using unsupervised learning algorithms. The network takes normal fabric image data as input and outputs classification results, where 0 represents normal and 1 represents defect. The model learns the features of normal samples to form a feature space distribution; during the detection stage, samples that deviate from the normal feature distribution are marked as defects. The specific algorithm formula is as follows:
$$F_{ ext{normal}} = Encoder(I_{ ext{normal}}), quad C = egin{cases}0 & ext{if } D(F_{ ext{test}}, F_{ ext{normal}}) < T \1 & ext{if } D(F_{ ext{test}}, F_{ ext{normal}}) geq Tend{cases}$$
Here, Encoder is used to extract the feature $F_{ ext{normal}}$ of the normal sample $I_{ ext{normal}}$, $D(F_{ ext{test}}, F_{ ext{normal}})$ denotes the distance between the test sample and the normal sample features. When this distance is greater than the threshold $T$, the classification result is judged as a defect. The model is evaluated using the average detection rate and average strict judgment rate to ensure the accuracy and strictness of the model.
提供机构:
湖州创感科技有限公司
创建时间:
2024-11-14
搜集汇总
数据集介绍
特点
该数据集包含7604条布料缺陷检测数据,用于无监督单分类技术,适用于纺织行业的质量监控,通过算法自动识别布料缺陷,提高检测效率和准确性。
以上内容由遇见数据集搜集并总结生成


