AnonyRAG
收藏Hugging Face2025-08-26 更新2025-08-28 收录
下载链接:
https://huggingface.co/datasets/Youtu-Graph/AnonyRAG
下载链接
链接失效反馈官方服务:
资源简介:
AnnoyRAG数据集是一个用于评估大型语言模型在图检索增强系统中信息整合能力的数据集。它包含了从四部经典小说中提取的简化和复杂问题,以及相应的答案。数据集分为中文和英文两个版本,每个版本都包含了问题、答案、知识图谱关系和实体的信息。此外,数据集还包含了经过匿名化处理的文本块,用于进一步的分析和评估。
The AnnoyRAG dataset is a benchmark dataset designed to evaluate the information integration capabilities of large language models (LLMs) in graph-based retrieval-augmented systems. It contains simplified and complex questions extracted from four classic novels, along with their corresponding reference answers. The dataset is available in both Chinese and English versions, and each version includes information on questions, answers, knowledge graph relations and entities. In addition, the dataset also provides anonymized text chunks for further analysis and evaluation.
创建时间:
2025-08-17
原始信息汇总
AnnoyRAG 数据集概述
数据集基本信息
- 许可证:CC-BY-NC-4.0
- 任务类别:问答
- 支持语言:英文、中文
- 标签:RAG、图、GraphRAG、小说、多语言
- 规模:1K<n<10K
数据集配置
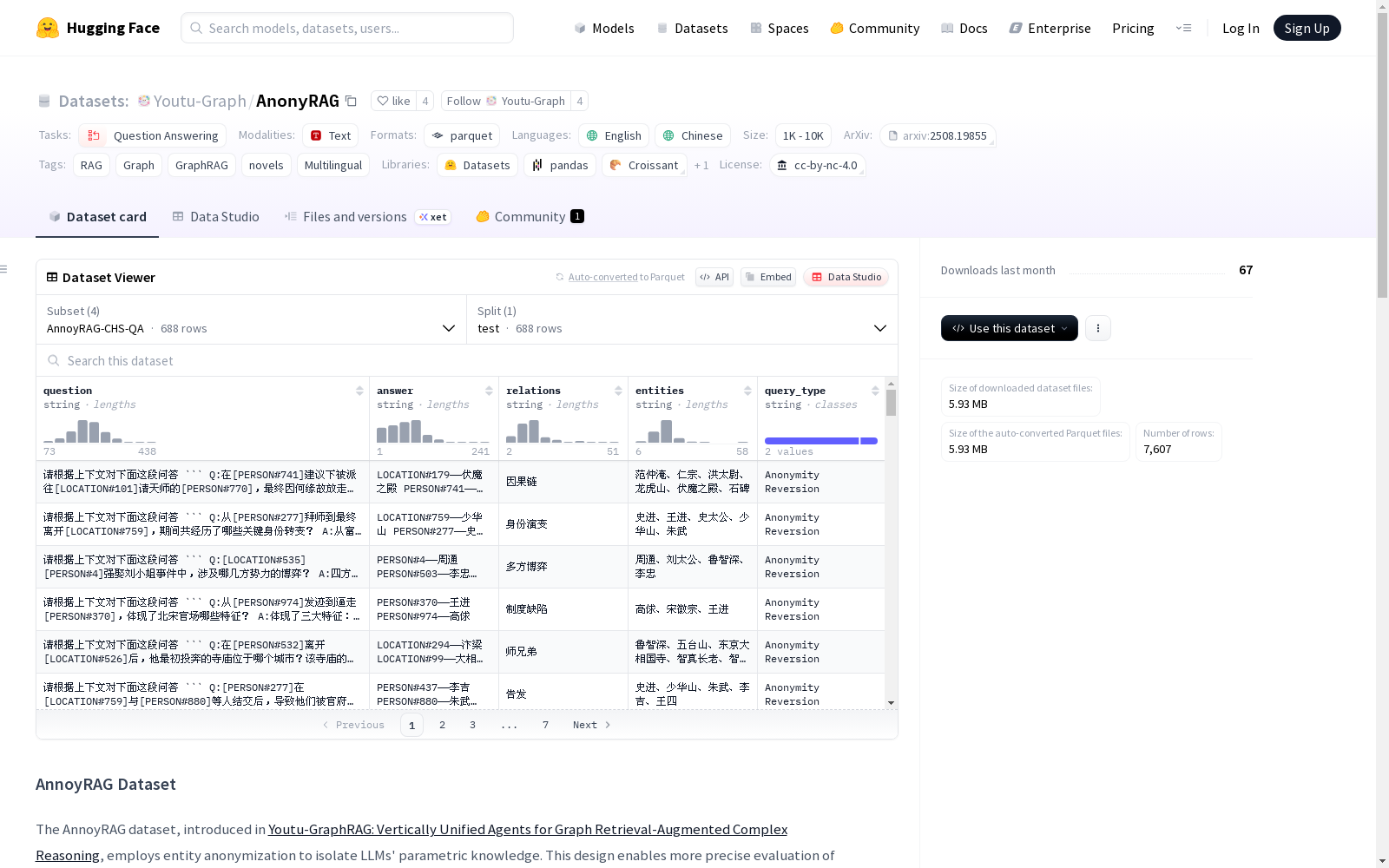
- AnnoyRAG-CHS-QA
- 数据文件:annoyrag_chs_qa.parquet
- 拆分:测试集
- AnnoyRAG-CHS-Texts
- 数据文件:annoyrag_chs_text_chunks.parquet
- 拆分:测试集
- AnnoyRAG-ENG-QA
- 数据文件:annoyrag_eng_qa.parquet
- 拆分:测试集
- AnnoyRAG-ENG-Texts
- 数据文件:annoyrag_eng_text_chunks.parquet
- 拆分:测试集
