clue/clue
收藏Hugging Face2024-01-17 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/clue/clue
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators:
- other
language_creators:
- other
language:
- zh
license:
- unknown
multilinguality:
- monolingual
size_categories:
- 100K<n<1M
source_datasets:
- original
task_categories:
- text-classification
- multiple-choice
task_ids:
- topic-classification
- semantic-similarity-scoring
- natural-language-inference
- multiple-choice-qa
paperswithcode_id: clue
pretty_name: 'CLUE: Chinese Language Understanding Evaluation benchmark'
tags:
- coreference-nli
- qa-nli
dataset_info:
- config_name: afqmc
features:
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
- name: idx
dtype: int32
splits:
- name: test
num_bytes: 378718
num_examples: 3861
- name: train
num_bytes: 3396503
num_examples: 34334
- name: validation
num_bytes: 426285
num_examples: 4316
download_size: 2337418
dataset_size: 4201506
- config_name: c3
features:
- name: id
dtype: int32
- name: context
sequence: string
- name: question
dtype: string
- name: choice
sequence: string
- name: answer
dtype: string
splits:
- name: test
num_bytes: 1600142
num_examples: 1625
- name: train
num_bytes: 9672739
num_examples: 11869
- name: validation
num_bytes: 2990943
num_examples: 3816
download_size: 4718960
dataset_size: 14263824
- config_name: chid
features:
- name: idx
dtype: int32
- name: candidates
sequence: string
- name: content
sequence: string
- name: answers
sequence:
- name: text
dtype: string
- name: candidate_id
dtype: int32
splits:
- name: test
num_bytes: 11480435
num_examples: 3447
- name: train
num_bytes: 252477926
num_examples: 84709
- name: validation
num_bytes: 10117761
num_examples: 3218
download_size: 198468807
dataset_size: 274076122
- config_name: cluewsc2020
features:
- name: idx
dtype: int32
- name: text
dtype: string
- name: label
dtype:
class_label:
names:
'0': 'true'
'1': 'false'
- name: target
struct:
- name: span1_text
dtype: string
- name: span2_text
dtype: string
- name: span1_index
dtype: int32
- name: span2_index
dtype: int32
splits:
- name: test
num_bytes: 645637
num_examples: 2574
- name: train
num_bytes: 288816
num_examples: 1244
- name: validation
num_bytes: 72670
num_examples: 304
download_size: 380611
dataset_size: 1007123
- config_name: cmnli
features:
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': neutral
'1': entailment
'2': contradiction
- name: idx
dtype: int32
splits:
- name: test
num_bytes: 2386821
num_examples: 13880
- name: train
num_bytes: 67684989
num_examples: 391783
- name: validation
num_bytes: 2051829
num_examples: 12241
download_size: 54234919
dataset_size: 72123639
- config_name: cmrc2018
features:
- name: id
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: text
dtype: string
- name: answer_start
dtype: int32
splits:
- name: test
num_bytes: 3112042
num_examples: 2000
- name: train
num_bytes: 15508062
num_examples: 10142
- name: validation
num_bytes: 5183785
num_examples: 3219
- name: trial
num_bytes: 1606907
num_examples: 1002
download_size: 5459001
dataset_size: 25410796
- config_name: csl
features:
- name: idx
dtype: int32
- name: corpus_id
dtype: int32
- name: abst
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
- name: keyword
sequence: string
splits:
- name: test
num_bytes: 2463728
num_examples: 3000
- name: train
num_bytes: 16478890
num_examples: 20000
- name: validation
num_bytes: 2464563
num_examples: 3000
download_size: 3936111
dataset_size: 21407181
- config_name: diagnostics
features:
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': neutral
'1': entailment
'2': contradiction
