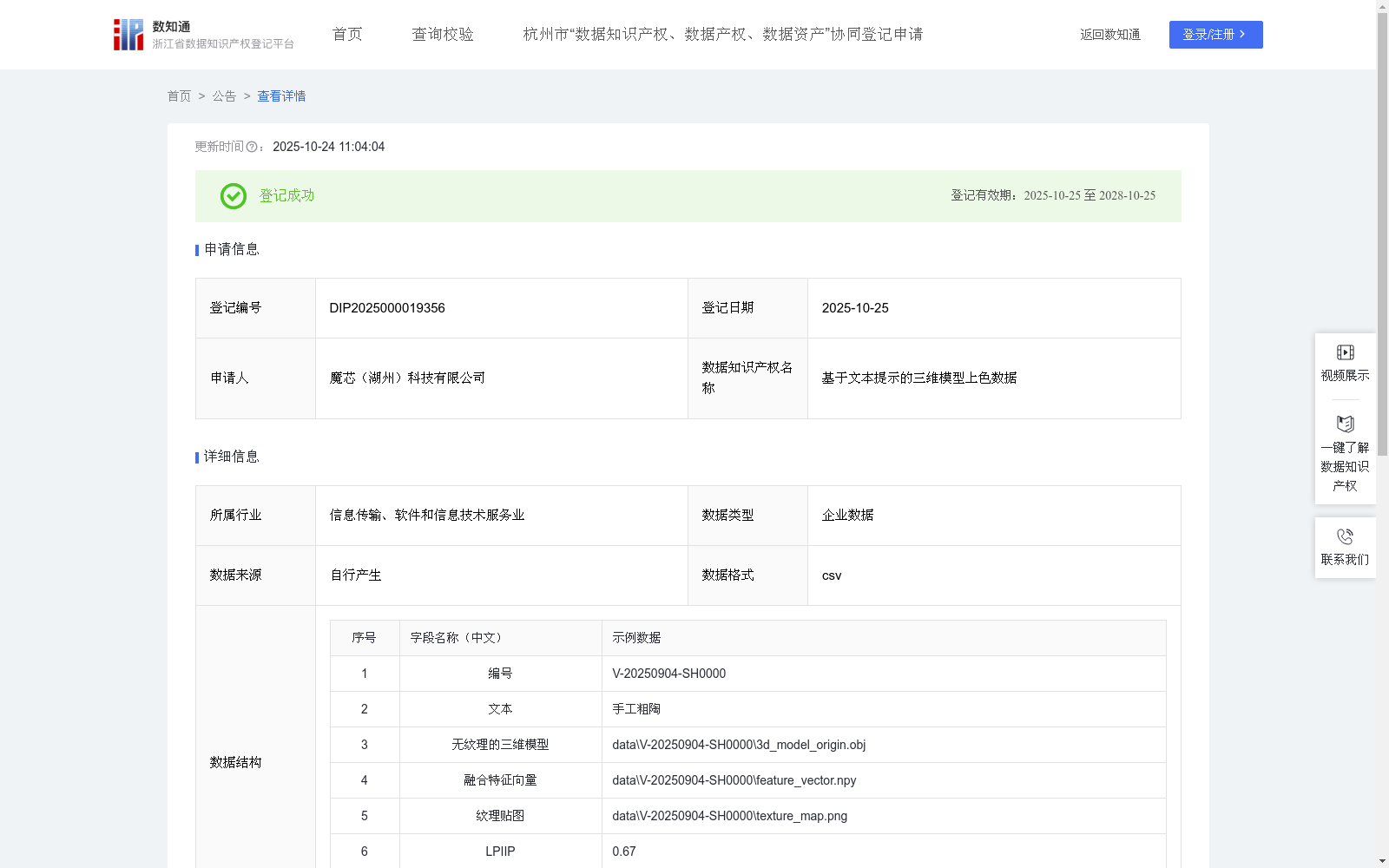
基于文本提示的三维模型上色数据
收藏浙江省数据知识产权登记平台2025-10-24 更新2025-10-25 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/5053435
下载链接
链接失效反馈官方服务:
资源简介:
通过构建一个包含无纹理三维模型、描述其目标外观的文本提示、以及最终着色完成的三维模型的大规模配对数据集,可以为深度学习模型提供训练基础,使其学习从文本指令到模型表面属性的精准映射。这一数据集适用于游戏资产的快速生成与迭代、虚拟化身与环境的个性化定制、工业产品不同材质和配色的可视化以及电子商务商品展示等领域。利用该数据训练出的模型,能够让设计师和开发者通过自然语言指令为三维模型自动进行纹理绘制和上色,从而极大简化了传统UV展开、贴图绘制和材质设定的复杂流程,解决了三维模型纹理制作技术门槛高、耗时耗力的问题。基于文本提示为三维模型上色是实现自动化内容生成的关键流程。具体过程包括:(1)数据收集:输入一个无纹理的三维模型(M_uncolored)和一个描述目标颜色、纹理或风格的文本(T_prompt)。(2)数据处理:分别使用几何编码器和文本编码器处理输入。几何编码器将三维模型的形状信息编码为特征向量,而文本编码器将文本提示的语义信息编码为另一个特征向量。随后,将这两个特征向量进行融合,形成一个统一的条件特征向量。该特征向量通过公式 F_combined = Fuse(Encoder_geo(M_uncolored), Encoder_text(T_prompt)) 提取,其中 F_combined 为融合特征向量,Encoder_geo 为几何编码器,Encoder_text 为文本编码器。(3)模型构建:使用融合特征向量 F_combined 作为条件,设计并搭建一个深度生成模型,该模型学习根据文本意图在原始几何表面上生成颜色或纹理信息。根据公式 Texture_map = Decoder_color(F_combined) 从融合特征中解码生成对应的纹理贴图,其中 Texture_map 为生成的纹理贴图,Decoder_color 为颜色/纹理解码器;关键的评估指标包括用于衡量感知相似度的学习感知图像块相似度(LPIIPs)和用于评估生成图像质量的弗雷切特起始距离(FID)。此方法适用于三维模型的自动化和智能化纹理生成,通过输入文本指令,实现对模型外观的高效定制和创作。
A large-scale paired dataset comprising untextured 3D models, text prompts describing their target appearance, and fully colored final 3D models can serve as a training foundation for deep learning models, enabling them to learn the precise mapping from text instructions to the surface properties of 3D models. This dataset finds applications in scenarios including rapid generation and iteration of game assets, personalized customization of virtual avatars and environments, visualization of diverse materials and color schemes for industrial products, and e-commerce product display. Models trained on this dataset allow designers and developers to automatically perform texture painting and coloring on 3D models through natural language instructions, drastically simplifying the complex workflows of traditional UV unwrapping, texture painting and material setup, and resolving the long-standing issues of high technical thresholds, time consumption and labor intensity in 3D model texture production. Coloring 3D models based on text prompts represents a critical workflow