red_pajama_es_hq
收藏Hugging Face2024-12-02 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/latam-gpt/red_pajama_es_hq
下载链接
链接失效反馈官方服务:
资源简介:
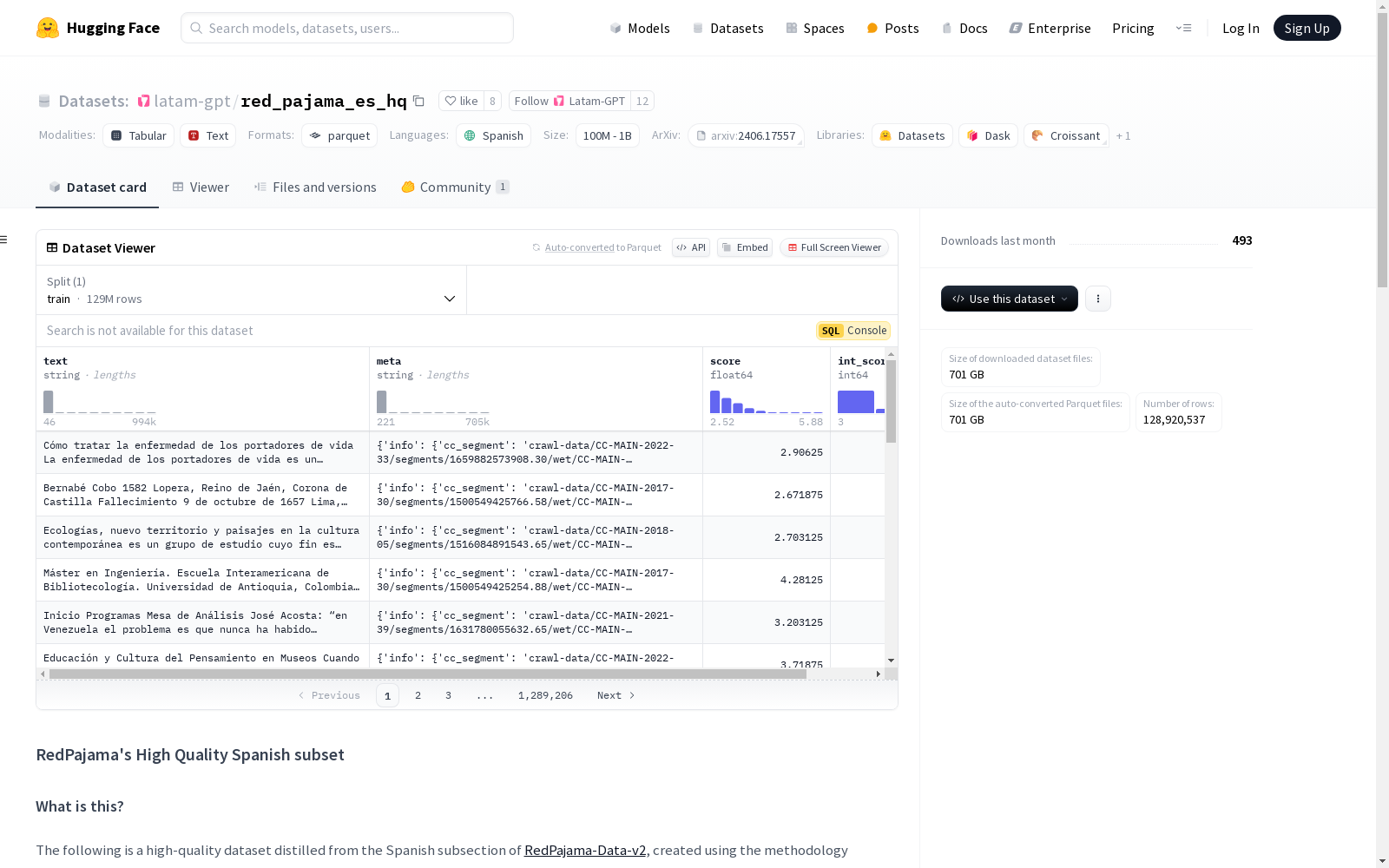
RedPajama-Data-v2的西班牙语子集的高质量版本,使用FineWEB-Edu方法创建。数据集包含文本、元数据、分数和整数分数四个特征,分为训练集。文档根据学术质量评分,分数范围为2.5到5,分数越高表示质量越好。数据集可以通过标准过滤方法按分数进行过滤。数据集的创建过程包括使用Llama-3.1-70B对原始数据集的550k样本进行评分,然后训练一个基于编码器的分类器,以学习从0到5的评分。该模型比GPT更经济,可以在整个数据集上运行,从而筛选出高质量的部分。
创建时间:
2024-11-19
原始信息汇总
RedPajamas High Quality Spanish subset
数据集概述
- 语言: 西班牙语 (es)
- 特征:
text: 文本数据,类型为字符串 (string)meta: 元数据,类型为字符串 (string)score: 质量评分,类型为浮点数 (float64)int_score: 整数评分,类型为整数 (int64)
- 分割:
train: 训练集,包含128,920,537个样本,大小为1,201,679,966,776字节
- 下载大小: 700,567,029,628字节
- 数据集大小: 1,201,679,966,776字节
- 配置:
default: 默认配置,数据文件路径为data/train-*
数据集创建
- 方法: 使用Llama-3.1-70B模型对原始数据集中的550k样本进行教育质量评分,并训练一个基于编码器的分类器,以分配0到5的评分。通过该模型对整个数据集进行评分和过滤,提取高质量部分。
- 详细信息: 更多关于数据集创建的详细信息,请参考我们的开源实现。
使用示例
python from datasets import load_dataset
ds = load_dataset("latam-gpt/red_pajama_es_hq")
过滤评分大于3的文档
filtered_ds = ds.filter(lambda x: x[score] > 3)
许可证
- 数据: 请参考Common Crawl Foundation Terms of Use。
- 代码: 使用Apache 2.0许可证。
搜集汇总
数据集介绍
构建方式
该数据集red_pajama_es_hq是从RedPajama-Data-v2的西班牙语子集中提炼出的高质量数据集,采用了FineWEB-Edu方法论进行构建。具体而言,研究团队利用Llama-3.1-70B模型对原始数据集中的550k样本进行学术质量评分,随后通过这些样本训练了一个基于编码器的分类器,该分类器能够为数据集中的文档分配0到5的评分。通过这种方式,研究团队能够对整个数据集进行大规模评分,从而筛选出高质量的子集。
使用方法
