资源简介:
---
annotations_creators:
- crowdsourced
language_creators:
- crowdsourced
language:
- en
license:
- unknown
multilinguality:
- monolingual
size_categories:
- 100K<n<1M
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- text-scoring
- sentiment-scoring
pretty_name: AppReviews
dataset_info:
features:
- name: package_name
dtype: string
- name: review
dtype: string
- name: date
dtype: string
- name: star
dtype: int8
splits:
- name: train
num_bytes: 32768731
num_examples: 288065
download_size: 13207727
dataset_size: 32768731
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for [Dataset Name]
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [Home Page](https://github.com/sealuzh/user_quality)
- **Repository:** [Repo Link](https://github.com/sealuzh/user_quality)
- **Paper:** [Link](https://giograno.me/assets/pdf/workshop/wama17.pdf)
- **Leaderboard:
- **Point of Contact:** [Darshan Gandhi](darshangandhi1151@gmail.com)
### Dataset Summary
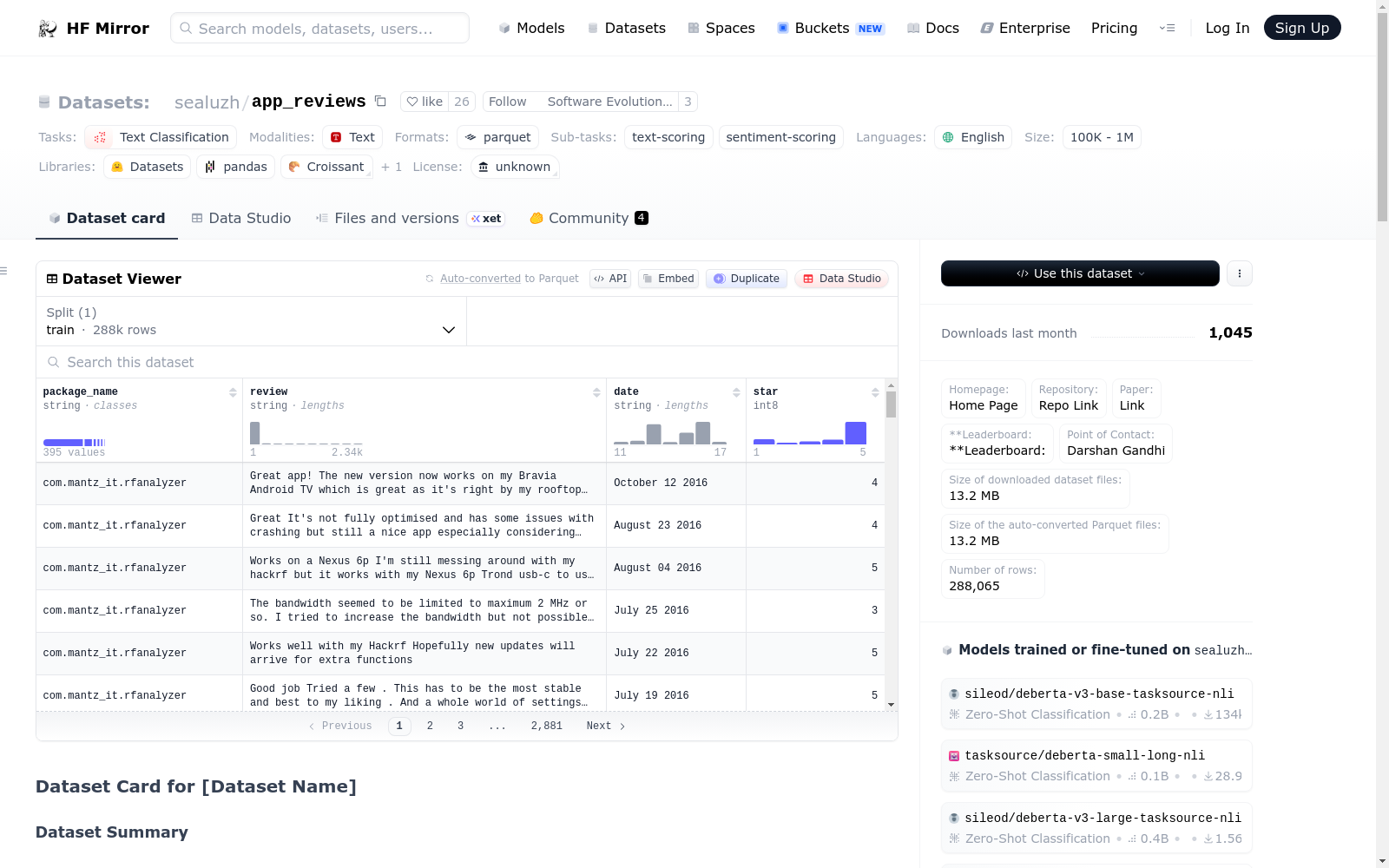
It is a large dataset of Android applications belonging to 23 differentapps categories, which provides an overview of the types of feedback users report on the apps and documents the evolution of the related code metrics. The dataset contains about 395 applications of the F-Droid repository, including around 600 versions, 280,000 user reviews (extracted with specific text mining approaches)
### Supported Tasks and Leaderboards
The dataset we provide comprises 395 different apps from F-Droid repository, including code quality indicators of 629 versions of these
apps. It also encloses app reviews related to each of these versions, which have been automatically categorized classifying types of user feedback from a software maintenance and evolution perspective.
### Languages
The dataset is a monolingual dataset which has the messages English.
