d1272/SgMy-Compliance-Instruct-500
收藏Hugging Face2026-04-25 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/d1272/SgMy-Compliance-Instruct-500
下载链接
链接失效反馈官方服务:
资源简介:
SgMy-Compliance-Instruct-500是一个高质量、由专家策划的指令调优数据集,包含500个条目,专注于东南亚(特别是马来西亚和新加坡)的监管环境。数据集分为现代业务运营的五个关键支柱,每个条目旨在通过结构化的“天真与专家”思维链(CoT)方法,训练大型语言模型(LLM)从简单的文档摘要转向专业的监管推理。数据集包括银行反洗钱/了解你的客户(AML/KYC)、数据隐私(PDPA)、技术风险、工作场所安全和数字资产等五个支柱,每个支柱包含100个条目。每个条目包含支柱类别、具体监管引用、现实业务困境、内部推理块和专业回答。数据集以其专业深度和技术精确性著称,适合用于监督微调(SFT)、思维链蒸馏、检索增强生成(RAG)基准测试和合规红队测试。
SgMy-Compliance-Instruct-500 is a high-fidelity, expert-curated instruction-tuning dataset containing 500 entries focused on the regulatory landscape of Southeast Asia, specifically Malaysia and Singapore. The dataset is divided into five critical pillars of modern business operations, with each entry designed to train Large Language Models (LLMs) to transition from simple document summarization to professional regulatory reasoning using a structured Naive vs. Expert Chain-of-Thought (CoT) approach. The five pillars include Banking AML/KYC, Data Privacy (PDPA), Tech Risk, Workplace Safety, and Digital Assets, with 100 entries per pillar. Each entry contains the pillar category, specific regulatory citation, real-world business dilemma, internal reasoning block, and a professional, legally-grounded answer. The dataset is distinguished by its professional depth and technical precision, making it suitable for Supervised Fine-Tuning (SFT), CoT Distillation, RAG Benchmarking, and Compliance Red-Teaming.
提供机构:
d1272
搜集汇总
数据集介绍
构建方式
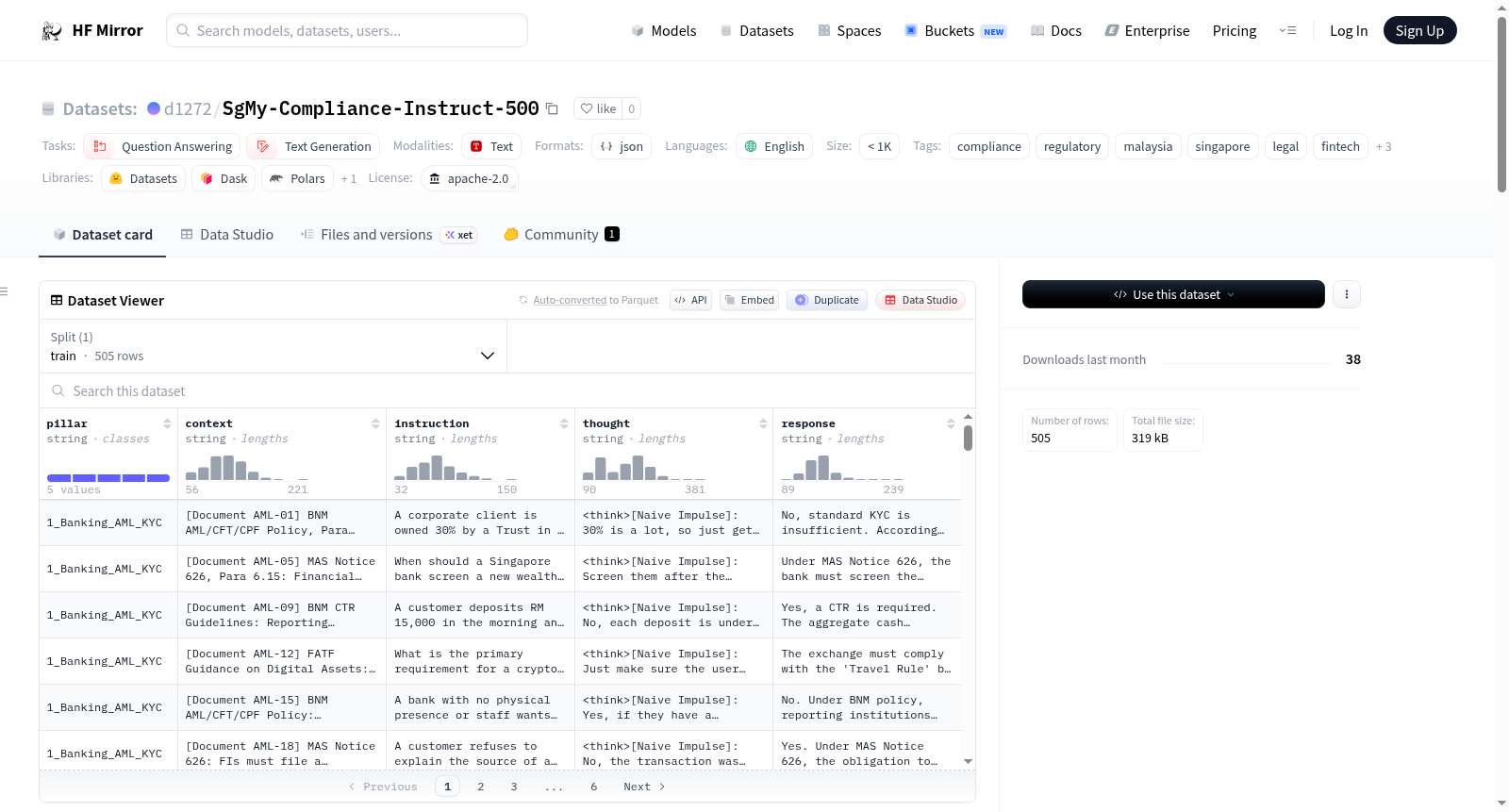
SgMy-Compliance-Instruct-500 数据集由领域专家精心构建,精选 500 条指令-响应对,覆盖新加坡与马来西亚合规领域的五大核心支柱:银行反洗钱/KYC、数据隐私、技术风险、工作场所安全及数字资产。每条数据均采用结构化 JSON 格式,包含支柱分类、监管条文上下文、实际业务困境指令、内部推理链以及专业响应。推理链创新性地采用“朴素 vs. 专家”思维链设计,通过识别常见错误、运用法律原则进行批判性分析并合成正确路径,引导模型掌握合规判断的完整过程。所有响应均严格锚定具体监管文件编号与框架,确保高度可追溯性。