使用red_pajama_es_hq数据集时,用户可以通过HuggingFace的datasets库进行加载,并根据需要对数据进行过滤。例如,用户可以根据文档的评分进行筛选,选择评分高于特定值的文档。这种灵活的筛选机制使得该数据集在学术研究、语言模型训练等领域具有广泛的应用潜力。
背景与挑战
背景概述
RedPajama_es_hq数据集是基于RedPajama-Data-v2的西班牙语子集,通过FineWEB-Edu方法论精心提炼而成的高质量文本数据集。该数据集由Latam-GPT项目团队创建,旨在为拉丁美洲地区开发的大型语言模型提供高质量的训练数据。创建过程中,研究团队利用Llama-3.1-70B模型对原始数据集中的55万条样本进行了学术质量评分,并训练了一个基于编码器的分类器,以大规模筛选出高质量的文本。此数据集的构建不仅推动了拉丁美洲在自然语言处理领域的自主研发能力,还为全球西班牙语语言模型的训练提供了宝贵的资源。
当前挑战
RedPajama_es_hq数据集在构建过程中面临多项挑战。首先,如何从庞大的原始数据集中筛选出高质量的学术文本是一个复杂的问题,研究团队通过引入Llama-3.1-70B模型进行评分,并训练分类器来解决这一问题。其次,数据集的规模庞大,处理和存储这些数据需要高效的计算资源和存储解决方案。此外,数据集的版权和法律合规性也是一个重要挑战,尤其是在涉及多个司法管辖区的数据使用时,确保符合Common Crawl基金会的使用条款至关重要。最后,如何确保数据集在不同应用场景下的有效性和泛化能力,也是研究团队需要持续关注的问题。
常用场景
经典使用场景
RedPajama_es_hq数据集在西班牙语高质量文本的筛选与评估中展现了其经典应用场景。该数据集通过精细的质量评分机制,从原始的RedPajama-Data-v2西班牙语子集中提炼出高学术质量的文本,特别适用于构建高质量的西班牙语语言模型。研究者可通过设定质量评分阈值,筛选出符合特定学术标准的文本,从而优化模型的训练效果。
解决学术问题
RedPajama_es_hq数据集有效解决了在西班牙语自然语言处理领域中,高质量文本筛选与评估的难题。通过引入基于Llama-3.1-70B模型的评分机制,该数据集能够量化文本的学术质量,为研究者提供了一个标准化的评估工具。这不仅提升了西班牙语语言模型的训练质量,还为相关领域的学术研究提供了可靠的数据支持。
实际应用
在实际应用中,RedPajama_es_hq数据集广泛应用于西班牙语语言模型的开发与优化。例如,在教育领域,该数据集可用于构建智能辅导系统,提供高质量的西班牙语学习资源。此外,在新闻与出版行业,数据集的高质量文本筛选功能有助于生成更为准确和权威的内容,提升用户体验。
数据集最近研究
最新研究方向
在自然语言处理领域,RedPajama_es_hq数据集的最新研究方向主要集中在高质量西班牙语文本的筛选与应用上。该数据集通过Llama-3.1-70B模型对原始数据进行学术质量评分,并利用这些评分训练分类器,从而实现对大规模数据的高效过滤。这一方法不仅提升了数据集的质量,还为拉丁美洲地区的语言模型开发提供了坚实的基础。随着Latam-GPT项目的推进,该数据集的应用前景广阔,尤其是在教育领域的文本分析与生成任务中,其高质量的文本数据将为模型的性能提升提供重要支持。
以上内容由遇见数据集搜集并总结生成


