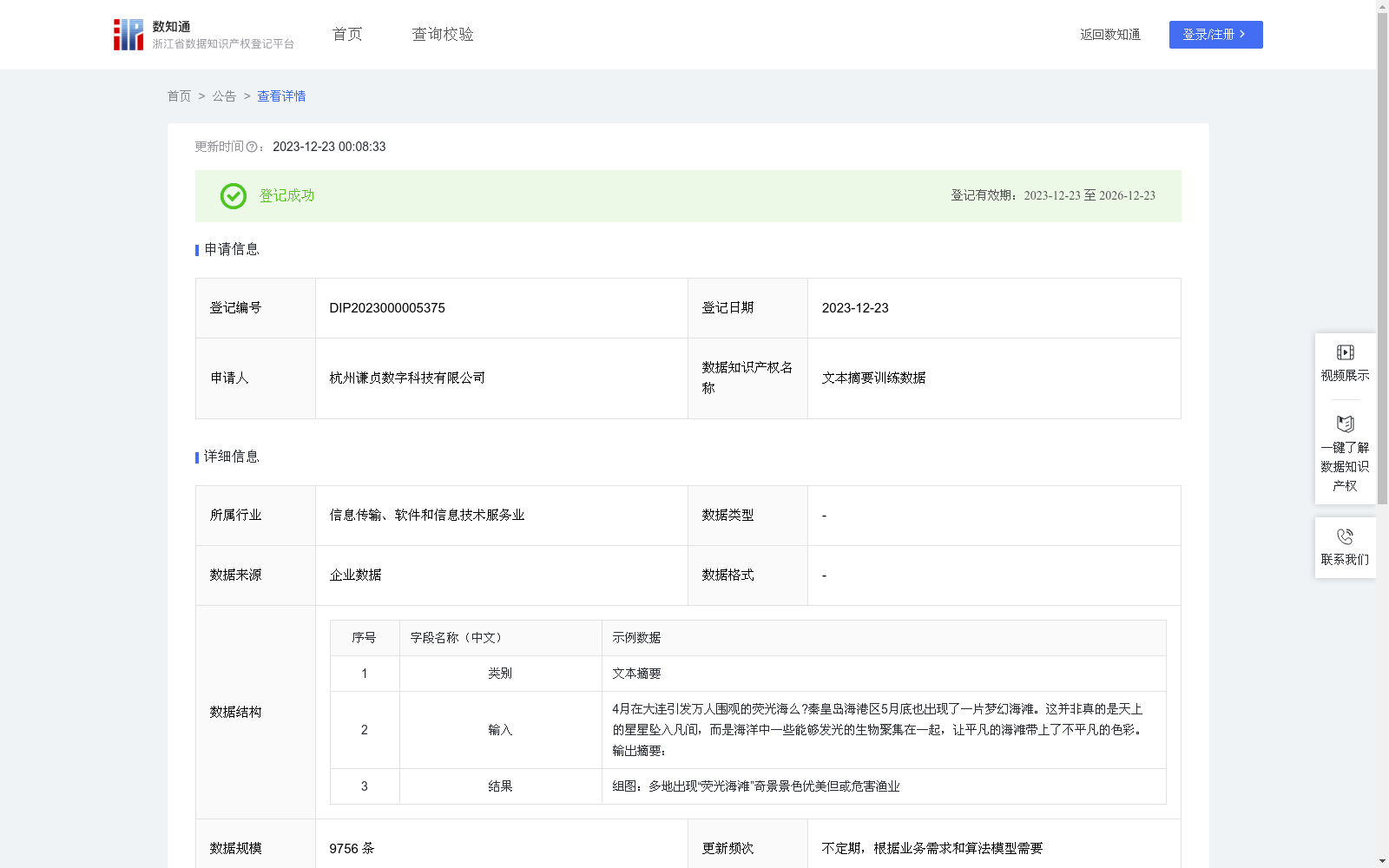
文本摘要训练数据
收藏浙江省数据知识产权登记平台2023-12-23 更新2024-05-08 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/22234
下载链接
链接失效反馈官方服务:
资源简介:
应用场景
适用条件与范围
新闻摘要:从新闻文章中自动生成摘要,帮助读者快速了解主要内容。
学术研究:为学术论文、报告等长篇文档生成摘要,提高研究效率。
企业文档管理:自动提取会议记录、报告、电子邮件等业务文档的关键信息。
法律文件处理:从法律文档如案件记录、法律意见书中生成摘要。
医疗记录摘要:从病历报告中提取关键信息,便于医生快速获取病人状况。
内容推荐系统:为文章、博客或视频内容生成摘要,提升用户体验。
对象
新闻机构和记者:快速发布新闻摘要,提高工作效率。
学者和研究人员:快速理解文献要点,节省阅读时间。
企业员工:管理和处理大量业务文档。
法律专业人员:高效处理和分析法律文件。
医疗专业人员:快速获取病历要点,提高诊疗效率。
内容平台运营者:为用户提供内容摘要,增加内容吸引力。
禁用场景
不得用于误导性摘要:禁止生成可能误导读者的摘要,如歪曲事实或夸大事实。
避免涉及敏感信息:在处理涉及个人隐私或敏感信息的文档时,必须遵守隐私保护法律法规。
禁止用于非法目的:不得将文本摘要用于任何非法或不道德的活动。文本摘要是自然语言处理(NLP)中的一个关键任务,目的是生成一个简短的文本段落,能够概括原始文本的主要内容。以下是文本摘要任务的算法规则简要说明:
1. 数据预处理
文本清洗:去除无关内容,如广告、非文本元素等。
分词和标准化:对文本进行分词处理,并统一格式。
2. 摘要类型
提取式摘要:从原文中选择关键句子或短语来形成摘要。
生成式摘要:基于原文内容生成新的、连贯的摘要文本。
3. 特征提取
关键词提取:识别文本中的关键词和短语。
语义理解:通过深度学习模型理解文本的主题和语境。
4. 模型训练
统计方法:基于词频、位置等统计信息进行提取式摘要。
深度学习方法:使用循环神经网络(RNN)、长短时记忆网络(LSTM)、变压器(Transformer)模型等进行生成式摘要。
5. 摘要生成
提取式:根据特征重要性选择并组合原文中的句子。
生成式:使用语言模型生成连贯且概括性的新文本。
6. 后处理和优化
长度控制:根据需求调整摘要的长度。
质量控制:检查摘要的连贯性和准确性,确保其忠实于原文。
7. 评估
人工评估:通过人工阅读来评估摘要的质量。
自动评估指标:使用ROUGE分数等指标评
Application Scenarios, Applicable Conditions and Scope
1. News Summarization: Automatically generate summaries from news articles to help readers quickly grasp the main content.
2. Academic Research: Generate summaries for long documents such as academic papers and reports to improve research efficiency.
3. Enterprise Document Management: Automatically extract key information from business documents including meeting minutes, reports, and emails.
4. Legal Document Processing: Generate summaries from legal documents such as case records and legal opinions.
5. Medical Record Summarization: Extract key information from medical records to enable doctors to quickly obtain patients' conditions.
6. Content Recommendation System: Generate summaries for articles, blogs or video content to enhance user experience.
Target Users
- News organizations and journalists: Quickly publish news summaries to improve work efficiency.
- Scholars and researchers: Quickly grasp the key points of literature and save reading time.
- Enterprise employees: Manage and process a large volume of business documents.
- Legal professionals: Efficiently process and analyze legal documents.
- Medical professionals: Quickly obtain key points of medical records to improve diagnosis and treatment efficiency.