数据集描述
该数据集采用实体匿名化技术来隔离大语言模型的参数知识,旨在更精确地评估大语言模型在RAG系统中整合检索信息的效果。
数据统计
| 问题类型 | 难度级别 | 水浒传 | 红楼梦 | 白鲸记 | 米德尔马契 | 总计 |
|---|---|---|---|---|---|---|
| 客观题 | 简单(≤4跳) | 29 | 26 | 54 | 54 | 163 |
| 客观题 | 复杂(>4跳) | 24 | 34 | 51 | 22 | 131 |
| 主观题(匿名还原) | 简单(≤4跳) | 65 | 50 | 51 | 116 | 282 |
| 主观题(匿名还原) | 复杂(>4跳) | 146 | 314 | 142 | 219 | 821 |
| 总计 | - | 264 | 424 | 298 | 411 | 1397 |
数据来源
所有原始数据均来源于四部经典小说的原文:《水浒传》、《红楼梦》、《白鲸记》和《米德尔马契》,这些作品的版权均已进入公共领域。
数据结构
QA数据文件结构
- question:作为输入查询的问题,用于评估RAG能力
- answer:参考答案
- relations:潜在相关的知识图谱关系(仅供参考)
- entities:潜在相关的知识图谱实体(仅供参考)
- query_type:问题类型,包括选择题和去匿名化任务
文本块数据文件结构
- idx:用于排序的位置索引
- title:匿名化处理后的章节标题
- chunk:匿名化语料块,每段最大1000字符,连续块之间有100字符重叠以防止语义截断
生成信息
- 使用DeepSeek-V3-0324生成
引用信息
@misc{dong2025youtugraphragverticallyunifiedagents, title={Youtu-GraphRAG: Vertically Unified Agents for Graph Retrieval-Augmented Complex Reasoning}, author={Junnan Dong and Siyu An and Yifei Yu and Qian-Wen Zhang and Linhao Luo and Xiao Huang and Yunsheng Wu and Di Yin and Xing Sun}, year={2025}, eprint={2508.19855}, archivePrefix={arXiv}, primaryClass={cs.IR}, url={https://arxiv.org/abs/2508.19855}, }
搜集汇总
数据集介绍
构建方式
在知识图谱与检索增强生成技术交叉领域,AnonyRAG数据集基于四部经典小说原始文本构建,通过实体匿名化处理剥离语言模型的参数化知识。其构建过程采用垂直统一的图检索方法,将文本切分为最大1000字符的片段并设置100字符重叠区,确保语义连贯性。问题设计涵盖客观与主观类型,依据推理跳数划分简单与复杂难度,形成多维度评估体系。