- name: idx
dtype: int32
splits:
- name: test
num_bytes: 42392
num_examples: 514
download_size: 23000
dataset_size: 42392
- config_name: drcd
features:
- name: id
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: text
dtype: string
- name: answer_start
dtype: int32
splits:
- name: test
num_bytes: 4982378
num_examples: 3493
- name: train
num_bytes: 37443386
num_examples: 26936
- name: validation
num_bytes: 5222729
num_examples: 3524
download_size: 11188875
dataset_size: 47648493
- config_name: iflytek
features:
- name: sentence
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
'2': '2'
'3': '3'
'4': '4'
'5': '5'
'6': '6'
'7': '7'
'8': '8'
'9': '9'
'10': '10'
'11': '11'
'12': '12'
'13': '13'
'14': '14'
'15': '15'
'16': '16'
'17': '17'
'18': '18'
'19': '19'
'20': '20'
'21': '21'
'22': '22'
'23': '23'
'24': '24'
'25': '25'
'26': '26'
'27': '27'
'28': '28'
'29': '29'
'30': '30'
'31': '31'
'32': '32'
'33': '33'
'34': '34'
'35': '35'
'36': '36'
'37': '37'
'38': '38'
'39': '39'
'40': '40'
'41': '41'
'42': '42'
'43': '43'
'44': '44'
'45': '45'
'46': '46'
'47': '47'
'48': '48'
'49': '49'
'50': '50'
'51': '51'
'52': '52'
'53': '53'
'54': '54'
'55': '55'
'56': '56'
'57': '57'
'58': '58'
'59': '59'
'60': '60'
'61': '61'
'62': '62'
'63': '63'
'64': '64'
'65': '65'
'66': '66'
'67': '67'
'68': '68'
'69': '69'
'70': '70'
'71': '71'
'72': '72'
'73': '73'
'74': '74'
'75': '75'
'76': '76'
'77': '77'
'78': '78'
'79': '79'
'80': '80'
'81': '81'
'82': '82'
'83': '83'
'84': '84'
'85': '85'
'86': '86'
'87': '87'
'88': '88'
'89': '89'
'90': '90'
'91': '91'
'92': '92'
'93': '93'
'94': '94'
'95': '95'
'96': '96'
'97': '97'
'98': '98'
'99': '99'
'100': '100'
'101': '101'
'102': '102'
'103': '103'
'104': '104'
'105': '105'
'106': '106'
'107': '107'
'108': '108'
'109': '109'
'110': '110'
'111': '111'
'112': '112'
'113': '113'
'114': '114'
'115': '115'
'116': '116'
'117': '117'
'118': '118'
- name: idx
dtype: int32
splits:
- name: test
num_bytes: 2105684
num_examples: 2600
- name: train
num_bytes: 10028605
num_examples: 12133
- name: validation
num_bytes: 2157119
num_examples: 2599
download_size: 9777855
dataset_size: 14291408
- config_name: ocnli
features:
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': neutral
'1': entailment
'2': contradiction
- name: idx
dtype: int32
splits:
- name: test
num_bytes: 376058
num_examples: 3000
- name: train
num_bytes: 6187142
num_examples: 50437
- name: validation
num_bytes: 366227
num_examples: 2950
download_size: 3000218
dataset_size: 6929427
- config_name: tnews
features:
- name: sentence
dtype: string
- name: label
dtype:
class_label:
names:
'0': '100'
'1': '101'
'2': '102'
'3': '103'
'4': '104'
'5': '106'
'6': '107'
'7': '108'
'8': '109'
'9': '110'
'10': '112'
'11': '113'
'12': '114'
'13': '115'
'14': '116'
- name: idx
dtype: int32
splits:
- name: test
num_bytes: 810970
num_examples: 10000
- name: train
num_bytes: 4245677
num_examples: 53360
- name: validation
num_bytes: 797922
num_examples: 10000
download_size: 4697843
dataset_size: 5854569
configs:
- config_name: afqmc
data_files:
- split: test
path: afqmc/test-*
- split: train
path: afqmc/train-*
- split: validation
path: afqmc/validation-*
- config_name: c3
data_files:
- split: test
path: c3/test-*
- split: train
path: c3/train-*
- split: validation
path: c3/validation-*
- config_name: chid
data_files:
- split: test
path: chid/test-*
- split: train
path: chid/train-*
- split: validation
path: chid/validation-*
- config_name: cluewsc2020
data_files:
- split: test
path: cluewsc2020/test-*
- split: train
path: cluewsc2020/train-*
- split: validation
path: cluewsc2020/validation-*
