monte-inc/tau2-banking-eval-results
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/monte-inc/tau2-banking-eval-results
下载链接
链接失效反馈官方服务:
资源简介:
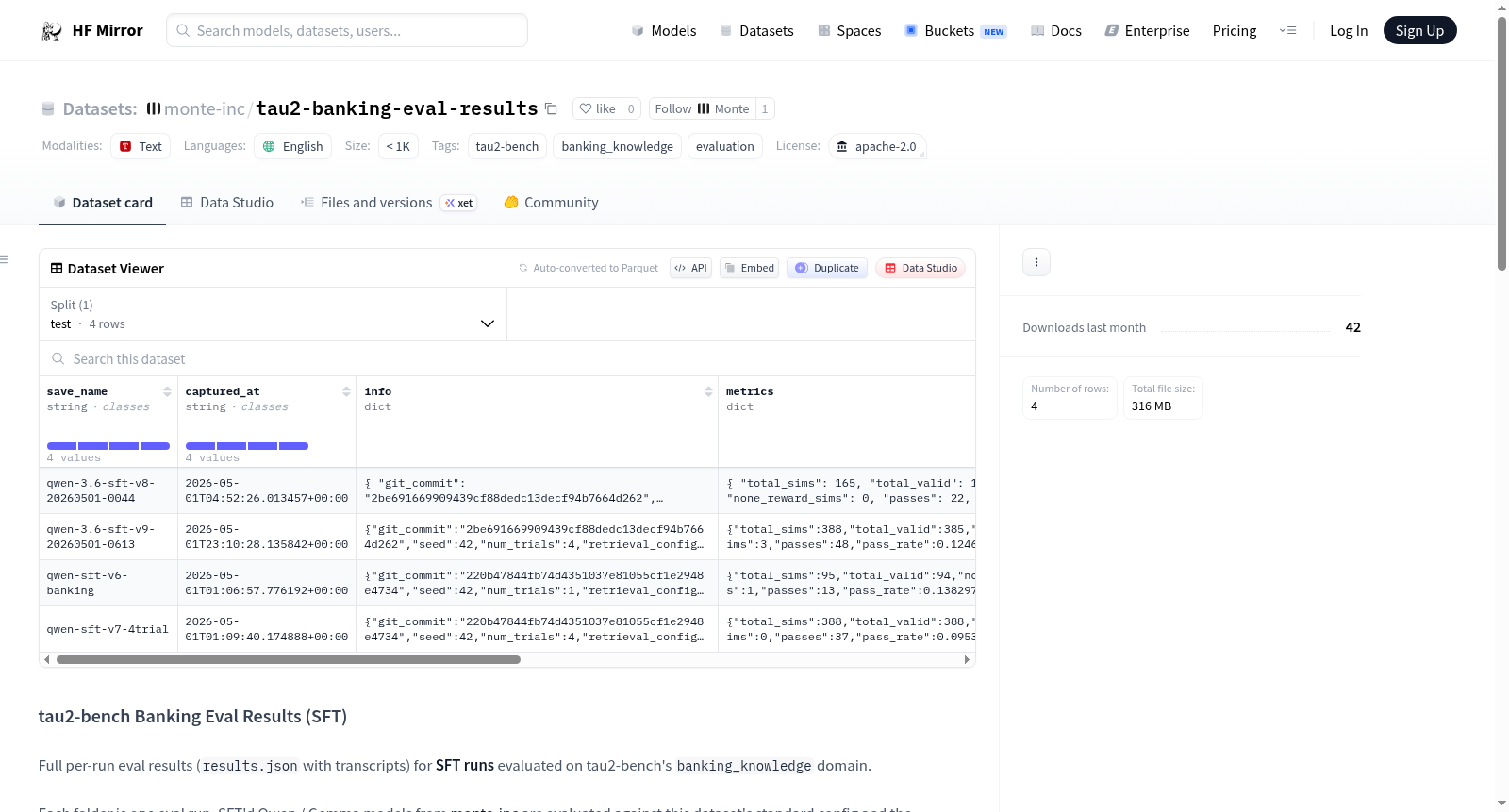
该数据集存储了在tau2-bench的banking_knowledge领域上进行的SFT(监督微调)运行的完整评估结果。每个文件夹代表一个评估运行,包含results.json(完整模拟结果)、eval_summary.json(紧凑的每任务摘要)和serving_config.json(评估时的vLLM服务快照)。数据集的标准配置包括领域为banking_knowledge,检索方式为terminal_use,用户模拟器为gpt-5.2,代理温度为0.0,最大步数为200,试验次数为4,种子为42。数据集由monte-inc/demo-tau2-banking-sft生成并通过scripts/publish_eval_results.py推送。
This dataset contains full evaluation results for SFT (Supervised Fine-Tuning) runs on the banking_knowledge domain of tau2-bench. Each folder represents one evaluation run, containing results.json (full simulation results), eval_summary.json (compact per-task summary), and serving_config.json (vLLM serving snapshot at eval time). The standard configuration includes Domain as banking_knowledge, Retrieval as terminal_use, User simulator as gpt-5.2, Agent temperature as 0.0, Max steps as 200, Trials as 4, and Seed as 42. The dataset is generated by monte-inc/demo-tau2-banking-sft and pushed via scripts/publish_eval_results.py.