特点
该数据集显著特点在于双语架构与实体匿名化机制,涵盖中英文双版本且均包含问答对与文本块两类数据。其问题类型兼具客观选择题与主观去匿名化任务,难度层级按推理跳数精细划分。知识图谱实体与关系字段为检索过程提供参考锚点,文本块采用重叠分块策略保持上下文完整性,形成对RAG系统知识整合能力的多角度测评框架。
使用方法
研究者可通过加载指定配置的parquet文件获取双语问答对或文本块数据,利用问题字段作为检索查询输入,结合附带的实体与关系信息构建知识图谱。评估时需将模型输出与标准答案对比,重点观测匿名实体还原与多跳推理的准确性。文本块数据可作为外部知识库用于检索实验,其重叠分块结构适用于测试文档切分策略对语义完整性的影响。
背景与挑战
背景概述
AnonyRAG数据集由研究团队于2025年提出,作为Youtu-GraphRAG项目的重要组成部分,专注于评估大语言模型在检索增强生成系统中的知识整合能力。该数据集基于四部经典文学作品构建,通过实体匿名化技术有效隔离模型参数知识,为多语言复杂推理任务提供精准评估基准。其创新性设计推动了图检索增强生成技术的发展,对自然语言处理领域的评估方法论产生重要影响。
当前挑战
该数据集致力于解决多跳问答和主观推理任务中的知识整合难题,特别是针对模型在匿名化语境下的信息还原能力。构建过程中面临双重挑战:一是需要精确设计不同跳数的复杂问题以测试模型推理深度,二是必须保持匿名化处理与原始文本语义的一致性,同时确保中英文版本间的跨语言等效性,这对知识图谱构建和文本分块策略提出了极高要求。
常用场景
经典使用场景
在检索增强生成系统评估领域,AnonyRAG数据集通过实体匿名化技术构建了多跳问答测试基准。该数据集基于四大经典文学作品构建知识图谱,要求模型在参数知识被隔离的情况下,仅依靠检索到的匿名化文本来完成客观题和主观题推理。这种设计能精确衡量大语言模型在RAG场景中整合外部知识的能力,特别适用于评估模型对长文本、多跳关系的复杂推理性能。
衍生相关工作
该数据集已催生多项重要研究,包括基于图神经网络的检索增强推理框架和跨语言知识融合方法。相关研究团队进一步开发了面向垂直领域的GraphRAG系统,实现了对复杂知识图谱的深度查询和理解。这些衍生工作推动了多模态RAG技术的发展,为构建更高效的知识检索与推理一体化系统奠定了坚实基础。
数据集最近研究
最新研究方向
在知识增强生成技术领域,AnonyRAG数据集通过实体匿名化机制有效隔离了大语言模型的参数化知识,为评估检索增强生成系统的信息整合能力提供了精准基准。该数据集支持中英双语跨文化叙事分析,其基于四大经典文学构建的多跳推理任务正推动图神经网络与检索增强生成的融合研究,特别是在复杂推理路径优化和跨语言知识对齐方面展现出重要价值。近期研究聚焦于如何利用该数据集提升模型对长文本深层语义的理解能力,以及探索匿名化策略对模型泛化性能的影响,为构建更可靠的垂直领域问答系统提供了关键数据支撑。
以上内容由遇见数据集搜集并总结生成