特点
该数据集的核心特色在于其“朴素 vs. 专家”推理架构,每个条目均包含一个明确标识常见错误的思考块,通过批判性分析和逻辑校正,教导模型进行专业合规推理,而非简单记忆。数据集专注于运营边缘案例,如控制权与所有权的区分、举报悖论及现代技术风险,深度呈现新加坡与马来西亚之间的司法管辖区差异,例如不同的报告窗口期和地方法规修订。每个响应均基于特定文档 ID 和监管框架,使其成为检索增强生成系统的理想基准,可精准测试模型检索与应用法规的能力。
使用方法
该数据集主要适用于监督式微调,训练大型语言模型成为专业合规顾问;也可用于思维链蒸馏,通过推理块提升小型模型的逻辑能力。在检索增强生成基准测试中,可检验模型对特定文档 ID 的检索准确性。此外,数据集还适用于合规红队测试,评估模型在面对业务指令的压力时,能否抵制“捷径”或“社会工程学”攻击,坚守合规底线。使用时需注意,数据反映 2024 年初的法规状态,且严格针对马来西亚与新加坡,不构成法律建议。
背景与挑战
背景概述
在金融科技快速演进的背景下,东南亚地区的新加坡与马来西亚作为区域金融枢纽,其监管合规体系日益复杂,对大型语言模型在专业法律推理与指令遵循方面提出了严苛要求。SgMy-Compliance-Instruct-500数据集由专家团队于2024年精心构建,专注于银行反洗钱/了解你的客户、数据隐私、技术风险、工作场所安全及数字资产五大关键支柱,旨在解决模型从简单文档摘要向专业监管推理跃迁的核心研究问题。该数据集以其独特的‘朴素与专家’思维链架构和严格的监管引用基础,为该地区合规性人工智能评估提供了高保真基准,显著推动了指令微调与检索增强生成技术在法律科技领域的发展。
当前挑战
该数据集面临的核心挑战在于弥合机器理解与复杂监管逻辑之间的鸿沟。在领域问题层面,它需克服大型语言模型在面对所有权与控制权区分、举报悖论及技术风险红线等边缘案例时,易产生的机械式记忆与错误泛化问题。在构建过程中,挑战则体现为:如何精准捕获新加坡与马来西亚之间如报告时限、法律更新等细微的司法管辖区差异;如何设计兼具引导性又防止泄漏答案的‘朴素与专家’推理结构,确保模型能学习判断过程而非简单输出。此外,保持数据对2024年早期法规的时效性及避免误导性法律建议也是重大考验。
常用场景
经典使用场景
在东南亚金融科技与合规监管这一高度专业化领域中,SgMy-Compliance-Instruct-500数据集被广泛用于指令微调(Supervised Fine-Tuning, SFT),以构建能够胜任合规顾问角色的对话式大型语言模型。典型场景包括银行反洗钱/客户尽职调查(AML/KYC)、数据隐私保护(PDPA)、技术风险管理、职场安全及数字资产监管等五大核心领域。数据集以100条均衡分布的多支柱架构,使模型能够在新加坡与马来西亚双重司法管辖区下,精准应答实际业务中的复杂边缘案例,例如信托所有权是否触发强化尽职调查、远程工作安全责任认定,或是加密资产交易中的旅行规则执行。
实际应用
在实际商业应用层面,此数据集为金融科技企业、监管科技初创公司及大型银行的合规自动化系统提供了关键训练数据。基于该数据集训练的模型可嵌入实时客户交互系统,识别高风险交易并及时生成符合马来西亚国家银行(BNM)或新加坡金融管理局(MAS)规定的合规报告。此外,在反洗钱定向筛查、员工合规问答平台及跨境支付监控流程中,模型能够依据具体法规文档编号进行可溯源推理,减少人工审查负担,提升响应速度与准确性。数据驱动的合规分析亦被用于企业内训场景,通过模拟压力测试与社交工程场景,培养非专业员工的风险意识。
衍生相关工作
该数据集的发布催生了多项相关研究,尤其在低资源法规领域的大型语言模型对齐工作。研究者基于其思维链结构开发了合规性定向蒸馏(CoT Distillation)方法,将小型模型的能力提升至接近百亿参数级别;同时该数据集被用于构建RAG基准测试,验证检索系统在多文档法规库中的精确度与鲁棒性。此外,多个工作将其作为红队测试(Compliance Red-Teaming)的评估集,衡量模型在面对业务压力下是否能够抵制简化倾向或社交工程攻击。受其启发,系列工作开始探索扩展到东盟其他司法管辖区(如泰国、印尼)及全球性反洗钱标准(FATF)的合规对齐数据集。
以上内容由遇见数据集搜集并总结生成


