FineSightBench
收藏Hugging Face2026-04-23 更新2026-04-24 收录
下载链接:
https://huggingface.co/datasets/Volavion/FineSightBench
下载链接
链接失效反馈官方服务:
资源简介:
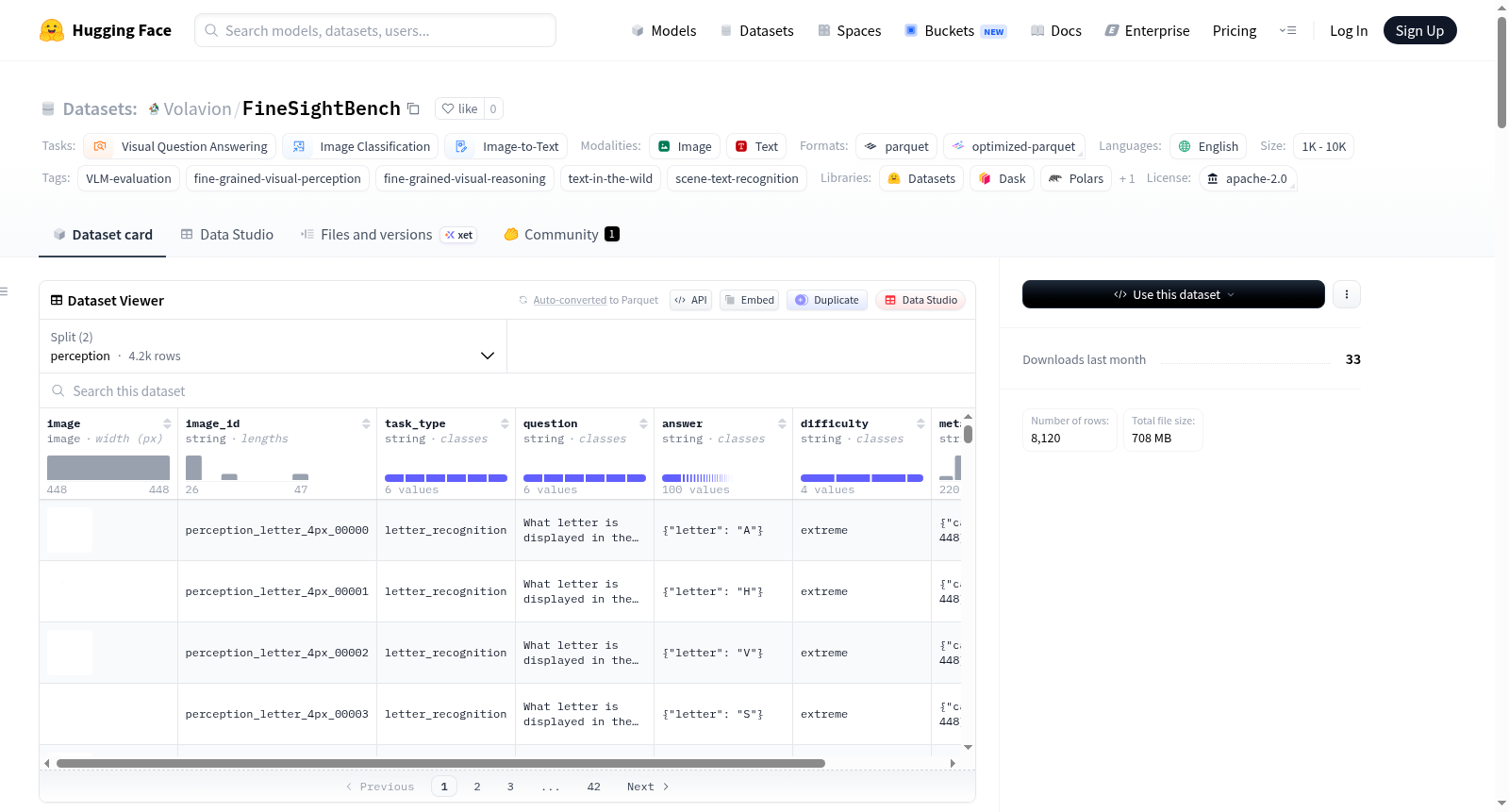
FineSightBench 是一个用于评估视觉-语言模型(VLMs)在像素级感知和推理任务上的细粒度视觉基准。数据集结合了两种互补的图像模式:1) 合成画布——具有精确尺寸的几何/语义目标(字母、动物、形状、块、点)的白色背景图像;2) 自然场景中的文本(SynthText风格)——将英文单词渲染到真实自然场景照片上,并精确控制字符的像素高度。所有图像均为448×448像素。主要难度轴是目标像素大小(文本的字符高度),分为极端/困难/中等/简单四个等级。数据集分为两个部分:感知(perception)和推理(reasoning),分别包含4,200和3,920个样本。每个样本包含图像、唯一标识符、任务类型、问题、答案、难度级别和元数据等字段。适用于视觉问答、图像分类和图像到文本等任务。
创建时间:
2026-04-22
原始信息汇总
数据集概述:FineSightBench
FineSightBench 是一个用于评估视觉语言模型(VLM)在像素级感知与推理任务上表现的细粒度视觉基准测试集。
基本信息
- 语言:英语
- 许可证:Apache-2.0
- 数据集大小:1K < n < 10K
- 图片尺寸:所有图片均为 448 × 448 像素
- 主要难度轴:目标像素尺寸(文本则为 cap-height),取值范围为 [4, 8, 12, 16, 24, 32, 48] 像素,对应
extreme / hard / medium / easy四个难度等级。
数据集划分
| 划分 | 样本数 | 任务类型数 | 图片来源 |
|---|---|---|---|
perception |
4,200 | 6 | 合成画布 + 自然场景文本 |
reasoning |
3,920 | 6 | 合成画布 + 自然场景文本 |
难度等级定义:
extreme:目标 ≤ 5 pxhard:目标 6–12 pxmedium:目标 13–24 pxeasy:目标 25–48 px
任务类型
perception 划分(6 种单目标识别任务,每种 700 样本,按 7 种像素尺寸各 100 样本):
| 任务类型 | 描述 | 来源 |
|---|---|---|
letter_recognition |
识别大写字母(A–Z) | 合成画布 |
animal_recognition |
识别动物剪影(猫/狗/鱼/鸟/兔/龟) | 合成画布 |
shape_recognition |
识别几何形状(圆/三角/方形/星形/菱形/五边形/六边形/十字) | 合成画布 |
block_recognition |
检测/计数方块 | 合成画布 |
color_block_recognition |
识别方块颜色 | 合成画布 |
text_recognition |
阅读自然场景图像上的单个英文单词 | 自然场景文本 |
reasoning 划分(6 种链式推理任务,需对多个目标进行计数、排序和空间推理):
| 任务类型 | 描述 | 来源 |
|---|---|---|
spatial_chain |
按从左到右或从上到下顺序列出所有物体 | 合成画布 |
comparison_chain |
按从小到大的尺寸顺序列出所有物体 | 合成画布 |
comparison_chain |
按从小到大的尺寸顺序列出所有物体 | 合成画布 |
counting_chain |
按类型计数并统计总数 | 合成画布 |
blur_chain |
在模糊/纹理背景上计数物体 | 合成画布 |
text_reading_chain |
按从左到右/从上到下顺序阅读多个叠加单词 | 自然场景文本 |
text_counting_chain |
总单词数 + 包含指定字母的单词数 | 自然场景文本 |