## Dataset Structure
### Data Instances
The dataset consists of a message in English.
{'package_name': 'com.mantz_it.rfanalyzer',
'review': "Great app! The new version now works on my Bravia Android TV which is great as it's right by my rooftop aerial cable. The scan feature would be useful...any ETA on when this will be available? Also the option to import a list of bookmarks e.g. from a simple properties file would be useful.",
'date': 'October 12 2016',
'star': 4}
### Data Fields
* package_name : Name of the Software Application Package
* review : Message of the user
* date : date when the user posted the review
* star : rating provied by the user for the application
### Data Splits
There is training data, with a total of : 288065
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
With the help of this dataset one can try to understand more about software applications and what are the views and opinions of the users about them. This helps to understand more about which type of software applications are prefeered by the users and how do these applications facilitate the user to help them solve their problems and issues.
### Discussion of Biases
The reviews are only for applications which are in the open-source software applications, the other sectors have not been considered here
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
Giovanni Grano - (University of Zurich), Sebastiano Panichella - (University of Zurich), Andrea di Sorbo - (University of Sannio)
### Licensing Information
[More Information Needed]
### Citation Information
@InProceedings{Zurich Open Repository and
Archive:dataset,
title = {Software Applications User Reviews},
authors={Grano, Giovanni; Di Sorbo, Andrea; Mercaldo, Francesco; Visaggio, Corrado A; Canfora, Gerardo;
Panichella, Sebastiano},
year={2017}
}
### Contributions
Thanks to [@darshan-gandhi](https://github.com/darshan-gandhi) for adding this dataset.