- config_name: cmnli
data_files:
- split: test
path: cmnli/test-*
- split: train
path: cmnli/train-*
- split: validation
path: cmnli/validation-*
- config_name: cmrc2018
data_files:
- split: test
path: cmrc2018/test-*
- split: train
path: cmrc2018/train-*
- split: validation
path: cmrc2018/validation-*
- split: trial
path: cmrc2018/trial-*
- config_name: csl
data_files:
- split: test
path: csl/test-*
- split: train
path: csl/train-*
- split: validation
path: csl/validation-*
- config_name: diagnostics
data_files:
- split: test
path: diagnostics/test-*
- config_name: drcd
data_files:
- split: test
path: drcd/test-*
- split: train
path: drcd/train-*
- split: validation
path: drcd/validation-*
- config_name: iflytek
data_files:
- split: test
path: iflytek/test-*
- split: train
path: iflytek/train-*
- split: validation
path: iflytek/validation-*
- config_name: ocnli
data_files:
- split: test
path: ocnli/test-*
- split: train
path: ocnli/train-*
- split: validation
path: ocnli/validation-*
- config_name: tnews
data_files:
- split: test
path: tnews/test-*
- split: train
path: tnews/train-*
- split: validation
path: tnews/validation-*
---
# Dataset Card for "clue"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://www.cluebenchmarks.com
- **Repository:** https://github.com/CLUEbenchmark/CLUE
- **Paper:** [CLUE: A Chinese Language Understanding Evaluation Benchmark](https://aclanthology.org/2020.coling-main.419/)
- **Paper:** https://arxiv.org/abs/2004.05986
- **Point of Contact:** [Zhenzhong Lan](mailto:lanzhenzhong@westlake.edu.cn)
- **Size of downloaded dataset files:** 198.68 MB
- **Size of the generated dataset:** 486.34 MB
- **Total amount of disk used:** 685.02 MB
### Dataset Summary
CLUE, A Chinese Language Understanding Evaluation Benchmark
(https://www.cluebenchmarks.com/) is a collection of resources for training,
evaluating, and analyzing Chinese language understanding systems.
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Dataset Structure
### Data Instances
#### afqmc
- **Size of downloaded dataset files:** 1.20 MB
- **Size of the generated dataset:** 4.20 MB
- **Total amount of disk used:** 5.40 MB
An example of 'validation' looks as follows.
```
{
"idx": 0,
"label": 0,
"sentence1": "双十一花呗提额在哪",
"sentence2": "里可以提花呗额度"
}
```
#### c3
- **Size of downloaded dataset files:** 3.20 MB
- **Size of the generated dataset:** 15.69 MB
- **Total amount of disk used:** 18.90 MB
An example of 'train' looks as follows.
```
This example was too long and was cropped:
{
"answer": "比人的灵敏",
"choice": ["没有人的灵敏", "和人的差不多", "和人的一样好", "比人的灵敏"],
"context": "[\"许多动物的某些器官感觉特别灵敏,它们能比人类提前知道一些灾害事件的发生,例如,海洋中的水母能预报风暴,老鼠能事先躲避矿井崩塌或有害气体,等等。地震往往能使一些动物的某些感觉器官受到刺激而发生异常反应。如一个地区的重力发生变异,某些动物可能通过它们的平衡...",
"id": 1,
"question": "动物的器官感觉与人的相比有什么不同?"
}
```
#### chid
- **Size of downloaded dataset files:** 139.20 MB
- **Size of the generated dataset:** 274.08 MB
- **Total amount of disk used:** 413.28 MB
An example of 'train' looks as follows.
```
This example was too long and was cropped:
{
"answers": {
"candidate_id": [3, 5, 6, 1, 7, 4, 0],
"text": ["碌碌无为", "无所作为", "苦口婆心", "得过且过", "未雨绸缪", "软硬兼施", "传宗接代"]
},
"candidates": "[\"传宗接代\", \"得过且过\", \"咄咄逼人\", \"碌碌无为\", \"软硬兼施\", \"无所作为\", \"苦口婆心\", \"未雨绸缪\", \"和衷共济\", \"人老珠黄\"]...",
"content": "[\"谈到巴萨目前的成就,瓜迪奥拉用了“坚持”两个字来形容。自从上世纪90年代克鲁伊夫带队以来,巴萨就坚持每年都有拉玛西亚球员进入一队的传统。即便是范加尔时代,巴萨强力推出的“巴萨五鹰”德拉·佩纳、哈维、莫雷罗、罗杰·加西亚和贝拉乌桑几乎#idiom0000...",
"idx": 0
}
```
#### cluewsc2020
- **Size of downloaded dataset files:** 0.28 MB
- **Size of the generated dataset:** 1.03 MB
- **Total amount of disk used:** 1.29 MB
An example of 'train' looks as follows.
