BAREC-Shared-Task-2026-doc
收藏Hugging Face2026-05-17 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/CAMeL-Lab/BAREC-Shared-Task-2026-doc
下载链接
链接失效反馈官方服务:
资源简介:
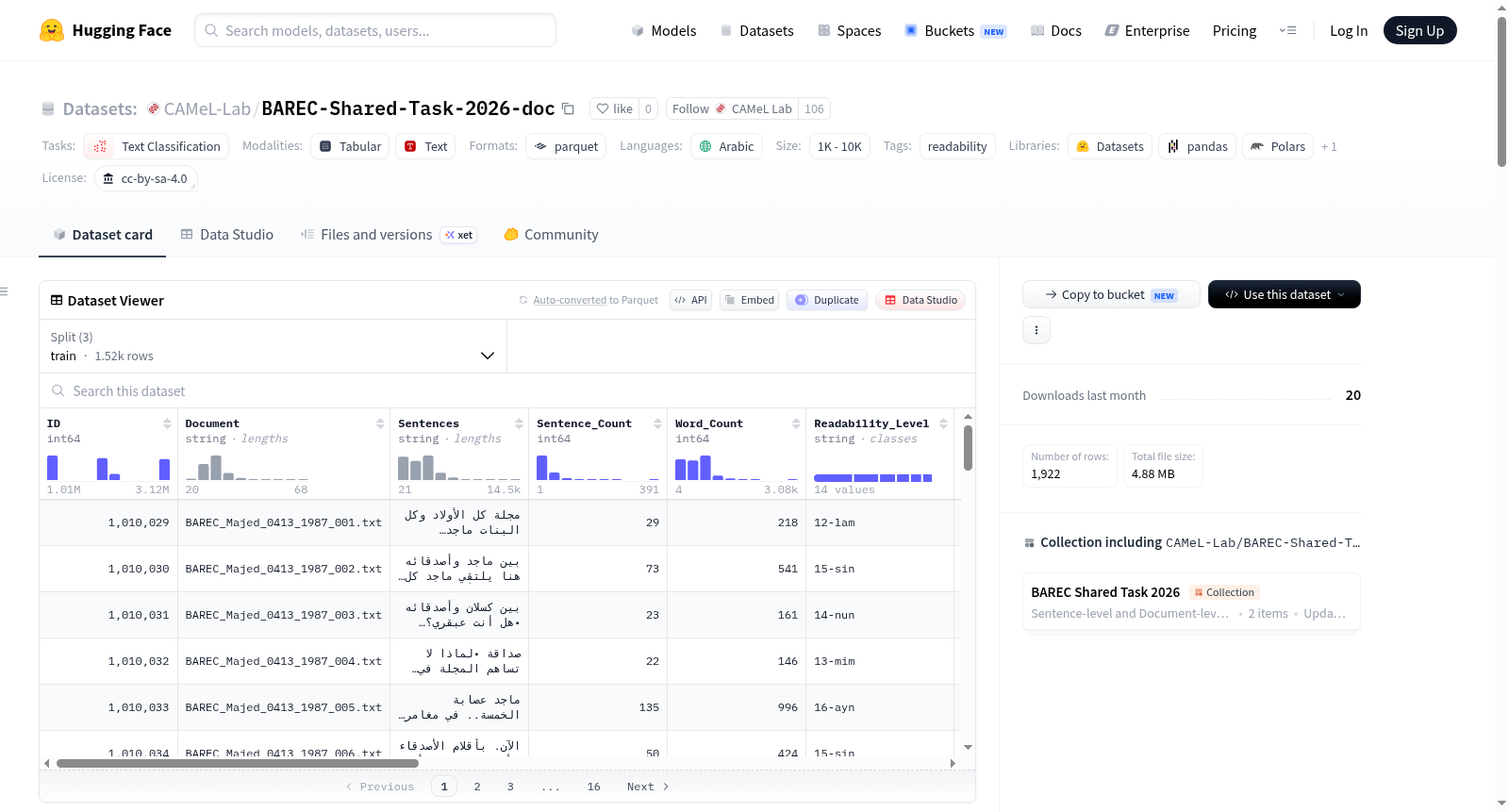
BAREC-ST-2026数据集是一个用于阿拉伯语细粒度可读性评估的大规模语料库,专为BAREC共享任务2026设计。该数据集包含超过100万词,在句子级别标注了19个可读性等级,并提供了映射到更粗粒度7级、5级和3级分类的方案。文档级别的可读性分数基于其最困难句子的19级可读性等级确定。数据集支持多类别可读性分类任务,涵盖19级、7级、5级和3级分类。数据实例包含ID、文档文件名、句子文本、句子数量、词数、各级可读性标签(如Readability_Level_19、Readability_Level_7等)、来源、书籍、作者、领域(如艺术与人文、STEM、社会科学)和文本类别(如基础、高级、专业)。数据集语言为现代标准阿拉伯语,按文档级别划分为训练集(80%)、开发集(10%)和测试集(10%),并在可读性等级、领域和文本类别上保持平衡。评估任务定义为序数分类,使用准确率(包括19级、7级、5级、3级准确率)、相邻准确率(±1准确率)、平均距离(平均绝对误差)和二次加权Kappa等指标。
The BAREC-ST-2026 dataset is a large-scale corpus for fine-grained readability assessment in Arabic, specifically designed for the BAREC shared task 2026. It contains over 1 million words, annotated at the sentence level with 19 readability grades, and provides mappings to coarser-grained 7-level, 5-level, and 3-level classifications. Document-level readability scores are determined based on the 19-level readability grade of their most difficult sentence. The dataset supports multi-category readability classification tasks, covering 19-level, 7-level, 5-level, and 3-level classifications. Data instances include ID, document filename, sentence text, sentence count, word count, readability labels at various levels (e.g., Readability_Level_19, Readability_Level_7, etc.), source, book, author, domain (such as Arts & Humanities, STEM, Social Sciences), and text category (e.g., basic, advanced, professional). The dataset language is Modern Standard Arabic, divided at the document level into training set (80%), development set (10%), and test set (10%), with balanced distributions across readability grades, domains, and text categories. The evaluation task is defined as ordinal classification, using metrics such as accuracy (including 19-level, 7-level, 5-level, 3-level accuracy), adjacent accuracy (±1 accuracy), average distance (mean absolute error), and quadratic weighted Kappa.
提供机构:
CAMeL Lab
创建时间:
2026-05-17
搜集汇总
数据集介绍
构建方式
BAREC-Shared-Task-2026-doc 数据集是专为阿拉伯语细粒度可读性评估共享任务而构建的大规模语料库。其构建基于句子级别的可读性标注,覆盖19个难度层级,并额外映射至7级、5级与3级粗粒度方案。文档层面的可读性等级通过赋予文档其内最难句子的等级来衍生,由此同时提供句子与文档两个维度的可读性信息。数据源涵盖多元领域与读者群体,最终形成包含超过百万词汇、标注精细且层次丰富的语料集合。
特点
该数据集最显著的特征在于其多粒度标签体系,支持从19级到3级的灵活分类任务,极大提升了跨研究场景的适用性。同时,数据集在文档层面进行了均衡划分,确保训练、开发与测试集在可读性等级、知识领域及文本类别上的分布一致。此外,数据集提供了丰富的元信息,包括来源、书籍、作者、领域和读者群体,为多维度的分析与鲁棒性建模奠定了坚实基础。
使用方法
数据集适用于序列级或文档级的多分类任务,研究者可直接利用19级标签进行细粒度可读性评估,亦可选择7级、5级或3级方案进行粗粒度分析。官方提供了全面的评估指标,包括精确匹配准确率、相邻准确率、平均绝对距离及二次加权卡帕系数,以序数分类的视角衡量模型性能。用户可通过加载提供的ID、完整句子文本及对应标签,快速构建并训练分类器,评估脚本亦已开源以供复现与比较。
背景与挑战
背景概述