- Content platform operators: Provide content summaries for users to increase content attractiveness.
Prohibited Scenarios
1. Misleading Summaries Are Prohibited: Generating summaries that mislead readers, such as distorting or exaggerating facts, is strictly forbidden.
2. Compliance with Privacy Regulations: When processing documents involving personal privacy or sensitive information, relevant privacy protection laws and regulations must be strictly followed.
3. Prohibited for Illegal or Unethical Use: Text summarization shall not be employed for any illegal or unethical activities.
Text summarization is a core task in natural language processing (NLP), which aims to generate a short text paragraph that summarizes the main content of the original text. The following is a brief explanation of the algorithmic rules for the text summarization task:
1. Data Preprocessing
- Text Cleaning: Remove irrelevant content such as advertisements and non-text elements.
- Tokenization and Standardization: Perform tokenization on the text and unify the format.
2. Summary Types
- Extractive Summarization: Select key sentences or phrases from the original text to form a summary.
- Abstractive Summarization: Generate new, coherent summary text based on the content of the original text.
3. Feature Extraction
- Keyword Extraction: Identify keywords and phrases in the text.
- Semantic Understanding: Understand the theme and context of the text through deep learning models.
4. Model Training
- Statistical Methods: Conduct extractive summarization based on statistical information such as word frequency and position.
- Deep Learning Methods: Use recurrent neural networks (RNN), long short-term memory networks (LSTM), Transformer models and other technologies for abstractive summarization.
5. Summary Generation
- Extractive Mode: Select and combine sentences from the original text according to feature importance.
- Abstractive Mode: Use language models to generate coherent and generalizable new text.
6. Post-processing and Optimization
- Length Control: Adjust the length of the summary as required.
- Quality Control: Check the coherence and accuracy of the summary to ensure it is faithful to the original text.
7. Evaluation
- Manual Evaluation: Evaluate the quality of the summary through manual reading.
- Automatic Evaluation Metrics: Use metrics such as ROUGE score for evaluation
提供机构:
杭州谦贞数字科技有限公司
创建时间:
2023-11-23
搜集汇总
数据集介绍
以上内容由遇见数据集搜集并总结生成


