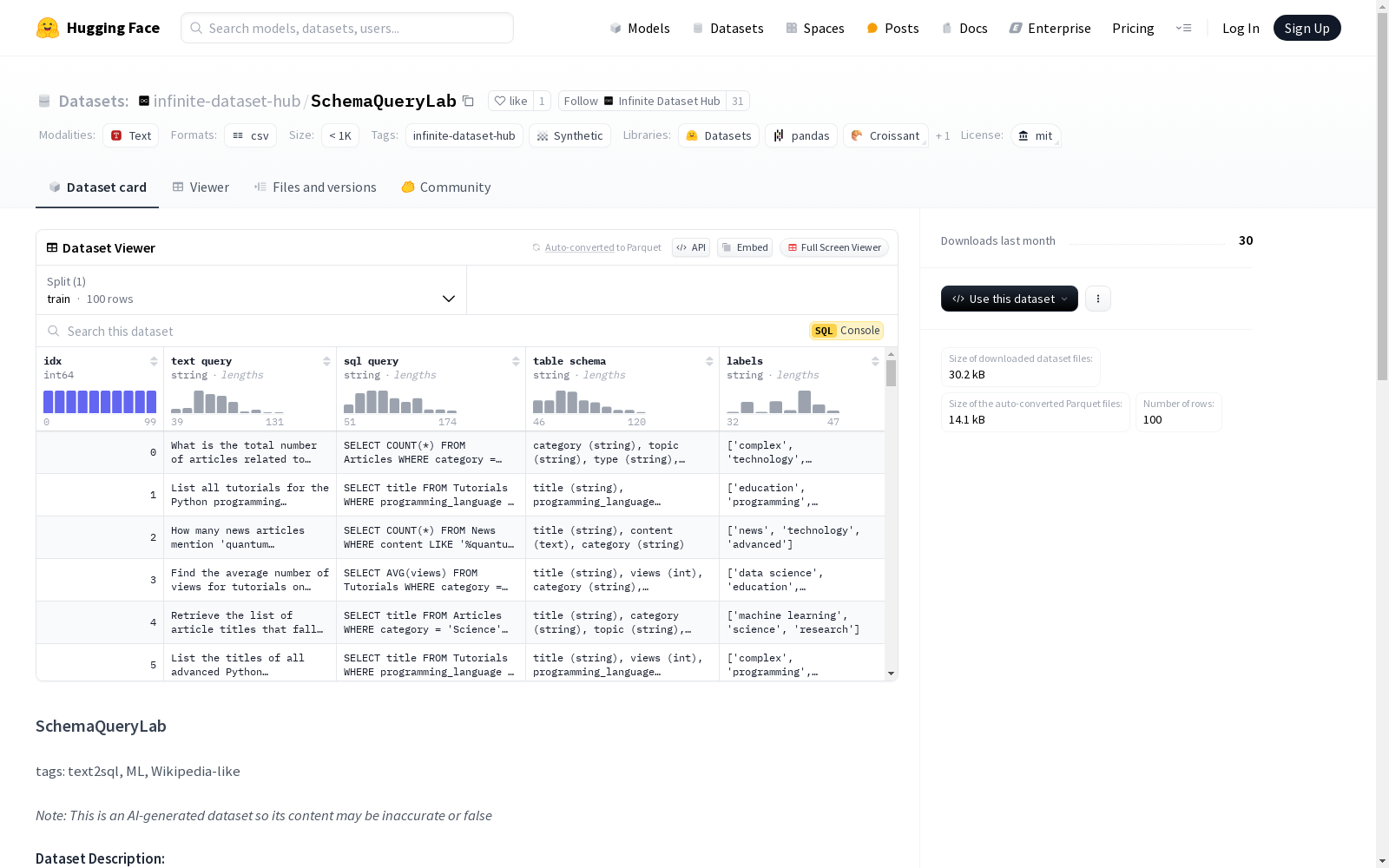
SchemaQueryLab
收藏SchemaQueryLab
数据集描述
SchemaQueryLab 数据集旨在支持机器学习模型的开发和训练,特别是专注于文本到SQL任务的模型。该数据集包含一系列维基百科风格的文章内容,这些内容被格式化为结构化数据集,包括文本查询、SQL查询和相应的表模式。每行数据代表一个独特的示例,其中自然语言文本查询被转换为精确的SQL查询,遵循详细的表模式。查询主要集中在过滤、统计分析和聚合操作上,涵盖科学、新闻、教程和技术等多个主题。
数据集根据查询的复杂性和领域进行细分,这些标签用于对查询进行分类,增强模型从不同主题和查询结构中泛化和学习的能力。
CSV内容预览
csv "text query","sql query","table schema","labels" "What is the total number of articles related to machine learning in the Science category?","SELECT COUNT() FROM Articles WHERE category = Science AND topic = Machine Learning;","category (string), topic (string), type (string), title (string), content (text)",["complex", "technology", "education"] "List all tutorials for the Python programming language.","SELECT title FROM Tutorials WHERE programming_language = Python;","title (string), programming_language (string), type (string), difficulty (string), category (string)",["education", "programming", "intermediate"] "How many news articles mention quantum computing?","SELECT COUNT() FROM News WHERE content LIKE %quantum computing%;","title (string), content (text), category (string)",["news", "technology", "advanced"] "Find the average number of views for tutorials on Data Science across all tutorials.","SELECT AVG(views) FROM Tutorials WHERE category = Data Science;","title (string), views (int), category (string), publication_date (date)",["data science", "education", "analytics"] "Retrieve the list of article titles that fall under Science and Machine Learning categories.","SELECT title FROM Articles WHERE category = Science AND topic = Machine Learning;","title (string), category (string), topic (string), content (text)",["machine learning", "science", "research"]
数据来源
该数据集由Infinite Dataset Hub和microsoft/Phi-3-mini-4k-instruct生成,使用查询text2sql dataset containing SQL schemas of text datasets as well as natural language text query and the actual SQL queries, specialized for text datasets used to train large language models, mostly SQL about filtering/stats/aggregates, the data consists of wikipedia-like articles, include columns "text query", "sql query", "table schema", data should be about various topics like science, news, tutorials, tech生成。