数据字段
| 字段 | 类型 | 描述 |
|---|---|---|
image |
Image | 448×448 PNG 图片 |
image_id |
string | 唯一标识符(编码了任务、尺寸、数量) |
task_type |
string | 任务类型(见上表) |
question |
string | 提供给 VLM 的提示(要求结构化 JSON 回答) |
answer |
string | 真实答案,JSON 编码 |
difficulty |
string | 难度等级:easy / medium / hard / extreme |
metadata |
string | JSON 格式的元数据,包含画布尺寸、目标像素尺寸、位置、颜色、边界框、子答案等 |
答案格式示例
| 任务 | 答案 JSON |
|---|---|
letter_recognition |
{"letter": "H"} |
animal_recognition |
{"animal": "rabbit"} |
shape_recognition |
{"shape": "triangle"} |
color_block_recognition |
{"color": "blue"} |
text_recognition |
{"word": "HOME"} |
spatial_chain |
{"objects": ["red A", "blue K", ...]} |
comparison_chain |
{"objects": ["blue dog", "magenta bird"]} |
counting_chain |
{"counts": {"red": 2, "blue": 1}, "total": 3} |
blur_chain |
{"counts": {"circle": 1, "square": 2}, "total": 3} |
text_reading_chain |
{"words": ["HOME", "CITY", "EXIT"]} |
text_counting_chain |
{"total": 6, "with_letter": 3} |
设计理念
- 以像素尺寸为主要难度轴:相同语义任务在不同缩放尺度下(从易于阅读到几乎不可见)进行探测。
- 受控构成:每个样本的元数据中包含像素精度的目标位置、边界框、颜色(含 RGB 值)及子答案,支持按任务、尺寸、颜色和位置的分析。
- 双图片体系:合成画布消除分布混淆因素;自然场景文本部分在真实照片上施加相同文本任务。
生成与引用
- 使用 FineSightBench 仓库 生成。
- 自然场景背景源自 SynthText
bg_img数据集(约前 1,500 张 JPEG,经过中心裁剪和缩放至 448×448)。
搜集汇总
数据集介绍
构建方式
FineSightBench的构建融合了合成画布与野外文本两种图像模态,旨在系统评估视觉语言模型在像素级感知与推理任务上的表现。合成画布部分在纯白背景上精确渲染具有特定像素尺寸的几何与语义目标,涵盖字母、动物轮廓、几何形状及色块等;野外文本部分则基于SynthText数据集中的自然场景图像,以像素级精度控制字符的cap-height。所有图像统一为448×448像素,目标像素尺寸在4至48像素之间变化,并映射至从“极端”到“容易”的困难等级。该数据集分为感知与推理两个子集,分别包含4200和3920个样本,每个样本均附有图像、问题、标准答案及包含精确边界框与位置信息的元数据。
特点
FineSightBench的核心特色在于以目标像素尺寸作为主要的困难度量轴,使得同一语义任务可在从清晰可辨到近乎不可感知的尺度上被系统性探测。其组合的两种图像模态各具优势:合成画布去除了自然场景中的分布混杂因素,实现了精细可控的组成分析;而野外文本模态则在真实照片上测试模型的泛化能力。数据集提供了精细的元数据,包括像素级精确的目标位置、边界框、RGB颜色及子答案,支持按任务类型、目标尺寸、颜色和位置等多维度分析。样本结构设计使得感知与推理任务互为补充,前者侧重单一目标识别,后者则要求模型进行计数、排序与空间推理等多步骤链式推理。