BAREC(Balanced Arabic Readability Evaluation Corpus)是由CAMeL-Lab研究团队于2025年构建的大规模阿拉伯语可读性评估语料库,主要研究人员包括Khalid N. Elmadani、Nizar Habash和Hanada Taha-Thomure等。该数据集旨在解决阿拉伯语文本细粒度可读性评估这一核心研究问题,提供了超过100万词、覆盖19个可读性级别的精细标注,并支持映射至7级、5级和3级的更粗粒度方案。BAREC以句子级标注为特色,文档级可读性由其中最难的句子决定,这一设计为阿拉伯语教育、文本简化及信息检索等领域提供了重要基准。作为BAREC Shared Task 2026的官方数据集,它推动了多类别可读性分类任务的发展,对阿拉伯语自然语言处理领域具有深远影响力。
当前挑战
BAREC数据集所解决的领域挑战是阿拉伯语文本的可读性自动评估,这一任务面临语言本身的复杂性,如阿拉伯语丰富的形态变化、多样的书写风格以及缺乏统一的可读性标准。在构建过程中,挑战包括:1)设计一个既能反映阿拉伯语特性又具可操作性的19级标注体系,需兼顾文本难度与读者认知水平;2)确保语料库在可读性级别、文本领域和读者群体三个维度上的平衡分布,以避免模型偏向;3)在句子级标注中保持一致性,特别是处理多义句和文学性表达时的主观性差异;4)从多个来源(如宗教文本、文学著作、科普文章)收集并标准化的现代标准阿拉伯语语料,以覆盖不同难度的文本类型。
常用场景
经典使用场景
在阿拉伯语自然语言处理领域,BAREC数据集是细粒度可读性评估的基石资源。其最经典的使用场景是作为多层级分类任务的基准,支持19级、7级、5级和3级标签体系,研究者可基于此训练模型预测文本的复杂程度。由于数据集以句子级标注为核心,文档级标签通过最复杂句子确定,这为细粒度可读性研究提供了精确的粒度控制。常见任务包括构建序数分类器,以评估模型对阿拉伯语文本复杂梯度的理解能力,并利用其丰富的元数据(如领域、读众类别)探索可读性在不同上下文中的表现。数据集的平衡划分确保了跨层次和跨领域的泛化能力,使其成为评估算法鲁棒性的理想平台。
衍生相关工作
BAREC数据集的发布催生了一系列衍生研究方向。在可读性评估框架上,研究者基于其19级标签探索了对比学习与层次化分类模型,如设计损失函数以利用层级间的关系。跨语言迁移学习方面,它成为阿拉伯语可读性模型与英语等资源丰富语言对齐的桥梁,推动了多语言可读性研究。此外,数据集的细粒度特性激发了对序数分类评价指标的深入讨论,促使QWK和邻近准确度等标准在相关任务中普及。在应用端,BAREC启发了针对特定领域(如医疗或法律)的可读性子集构建,并激发了与文本生成模型的结合工作,例如利用大语言模型进行难度可控的文本改写与简化。
数据集最近研究
最新研究方向
BAREC-Shared-Task-2026-doc数据集聚焦于阿拉伯语文本的细粒度可读性评估,这一前沿研究方向与自然语言处理领域对低资源语言文本复杂度自动分级的需求紧密契合。鉴于阿拉伯语丰富的形态句法结构及其在不同学科、读者群体中的显著差异,该数据集通过涵盖19个精细可读性等级、并支持多层级标签映射(如3级、5级、7级),为多分类和有序回归任务提供了基准。其最大的突破在于为文本难度评估引入了基于句子级最困难句的文档级标注策略,并配套了跨学科(如人文学科、STEM)与跨读者群体(基础、高级、专业)的平衡划分,这在当前大语言模型时代尤为关键——它推动了针对阿拉伯语的可靠教育内容智能化适配、自适应学习系统以及信息可及性工具的研发,呼应了全球数字化转型中对语言公平与文本无障碍获取的热切关注,为阿拉伯语自然语言处理与教育技术的深度融合奠定了坚实的数据基石。
以上内容由遇见数据集搜集并总结生成