```
{
"idx": 0,
"label": 1,
"target": {
"span1_index": 3,
"span1_text": "伤口",
"span2_index": 27,
"span2_text": "它们"
},
"text": "裂开的伤口涂满尘土,里面有碎石子和木头刺,我小心翼翼把它们剔除出去。"
}
```
#### cmnli
- **Size of downloaded dataset files:** 31.40 MB
- **Size of the generated dataset:** 72.12 MB
- **Total amount of disk used:** 103.53 MB
An example of 'train' looks as follows.
```
{
"idx": 0,
"label": 0,
"sentence1": "从概念上讲,奶油略读有两个基本维度-产品和地理。",
"sentence2": "产品和地理位置是使奶油撇油起作用的原因。"
}
```
### Data Fields
The data fields are the same among all splits.
#### afqmc
- `sentence1`: a `string` feature.
- `sentence2`: a `string` feature.
- `label`: a classification label, with possible values including `0` (0), `1` (1).
- `idx`: a `int32` feature.
#### c3
- `id`: a `int32` feature.
- `context`: a `list` of `string` features.
- `question`: a `string` feature.
- `choice`: a `list` of `string` features.
- `answer`: a `string` feature.
#### chid
- `idx`: a `int32` feature.
- `candidates`: a `list` of `string` features.
- `content`: a `list` of `string` features.
- `answers`: a dictionary feature containing:
- `text`: a `string` feature.
- `candidate_id`: a `int32` feature.
#### cluewsc2020
- `idx`: a `int32` feature.
- `text`: a `string` feature.
- `label`: a classification label, with possible values including `true` (0), `false` (1).
- `span1_text`: a `string` feature.
- `span2_text`: a `string` feature.
- `span1_index`: a `int32` feature.
- `span2_index`: a `int32` feature.
#### cmnli
- `sentence1`: a `string` feature.
- `sentence2`: a `string` feature.
- `label`: a classification label, with possible values including `neutral` (0), `entailment` (1), `contradiction` (2).
- `idx`: a `int32` feature.
### Data Splits
| name |train |validation|test |
|-----------|-----:|---------:|----:|
|afqmc | 34334| 4316| 3861|
|c3 | 11869| 3816| 3892|
|chid | 84709| 3218| 3231|
|cluewsc2020| 1244| 304| 290|
|cmnli |391783| 12241|13880|
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Citation Information
```
@inproceedings{xu-etal-2020-clue,
title = "{CLUE}: A {C}hinese Language Understanding Evaluation Benchmark",
author = "Xu, Liang and
Hu, Hai and
Zhang, Xuanwei and
Li, Lu and
Cao, Chenjie and
Li, Yudong and
Xu, Yechen and
Sun, Kai and
Yu, Dian and
Yu, Cong and
Tian, Yin and
Dong, Qianqian and
Liu, Weitang and
Shi, Bo and
Cui, Yiming and
Li, Junyi and
Zeng, Jun and
Wang, Rongzhao and
Xie, Weijian and
Li, Yanting and
Patterson, Yina and
Tian, Zuoyu and
Zhang, Yiwen and
Zhou, He and
Liu, Shaoweihua and
Zhao, Zhe and
Zhao, Qipeng and
Yue, Cong and
Zhang, Xinrui and
Yang, Zhengliang and
Richardson, Kyle and
Lan, Zhenzhong",
booktitle = "Proceedings of the 28th International Conference on Computational Linguistics",
month = dec,
year = "2020",
address = "Barcelona, Spain (Online)",
publisher = "International Committee on Computational Linguistics",
url = "https://aclanthology.org/2020.coling-main.419",
doi = "10.18653/v1/2020.coling-main.419",
pages = "4762--4772",
}
```
### Contributions
Thanks to [@thomwolf](https://github.com/thomwolf), [@JetRunner](https://github.com/JetRunner) for adding this dataset.
