HOVER
收藏arXiv2020-11-16 更新2024-06-21 收录
下载链接:
https://hover-nlp.github.io
下载链接
链接失效反馈官方服务:
资源简介:
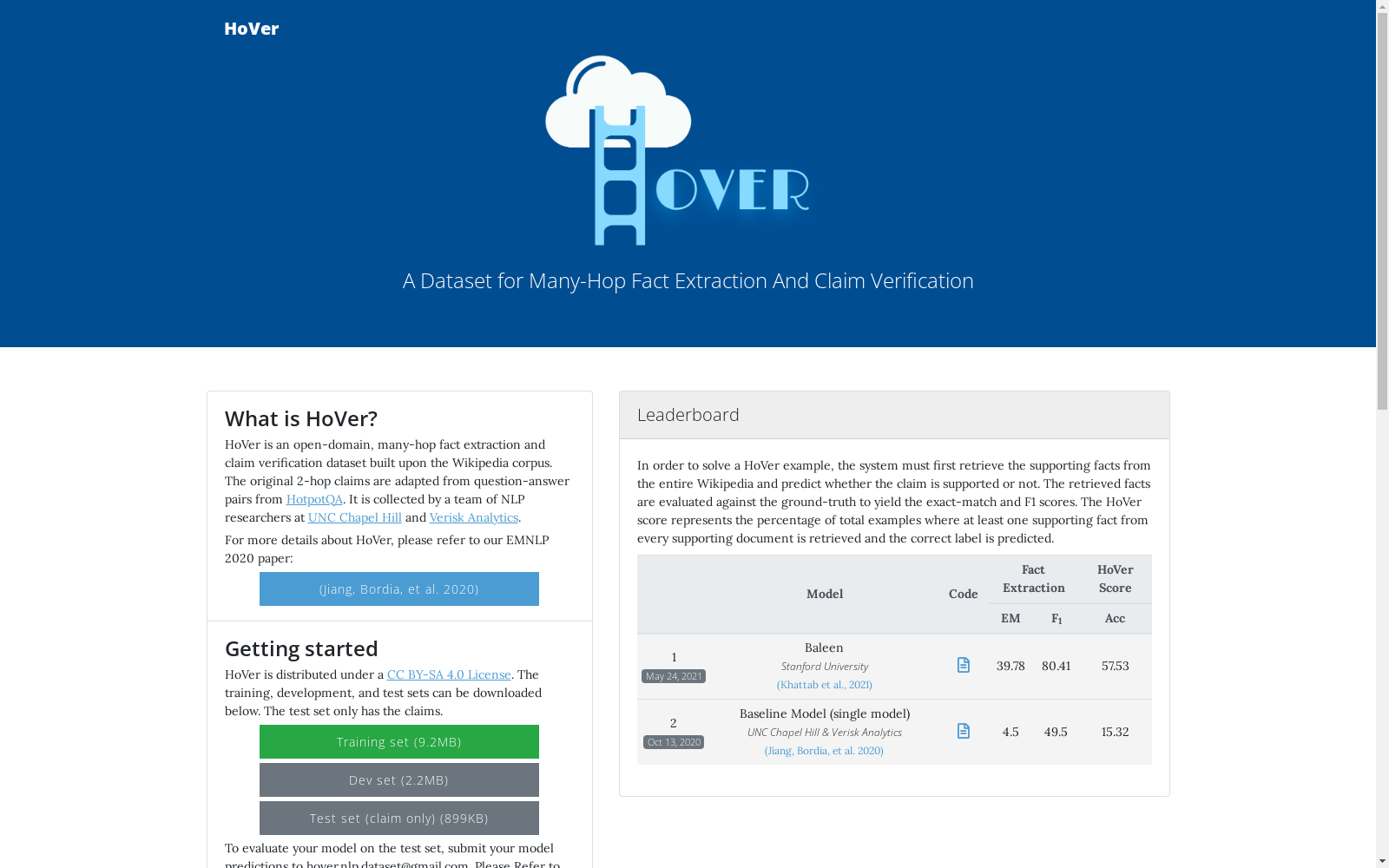
HOVER是一个用于多跳证据提取和事实验证的数据集,由北卡罗来纳大学教堂山分校创建。该数据集包含26,000个需要从多达四个英文维基百科文章中提取证据的声明,并涉及多种形状的推理图。数据集的创建过程分为三个阶段,通过训练有素的众包工作者进行问题重写和实体替换。HOVER数据集旨在推动复杂多跳推理在信息检索和验证领域的研究,特别是在处理长距离依赖关系和多文档信息整合方面。
HOVER is a dataset for multi-hop evidence extraction and fact verification, developed by the University of North Carolina at Chapel Hill. This dataset contains 26,000 claims that require extracting supporting evidence from up to four English Wikipedia articles, and covers reasoning graphs of various structures. The creation process of the HOVER dataset is divided into three stages, with trained crowd workers undertaking question rewriting and entity replacement. The HOVER dataset aims to advance research on complex multi-hop reasoning in the fields of information retrieval and fact verification, particularly in addressing long-distance dependencies and multi-document information integration.
