Situated Reasoning in Real-World Videos (STAR)
收藏arXiv2024-05-16 更新2024-06-21 收录
下载链接:
http://star.csail.mit.edu
下载链接
链接失效反馈官方服务:
资源简介:
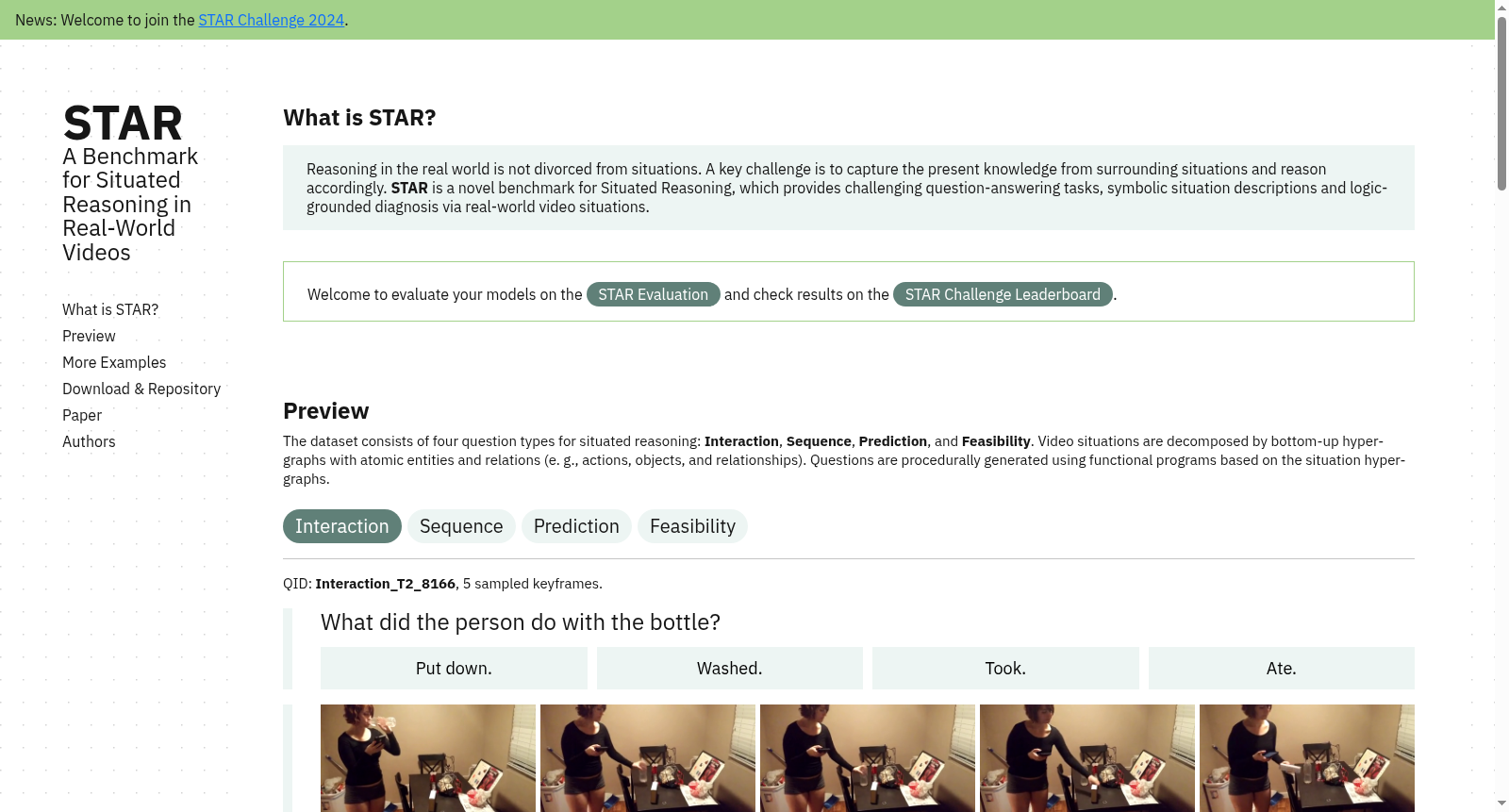
STAR数据集是由MIT-IBM Watson AI Lab创建的,专注于评估机器在真实世界视频中的情境推理能力。该数据集包含约60,000个情境推理问题,涉及交互、序列、预测和可行性四种类型的问题。数据集通过超图连接提取的原子实体和关系来表示真实世界视频中的情境,旨在通过程序生成的问题和答案来评估机器的推理能力。STAR数据集的应用领域包括人机交互、时间序列分析、动作预测和可行性推断,旨在解决机器在复杂情境中理解和推理的难题。
The STAR dataset was created by the MIT-IBM Watson AI Lab, focusing on evaluating the contextual reasoning capabilities of machines in real-world videos. It contains approximately 60,000 contextual reasoning questions across four types: interaction, sequence, prediction, and feasibility. The dataset represents contextual information in real-world videos by extracting atomic entities and relationships linked via hypergraphs, and it aims to evaluate machine reasoning performance using programmatically generated questions and answers. The applicable domains of the STAR dataset include human-computer interaction, time series analysis, action prediction, and feasibility inference, with the goal of addressing the challenges of machine understanding and reasoning in complex contexts.