annotations_creators:
- 众包
language_creators:
- 众包
language:
- 英语
license:
- 未知
multilinguality:
- 单语言
size_categories:
- 100K<n<1M
source_datasets:
- 原创
task_categories:
- 文本分类
task_ids:
- 文本评分
- 情感评分
pretty_name: AppReviews
dataset_info:
features:
- name: package_name
dtype: string
- name: review
dtype: string
- name: date
dtype: string
- name: star
dtype: int8
splits:
- name: train
num_bytes: 32768731
num_examples: 288065
download_size: 13207727
dataset_size: 32768731
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# AppReviews数据集卡片
## 目录
- [数据集描述](#dataset-description)
- [数据集摘要](#dataset-summary)
- [支持任务与排行榜](#supported-tasks-and-leaderboards)
- [语言](#languages)
- [数据集结构](#dataset-structure)
- [数据实例](#data-instances)
- [数据字段](#data-fields)
- [数据划分](#data-splits)
- [数据集构建](#dataset-creation)
- [遴选依据](#curation-rationale)
- [源数据](#source-data)
- [标注信息](#annotations)
- [个人与敏感信息](#personal-and-sensitive-information)
- [数据使用注意事项](#considerations-for-using-the-data)
- [数据集的社会影响](#social-impact-of-dataset)
- [偏差讨论](#discussion-of-biases)
- [其他已知局限性](#other-known-limitations)
- [附加信息](#additional-information)
- [数据集策展人](#dataset-curators)
- [许可信息](#licensing-information)
- [引用信息](#citation-information)
- [贡献者](#contributions)
## 数据集描述
- **主页:** [主页链接](https://github.com/sealuzh/user_quality)
- **仓库:** [代码仓库](https://github.com/sealuzh/user_quality)
- **论文:** [论文链接](https://giograno.me/assets/pdf/workshop/wama17.pdf)
- **排行榜:** 暂无
- **联系人:** [Darshan Gandhi](darshangandhi1151@gmail.com)
### 数据集摘要
本数据集为涵盖23个不同类别的安卓应用大型数据集,可全面展示用户针对各类应用反馈的类型,并记录相关代码度量指标的演化历程。数据集包含F-Droid仓库中的约395款应用(涵盖近600个版本),以及通过专属文本挖掘方法提取的28万条用户评论。
### 支持任务与排行榜
本数据集收录了F-Droid仓库中的395款应用,包含这些应用共计629个版本的代码质量指标;同时还包含与各版本相关的用户评论,这些评论已从软件维护与演化的视角出发,自动分类了用户反馈的类型。目前暂无对应排行榜。
### 语言
本数据集为单语言数据集,所有文本均为英语。
## 数据集结构
### 数据实例
数据集包含英文用户评论,典型数据实例如下:
python
{
'package_name': 'com.mantz_it.rfanalyzer',
'review': "超棒的应用!新版本如今可在我的索尼BRAVIA安卓电视上运行,这十分实用,因为它正好搭配我屋顶的天线线缆。扫描功能非常实用……请问该功能何时可正式上线?此外,支持从简单属性文件导入书签列表的功能也会很有帮助。",
'date': '2016年10月12日',
'star': 4
}
### 数据字段
* `package_name`:应用程序包名称
* `review`:用户评论内容
* `date`:用户发布评论的日期
* `star`:用户为应用给出的星级评分
### 数据划分
本数据集仅包含训练集,总样本量为288065条。
## 数据集构建
### 遴选依据
[需补充更多信息]
### 源数据
#### 初始数据收集与标准化
[需补充更多信息]
#### 源语言生产者是谁?
[需补充更多信息]
### 标注信息
#### 标注流程
[需补充更多信息]
#### 标注者是谁?
[需补充更多信息]
### 个人与敏感信息
[需补充更多信息]
## 数据使用注意事项
### 数据集的社会影响
借助本数据集,研究者可进一步探索软件应用的用户视角与评价,了解用户偏好的应用类型,以及应用如何帮助用户解决问题与痛点。
### 偏差讨论
本数据集的评论仅针对开源软件应用,未覆盖其他领域的应用。
### 其他已知局限性
[需补充更多信息]
## 附加信息
### 数据集策展人
Giovanni Grano(苏黎世大学)、Sebastiano Panichella(苏黎世大学)、Andrea di Sorbo(萨莫奈大学)
### 许可信息
[需补充更多信息]
### 引用信息
bibtex
@InProceedings{Zurich_Open_Repository_and_Archive:dataset,
title = {Software Applications User Reviews},
authors={Grano, Giovanni; Di Sorbo, Andrea; Mercaldo, Francesco; Visaggio, Corrado A; Canfora, Gerardo; Panichella, Sebastiano},
year={2017}
}
### 贡献者
感谢[@darshan-gandhi](https://github.com/darshan-gandhi) 添加本数据集。