for automated content generation. The specific process includes: (1) Data Collection: Input an untextured 3D model ($M_{ ext{uncolored}}$) and a text prompt ($T_{ ext{prompt}}$) that describes the target color, texture or style of the model. (2) Data Processing: Process the inputs separately using a geometric encoder and a text encoder. The geometric encoder encodes the shape information of the 3D model into a feature vector, while the text encoder encodes the semantic information of the text prompt into another feature vector. The two feature vectors are then fused to generate a unified conditional feature vector. This vector is extracted via the formula $F_{ ext{combined}} = ext{Fuse}( ext{Encoder}_{ ext{geo}}(M_{ ext{uncolored}}), ext{Encoder}_{ ext{text}}(T_{ ext{prompt}}))$, where $F_{ ext{combined}}$ denotes the fused feature vector, $ ext{Encoder}_{ ext{geo}}$ is the geometric encoder, and $ ext{Encoder}_{ ext{text}}$ is the text encoder. (3) Model Construction: Design and develop a deep generative model that takes the fused feature vector $F_{ ext{combined}}$ as the conditional input. This model learns to generate color or texture information on the original geometric surface based on the intent conveyed by the text prompt. The corresponding texture map is decoded and generated from the fused features via the formula $ ext{Texture\_map} = ext{Decoder}_{ ext{color}}(F_{ ext{combined}})$, where $ ext{Texture\_map}$ refers to the generated texture map, and $ ext{Decoder}_{ ext{color}}$ is the color/texture decoder. Key evaluation metrics include Learned Perceptual Image Patch Similarity (LPIIPs) for quantifying perceptual similarity, and Fréchet Inception Distance (FID) for assessing the quality of generated images. This method enables automated and intelligent texture generation for 3D models, allowing efficient customization and creation of model appearances by inputting natural language instructions.
提供机构:
魔芯(湖州)科技有限公司
创建时间:
2025-09-04
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集包含5704条CSV格式数据,用于训练深度学习模型从文本提示自动为三维模型上色,支持游戏资产生成和工业产品可视化等应用。数据包括无纹理模型、文本描述和纹理贴图,通过融合特征向量实现精准映射,简化传统纹理制作流程。
以上内容由遇见数据集搜集并总结生成