CLUE, A Chinese Language Understanding Evaluation Benchmark, is a collection of resources for training, evaluating, and analyzing Chinese language understanding systems. It includes multiple configurations such as afqmc, c3, chid, cluewsc2020, cmnli, cmrc2018, csl, diagnostics, drcd, iflytek, ocnli, and tnews. Each configuration has different features and tasks, including text classification, multiple-choice, topic classification, semantic similarity scoring, natural language inference, and multiple-choice question answering. The dataset is monolingual in Chinese and covers a size range of 100K<n<1M examples. The source data is original, and the annotations are categorized as other. The license for the dataset is unknown.
提供机构:
clue
原始信息汇总
数据集概述
基本信息
- 数据集名称: CLUE: Chinese Language Understanding Evaluation benchmark
- 语言: 中文
- 许可证: 未知
- 多语言性: 单语种
- 数据集大小: 100K<n<1M
- 源数据: 原始数据
- 任务类别: 文本分类、多项选择
- 任务ID: 主题分类、语义相似度评分、自然语言推理、多项选择问答
- 标签创建者: 其他
- 语言创建者: 其他
数据集配置
afqmc
- 特征:
sentence1: 字符串sentence2: 字符串label: 分类标签,可能值为0和1idx: 整数
- 分割:
test: 3861个样本,378718字节train: 34334个样本,3396503字节validation: 4316个样本,426285字节
- 下载大小: 2337418字节
- 数据集大小: 4201506字节
c3
- 特征:
id: 整数context: 字符串序列question: 字符串choice: 字符串序列answer: 字符串
- 分割:
test: 1625个样本,1600142字节train: 11869个样本,9672739字节validation: 3816个样本,2990943字节
- 下载大小: 4718960字节
- 数据集大小: 14263824字节
chid
- 特征:
idx: 整数candidates: 字符串序列content: 字符串序列answers: 包含text和candidate_id的字典
- 分割:
test: 3447个样本,11480435字节train: 84709个样本,252477926字节validation: 3218个样本,10117761字节
- 下载大小: 198468807字节
- 数据集大小: 274076122字节
cluewsc2020
- 特征:
idx: 整数text: 字符串label: 分类标签,可能值为true和falsetarget: 包含span1_text,span2_text,span1_index,span2_index的字典
- 分割:
test: 2574个样本,645637字节train: 1244个样本,288816字节validation: 304个样本,72670字节
- 下载大小: 380611字节
- 数据集大小: 1007123字节
cmnli
- 特征:
sentence1: 字符串sentence2: 字符串label: 分类标签,可能值为neutral,entailment,contradictionidx: 整数
- 分割:
test: 13880个样本,2386821字节train: 391783个样本,67684989字节validation: 12241个样本,2051829字节
- 下载大小: 54234919字节
- 数据集大小: 72123639字节
cmrc2018
- 特征:
id: 字符串context: 字符串question: 字符串answers: 包含text和answer_start的字典
- 分割:
test: 2000个样本,3112042字节train: 10142个样本,15508062字节validation: 3219个样本,5183785字节trial: 1002个样本,1606907字节
- 下载大小: 5459001字节
- 数据集大小: 25410796字节
csl
- 特征:
idx: 整数corpus_id: 整数abst: 字符串label: 分类标签,可能值为0和1keyword: 字符串序列
- 分割:
test: 3000个样本,2463728字节train: 20000个样本,16478890字节validation: 3000个样本,2464563字节
- 下载大小: 3936111字节
- 数据集大小: 21407181字节
diagnostics
- 特征:
sentence1: 字符串sentence2: 字符串label: 分类标签,可能值为neutral,entailment,contradictionidx: 整数
- 分割:
test: 514个样本,42392字节
- 下载大小: 23000字节
- 数据集大小: 42392字节
drcd
- 特征:
id: 字符串context: 字符串question: 字符串answers: 包含text和answer_start的字典
- 分割:
test: 3493个样本,4982378字节train: 26936个样本,37443386字节validation: 3524个样本,5222729字节
- 下载大小: 11188875字节
- 数据集大小: 47648493字节
iflytek
- 特征:
sentence: 字符串label: 分类标签,可能值为0到118idx: 整数
- 分割:
test: 2600个样本,2105684字节train: 12133个样本,10028605字节validation: 2599个样本,2157119字节
- 下载大小: 9777855字节
- 数据集大小: 14291408字节
ocnli
- 特征:
sentence1: 字符串sentence2: 字符串label: 分类标签,可能值为neutral,entailment,contradictionidx: 整数
- 分割:
test: 3000个样本,376058字节train: 50437个样本,6187142字节validation: 2950个样本,366227字节
- 下载大小: 3000218字节
- 数据集大小: 6929427字节
tnews
- 特征:
sentence: 字符串label: 分类标签,可能值为100到116idx: 整数
- 分割:
test: 10000个样本,810970字节train: 53360个样本,4245677字节validation: 10000个样本,797922字节
- 下载大小: 4697843字节
- 数据集大小: 5854569字节
搜集汇总
数据集介绍
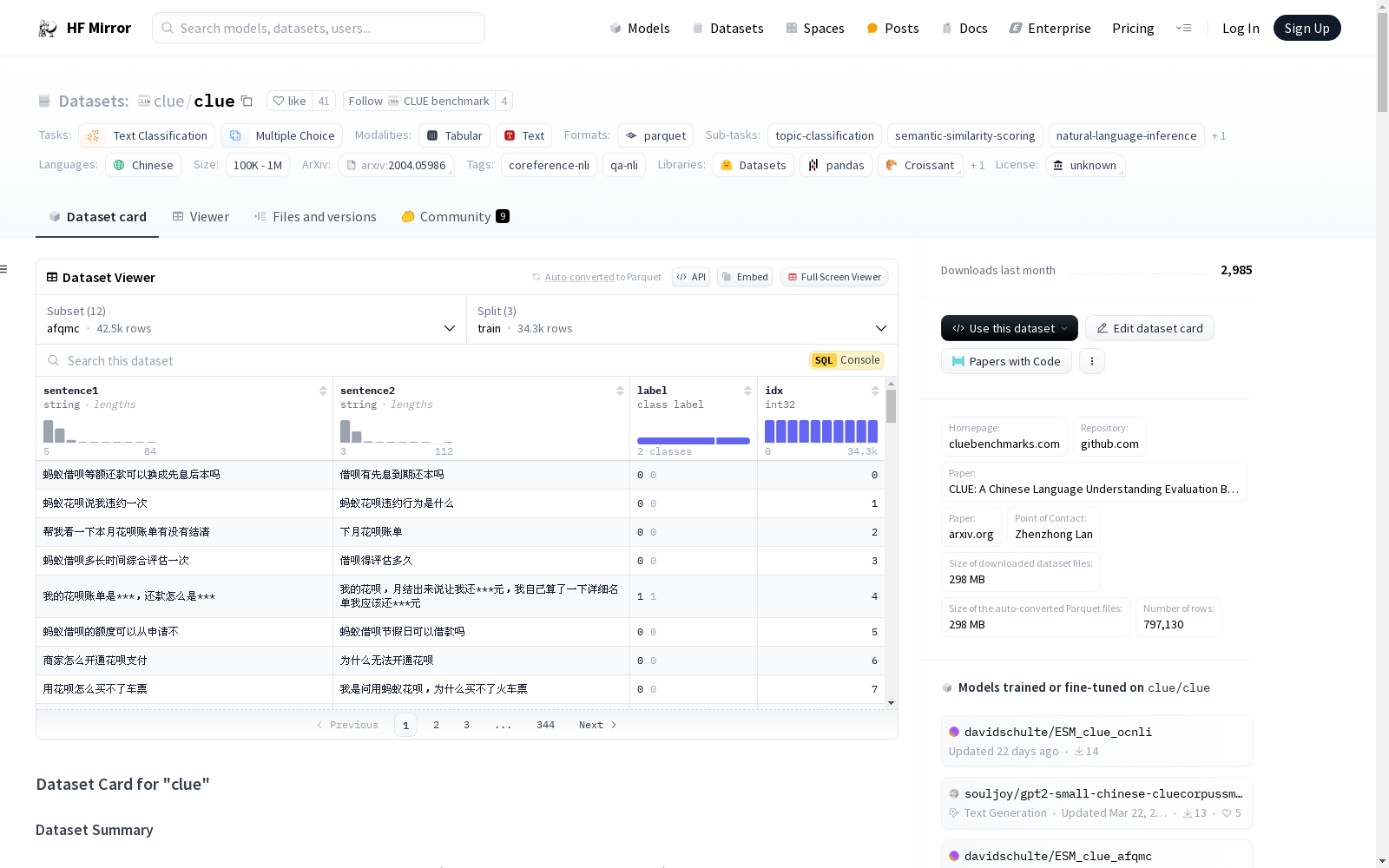
构建方式
CLUE数据集的构建基于对中国语言理解系统的全面评估需求,涵盖了多个子任务,包括文本分类、多项选择和自然语言推理等。数据集的构建过程涉及从原始数据中提取和标注信息,确保每个子任务的数据集具有高质量的标注和清晰的结构。通过这种方式,CLUE旨在为研究人员提供一个标准化的基准,以评估和比较不同模型的性能。
特点
CLUE数据集的一个显著特点是其多样性和全面性,涵盖了从简单的文本分类到复杂的自然语言推理等多个任务。此外,数据集的规模适中,包含超过10万条数据,足以支持深度学习模型的训练和验证。每个子任务的数据集都经过精心设计,以确保其在实际应用中的代表性和有效性。
使用方法
使用CLUE数据集时,研究人员可以根据具体的研究目标选择合适的子任务数据集。数据集提供了详细的文档和示例代码,帮助用户快速上手。用户可以通过加载数据集、定义模型架构和训练模型来评估其性能。此外,CLUE还提供了在线评估工具,允许用户在训练完成后立即查看模型在基准测试中的表现。
背景与挑战
背景概述
CLUE(Chinese Language Understanding Evaluation benchmark)是由中国的一组研究人员和机构创建的,旨在评估和提升中文自然语言理解系统的性能。该数据集于2020年发布,主要研究人员包括Xu Liang等人,其核心研究问题涵盖了文本分类、多选题、语义相似性评分、自然语言推理等多个领域。CLUE的推出极大地推动了中文自然语言处理领域的发展,为研究人员提供了一个标准化的评估平台,促进了相关技术的进步。
当前挑战
CLUE数据集在构建过程中面临了多重挑战。首先,中文语言的复杂性和多样性使得数据标注和处理变得尤为困难。其次,数据集的多样性要求涵盖多种任务类型,如文本分类、多选题等,这增加了数据集的复杂性和构建难度。此外,数据集的规模和质量也是一大挑战,如何在保证数据质量的同时扩大数据集的规模,是研究人员需要解决的重要问题。这些挑战不仅影响了数据集的构建过程,也对后续的研究和应用提出了更高的要求。
常用场景
经典使用场景
在自然语言处理领域,CLUE数据集被广泛应用于中文语言理解系统的评估与训练。其经典使用场景包括文本分类、语义相似度评分、自然语言推理以及多项选择问答等任务。通过这些任务,研究者能够全面评估和提升模型在中文文本理解方面的性能。
衍生相关工作
基于CLUE数据集,研究者们开展了多项经典工作,包括但不限于中文预训练语言模型的改进、跨领域任务的迁移学习以及多任务学习的研究。这些工作不仅提升了模型的泛化能力和效率,还为中文自然语言处理领域的发展提供了新的思路和方法。
数据集最近研究
最新研究方向
近年来,CLUE数据集在中文自然语言处理领域引起了广泛关注,其前沿研究方向主要集中在多任务学习与模型泛化能力的提升。研究者们通过整合CLUE中的多种任务数据,探索如何在单一模型架构下实现高效的多任务处理,从而提升模型在不同任务间的迁移能力和泛化性能。此外,随着预训练语言模型在中文领域的深入应用,如何利用CLUE数据集进行模型微调与优化,以适应特定任务的需求,也成为研究的热点。这些研究不仅推动了中文自然语言处理技术的发展,也为实际应用中的模型部署提供了更为坚实的基础。
以上内容由遇见数据集搜集并总结生成