提供机构:
MIT-IBM Watson AI Lab
创建时间:
2024-05-16
搜集汇总
数据集介绍
构建方式
在构建STAR数据集的过程中,研究团队以现实世界视频为基础,聚焦于人类日常活动场景。数据集的核心来源于Charades数据集中的动作标注视频,经过精心筛选与剪辑,确保视频内容清晰且无歧义。每个情境视频被抽象为超图结构,其中节点代表人物与物体,超边则捕捉动作及其内在关系。通过提取原子实体与关系,如动作、人物、物体及其交互,构建了层次化的情境表示。问题与答案通过程序化方式生成,基于情境超图设计功能程序,确保逻辑推理步骤的显式化。此外,团队还采用了去偏与平衡策略,以消除数据分布偏差,并通过人工标注验证了数据的合理性与一致性。
使用方法
使用STAR数据集时,研究者通常将其应用于评估模型在现实世界视频中的情境推理能力。数据集提供了训练、验证与测试划分,支持端到端的视频问答任务。模型需要接收视频输入与对应问题,并从四个候选答案中选择正确答案。研究过程中,可借助数据集提供的情境超图与功能程序,分析模型在视觉感知、情境抽象与逻辑推理各环节的表现。例如,通过对比神经符号模型与纯视觉语言模型的性能,可以深入探讨推理瓶颈所在。数据集还支持模块化评估,允许研究者分别考察视觉解析、语言理解或符号执行等组件的影响,从而推动更具解释性的推理模型发展。
背景与挑战
背景概述
STAR(Situated Reasoning in Real-World Videos)数据集由MIT-IBM Watson AI Lab、上海交通大学等机构的研究人员于2021年提出,旨在评估机器在真实世界视频中的情境推理能力。该数据集聚焦于人类日常活动视频,通过超图结构抽象动态情境中的实体与关系,并生成涵盖交互、序列、预测及可行性四类问题的程序化问答对。其核心研究问题在于推动机器从具体情境中抽取结构化知识并进行逻辑推理,弥补了现有视觉推理基准在真实世界复杂性与诊断性上的不足,为视频理解与推理研究提供了重要方向。
当前挑战
STAR数据集面临的挑战主要体现在领域问题与构建过程两方面。在领域问题上,其致力于解决真实世界视频中的情境推理,要求模型不仅进行视觉感知,还需完成情境抽象与逻辑推理,而现有方法多依赖视觉-语言关联而非深层推理,导致在预测、可行性等复杂任务上表现受限。构建过程中,挑战包括从真实视频中提取高质量情境表示时,需处理动态、组合及逻辑性结构,同时通过去偏与平衡策略避免数据分布偏差,并确保生成问答的语法正确性与合理性,这些因素共同增加了数据集的构建复杂度与评估难度。
常用场景
经典使用场景
在视觉推理研究领域,STAR数据集最经典的使用场景在于评估模型对真实世界动态情境的理解与逻辑推理能力。该数据集通过构建基于人类日常活动视频的情境超图,系统性地设计了交互、序列、预测及可行性四类问题,要求模型从动态视觉输入中抽取结构化知识,并执行符号化推理以回答问题。这一场景深刻反映了人类在复杂环境中进行实时决策的认知过程,为探索机器智能如何融合感知与推理提供了标准化测试平台。
解决学术问题
STAR数据集主要解决了视觉人工智能领域长期存在的若干关键学术问题。它突破了以往合成数据或静态图像在推理任务上的局限性,将情境抽象与逻辑推理紧密结合,首次在真实世界视频中实现了对动态、组合式逻辑关系的系统性评估。该数据集通过程序化生成的问题与答案,有效诊断了模型在视觉感知、结构化情境理解及符号推理等多维能力上的不足,尤其揭示了现有模型在预测与可行性推理等高级认知任务上的显著缺陷,为构建更接近人类水平的推理系统指明了方向。
实际应用
STAR数据集的实际应用场景广泛涉及需要深度情境理解与前瞻性推理的智能系统。在智能家居与服务机器人领域,系统可借助类似STAR的推理能力,理解人类行为意图并预测后续动作,从而提供主动式协助。在自动驾驶系统中,对交通参与者交互行为与可行性的推理至关重要。此外,在教育与培训模拟、视频内容分析以及人机交互界面设计等方面,能够进行情境化推理的模型可显著提升系统的适应性与决策合理性,推动人工智能从被动感知向主动认知的跨越。
数据集最近研究
最新研究方向
在视频理解与人工智能领域,STAR数据集正推动着情境推理研究的前沿探索。该数据集通过构建真实世界视频中的情境超图,将视觉感知与符号化逻辑推理紧密结合,为模型理解动态、组合且富有逻辑的人类日常活动提供了结构化基准。当前研究热点聚焦于神经符号架构的深度融合,旨在解决视觉感知、情境抽象与逻辑推理的协同挑战。模型需超越传统的视觉问答范式,实现对交互、序列、预测及可行性四类问题的显式推理。这一方向不仅揭示了现有模型在真实情境下的推理瓶颈,也为构建更具人类认知灵活性的智能系统指明了路径,对自动驾驶、人机交互等现实应用具有深远意义。
相关研究论文
- 1STAR: A Benchmark for Situated Reasoning in Real-World VideosMIT-IBM Watson AI Lab · 2024年
以上内容由遇见数据集搜集并总结生成