提供机构:
北卡罗来纳大学教堂山分校
创建时间:
2020-11-06
搜集汇总
数据集介绍
构建方式
HOVER 数据集的构建分为三个阶段。第一阶段,从 HOTPOTQA 数据集中重写问答对,形成 2 跳的声明。第二阶段,通过人工编辑和自动词/实体替换,对第一阶段生成的声明进行变异,创建不被证据支持的声明。第三阶段,将所有声明(原始和变异)分为 SUPPORTED、REFUTED 或 NOTENOUGHINFO 三类,并将 REFUTED 和 NOTENOUGHINFO 合并为 NOT-SUPPORTED 类。
使用方法
使用 HOVER 数据集进行多跳事实提取和声明验证任务。首先,使用基于规则或神经网络的文档检索方法,从维基百科中检索与声明相关的文档。然后,使用神经网络句子选择方法,从检索到的文档中选择与声明相关的句子。最后,使用自然语言推理模型,判断声明是否被证据支持。
背景与挑战
背景概述
随着社交媒体和数字内容的蓬勃发展,虚假信息和谣言也随之增多,导致公众观点两极分化。为了应对这一挑战,研究人员致力于开发基于自动检索事实和证据的事实核查系统。HOVER数据集正是在这一背景下诞生的,它挑战模型从多个相关维基百科文章中提取事实,并判断这些事实是否支持或反驳一个声明。HOVER数据集由UNC Chapel Hill和Verisk Analytics的研究人员于2020年创建,包含超过2.6万个声明,这些声明需要从最多四篇英文维基百科文章中提取证据,并包含推理图,推理图的形状多样。该数据集的引入为多跳事实检索和信息推理的研究提供了新的挑战和机遇。
当前挑战
HOVER数据集主要面临的挑战包括:1) 多跳推理的挑战:随着推理步数的增加,模型的性能会显著下降,这表明需要进行鲁棒的多跳推理才能取得良好的结果;2) 构建过程中的挑战:为了减少推理捷径,HOVER数据集采用了多种方法来扩展推理步数,例如将实体替换为相对从句或短语,这增加了声明的复杂性和长度;3) 声明分类的挑战:由于多跳声明的复杂性,在判断声明是否被支持时,区分“反驳”和“信息不足”的标签变得模糊,因此HOVER数据集将这两个标签合并为“不支持”类别,以简化分类任务。
常用场景
经典使用场景
HOVER 数据集主要应用于多跳事实提取和声明验证任务。该数据集挑战模型从与声明相关的多个维基百科文章中提取事实,并分类声明是否由事实支持或未支持。HOVER 数据集的声明需要从最多四个英文维基百科文章中提取证据,并体现多样化的推理图结构。此外,大多数 3/4 跳声明以多句话的形式撰写,这增加了理解长距离依存关系(如共指)的复杂性。HOVER 数据集的引入促进了多跳事实检索和信息检索领域的研究。
解决学术问题
HOVER 数据集解决了现有事实提取和验证数据集在推理步骤数量和声明与所有证据之间的词汇重叠方面的局限性。FEVER 数据集主要限制在单跳设置,而现有的多跳问答数据集推理步骤有限,并且声明与所有证据之间存在大量词汇重叠。HOVER 数据集的声明需要从最多四个英文维基百科文章中提取证据,并体现多样化的推理图结构,从而有效地促进了多跳事实检索和信息检索领域的研究。
实际应用
HOVER 数据集的实际应用场景包括社交媒体平台、新闻网站等需要事实核查的系统。通过自动检索事实和证据,该数据集可以帮助系统验证声明,识别虚假信息和误导性信息,从而提高信息传播的准确性和可靠性。此外,HOVER 数据集还可以应用于机器阅读理解、问答系统等领域,提高模型对复杂推理的理解能力。
数据集最近研究
最新研究方向
HOVER数据集的引入,标志着事实抽取和验证领域向多跳推理方向迈出了重要一步。该数据集要求模型从多达四篇英文维基百科文章中提取事实,并判断断言是否被这些事实所支持,从而挑战了模型在处理长距离依存关系和复杂推理结构方面的能力。HOVER数据集的出现,揭示了现有最先进模型在多跳推理任务上的局限性,并突显了发展能够处理复杂多跳推理的模型的重要性。该数据集有望推动多跳事实检索和信息检索领域的研究,并促进更精确、更可靠的事实验证系统的开发。
相关研究论文
- 1HoVer: A Dataset for Many-Hop Fact Extraction And Claim Verification北卡罗来纳大学教堂山分校 · 2020年
以上内容由遇见数据集搜集并总结生成