提供机构:
monte-inc
搜集汇总
数据集介绍
构建方式
该数据集聚焦于tau2-bench框架下银行知识领域的监督微调模型评估,收录了来自monte-inc的Qwen与Gemma系列模型在标准配置下的完整逐轮评估结果。每个评估运行均以独立文件夹形式组织,内部包含完整的仿真记录(results.json),涵盖任务级对话转录、奖励信息、数据库检验与行动检查等细粒度数据。同时附有紧凑的评估摘要与vLLM服务快照配置,确保评估过程的透明性与可复现性。数据集的构建依托于demo-tau2-banking-sft仓库中的自动化脚本,通过标准化的评估管线统一生成并发布。
特点
该数据集最显著的特征在于其结构化的逐轮评估机制,每个运行文件夹均存放着一张事实来源文件results.json,可忠实还原模型在银行知识问答场景中的完整交互过程。评估配置采用统一参数,包括用户模拟器选用gpt-5.2(早期版本为gpt-4.1)、智能体温度设为0.0、最大步数200步,以及基于随机种子42的四次试验方案。此外,数据集还提供了与基线模型结果(tau2-banking-baselines)及历史存档版本(tau2-banking-archived)的清晰对比路径,便于研究者进行多维度分析。
使用方法
使用者可通过huggingface_hub库的hf_hub_download函数便捷地获取任意运行文件夹下的results.json文件。加载后,即可解析其中的模拟结果列表,提取每次任务的奖励信号,进而计算通过率等核心评估指标。例如,通过遍历仿真记录中的reward_info字段,筛选出奖励值大于等于1.0的任务,即可得到模型的成功率。此外,数据集中的eval_summary.json提供了无对话转录的紧凑摘要,适用于快速概览;而serving_config.json则记录了模型服务时的精确配置,有助于复现评估环境。
背景与挑战
背景概述
在金融领域,大语言模型(LLMs)的应用日益广泛,尤其是在银行知识问答与自动化客服场景中,模型不仅需要准确理解复杂业务逻辑,还需具备可靠的工具调用与信息检索能力。tau2-banking-eval-results数据集由Monte Inc.团队于2025年创建,专注于评估监督微调(SFT)后的Qwen、Gemma等模型在tau2-bench的banking_knowledge领域上的表现。该数据集以标准化配置(包括固定用户模拟器gpt-5.2、最大步数200及多次试验)生成详细的仿真交互记录,涵盖任务成功与否、成本及动作检查等关键指标。作为tau2-banking评估系列的核心部分,它为对比SFT模型与基线模型、理解不同训练策略对金融NLP任务的影响提供了可复现的基准,推动了面向垂直领域的LLM评估方法论发展。
当前挑战
该数据集所解决的领域问题聚焦于银行知识场景下的复杂任务评估,其挑战在于用户问题常涉及多步骤推理、实时数据检索与动作序列决策,传统单一指标难以刻画模型的实际执行能力。同时,构建过程中面临诸多技术难点:一是需要设计高度逼真的用户模拟器(gpt-5.2)以生成多样化、符合银行业务逻辑的交互路径;二是必须确保不同运行间评估结果的公平可比性,需严格控制服务配置、随机种子及试验次数;三是仿真日志的存储与解析需兼顾完整性与效率,包含的对话记录、奖励信息及动作检查项必须支持多维度的细粒度分析,这对数据结构和可复现性提出了严苛要求。
常用场景
经典使用场景
在金融领域的大语言模型对齐研究中,tau2-banking-eval-results数据集作为监督微调(SFT)模型评估的标准基准,被广泛用于衡量模型在银行知识领域的任务执行能力。研究者通过解析results.json中存储的完整仿真对话记录、奖励信号及状态检查数据,计算任务通过率、对话轮次成本等关键指标,从而定量评估不同SFT策略对模型金融专业服务能力的提升效果。该数据集特别适用于对比不同规模基座模型(如Qwen与Gemma系列)在统一配置下的表现差异,为选择最优金融领域对话模型提供可复现的评估框架。
实际应用
在实际金融科技部署中,该数据集支持的评估框架直接服务于智能客服系统的质量监控与迭代优化。金融机构可利用results.json中的任务级对话记录,自动检测模型在处理账户查询、交易验证、产品咨询等银行知识任务时是否产生合规性错误(如提供不准确利率或违反隐私政策),从而在模型上线前筛选出高可靠性的SFT模型。此外,评估成本数据(token消耗、调用次数)帮助预算有限的创业团队在模型性能与推理开销之间做出权衡决策。
衍生相关工作
该数据集衍生出的代表性工作包括基于tau2-banking-baselines的非SFT基线对比分析,揭示了基础模型在金融领域与经过指令微调模型之间的性能鸿沟。tau2-banking-archived数据集则记录了GPT-4.1模拟器时代的评估历史,为研究用户模拟器升级(从4.1到5.2)对模型排名稳定性的影响提供了纵向对比依据。monte-inc团队同步发布的demo-tau2-banking-sft代码库更将评估配置与数据生成流程开源,使得后续工作可以低成本复现扩展实验,例如探索不同检索增强策略与SFT模型的协同效果。
以上内容由遇见数据集搜集并总结生成