使用方法
FineSightBench可通过HuggingFace Datasets库便捷加载,使用`load_dataset('Volavion/FineSightBench')`即可获取包含感知与推理两个子集的数据集字典。用户可以通过`filter`方法按`task_type`或`difficulty`字段筛选特定任务类型或困难等级的样本,例如仅获取文本识别任务或极端困难级别的数据。每个样本的`question`字段提供了面向VLM的结构化提示,要求模型输出JSON格式的答案;`answer`字段包含与任务类型匹配的标准答案JSON,便于自动化评估。此外,`metadata`字段存储了丰富的辅助信息,可用于深入分析模型在不同视觉粒度下的表现模式。数据集生成代码开源,支持定制化的重新生成与扩展。
背景与挑战
背景概述
近年来,视觉-语言模型在多项复杂任务中展现出卓越能力,然而其在像素级细粒度感知与推理方面的局限性仍亟待深入探究。为系统评估此类模型的极限,FineSightBench数据集应运而生,由Volavion团队于2026年构建并发布。该数据集巧妙融合了合成画布与场景文本两种图像模态,通过精确控制目标的像素尺寸(从4像素至48像素),系统性地测试模型在不同难度层级下的视觉感知与链式推理能力。其核心研究问题聚焦于揭示当前视觉-语言模型在极端小目标识别、精细文本阅读以及多目标空间关系推理等维度上的真实表现,为模型性能的精细化诊断提供了标准化评测工具。
当前挑战
数据集所应对的核心领域挑战在于:现有视觉-语言模型往往在宏观语义理解上表现优异,却在微观像素层面的识别与推理上力有不逮,尤其在目标尺寸骤降至像素级时,模型往往丧失判别能力。FineSightBench通过7级像素尺寸梯度(4-48像素)与‘极端’至‘轻松’四档难度映射,精准刻画了这一性能退化规律。在构建层面,挑战在于同时保证两套图像生成管线的严谨可控:合成画布需精确控制几何元素的尺寸、位置与色彩;而场景文本部分则要求从SynthText的自然图像中精准叠加指定像素高度的字符,并确保渲染精度。此外,为支撑结构化评估,每张图像均需附带像素级标注的元数据(边界框、颜色、位置等),这进一步提升了数据生成的复杂性与精细化要求。
常用场景
经典使用场景
FineSightBench作为细粒度视觉感知与推理的基准测试集,其经典使用场景在于系统性地评估视觉语言模型(VLM)在像素级别上的感知与推理能力。该数据集通过两大数据子集——感知(perception)与推理(reasoning)——构成,前者聚焦于单一目标的识别任务,涵盖字母、动物、形状、方块、颜色块以及自然场景中的文字识别;后者则延伸至多目标情境下的计数、排序与空间推理。合成画布与真实场景文本两种模态的协同设计,使得研究人员能够在精确控制目标像素尺寸的前提下,精准剖析VLM在不同复杂度和尺度下的表现边界。
解决学术问题
该数据集巧妙地解决了当前视觉语言模型评估中普遍存在的两个学术困境:其一,现有基准多聚焦于粗粒度的语义理解,难以触及模型对微小目标或细节特征的感知极限;其二,缺乏对感知与推理两个维度的清晰切分与独立度量。FineSightBench通过将目标像素尺寸作为核心难度轴,从极难(≤5像素)到简单(25-48像素)逐级递进,揭示了模型在小目标感知、空间关系理解、多目标计数等关键能力上的真实瓶颈。这一设计为构建更具鲁棒性的视觉语言模型提供了高分辨率的能力剖面图,推动了细粒度视觉感知研究的发展。
衍生相关工作
FineSightBench的提出催生了一系列围绕细粒度视觉感知的延伸研究工作。受其设计理念启发,研究者们开始探索基于像素级难度递增的评估框架,并构建了面向特定领域(如医学影像、遥感图像)的细粒度感知基准。同时,该数据集对合成与真实双模态的并置,推动了模型在域适应与跨模态泛化能力上的研究,衍生出诸如基于难度的课程学习训练策略、针对小目标感知的注意力机制改进、以及面向多步推理的链式思维增强方法等经典工作。这些后续研究共同构成了一个不断完善的细粒度视觉理解研究体系,持续推动着视觉语言模型向更高精度与更强推理能力演进。
以上内容由遇见数据集搜集并总结生成


