MME-Reasoning
收藏arXiv2025-05-27 更新2025-05-29 收录
下载链接:
https://alpha-innovator.github.io/mmereasoning.github.io/ https://github.com/Alpha-Innovator/MME-Reasoning https://huggingface.co/datasets/U4R/MME-Reasoning
下载链接
链接失效反馈官方服务:
资源简介:
MME-Reasoning是一个用于评估多模态大型语言模型(MLLMs)推理能力的全面基准数据集,由复旦大学、香港中文大学MMLab、上海人工智能实验室等机构合作创建。该数据集包含1188个精心设计的题目,涵盖了归纳、演绎和溯因三种推理类型,并通过多选题、自由回答和基于规则的问题等多种形式进行评估。MME-Reasoning旨在评估MLLMs的核心推理技能,而不依赖于复杂的领域知识或简单的视觉感知能力,从而提供了一个全面且具有挑战性的推理能力评估基准。
MME-Reasoning is a comprehensive benchmark dataset for evaluating the reasoning capabilities of multimodal large language models (MLLMs), developed collaboratively by institutions including Fudan University, MMLab at The Chinese University of Hong Kong, the Shanghai AI Laboratory, among others. This dataset contains 1188 meticulously designed questions covering three reasoning types: inductive, deductive and abductive, and evaluates models via multiple formats such as multiple-choice questions, free-response questions and rule-based questions. MME-Reasoning aims to assess the core reasoning skills of MLLMs without relying on complex domain-specific knowledge or simple visual perception abilities, thus providing a comprehensive and challenging benchmark for reasoning capability evaluation.
提供机构:
复旦大学、香港中文大学MMLab、上海人工智能实验室、中国科学技术大学、南京大学
创建时间:
2025-05-27
搜集汇总
数据集介绍
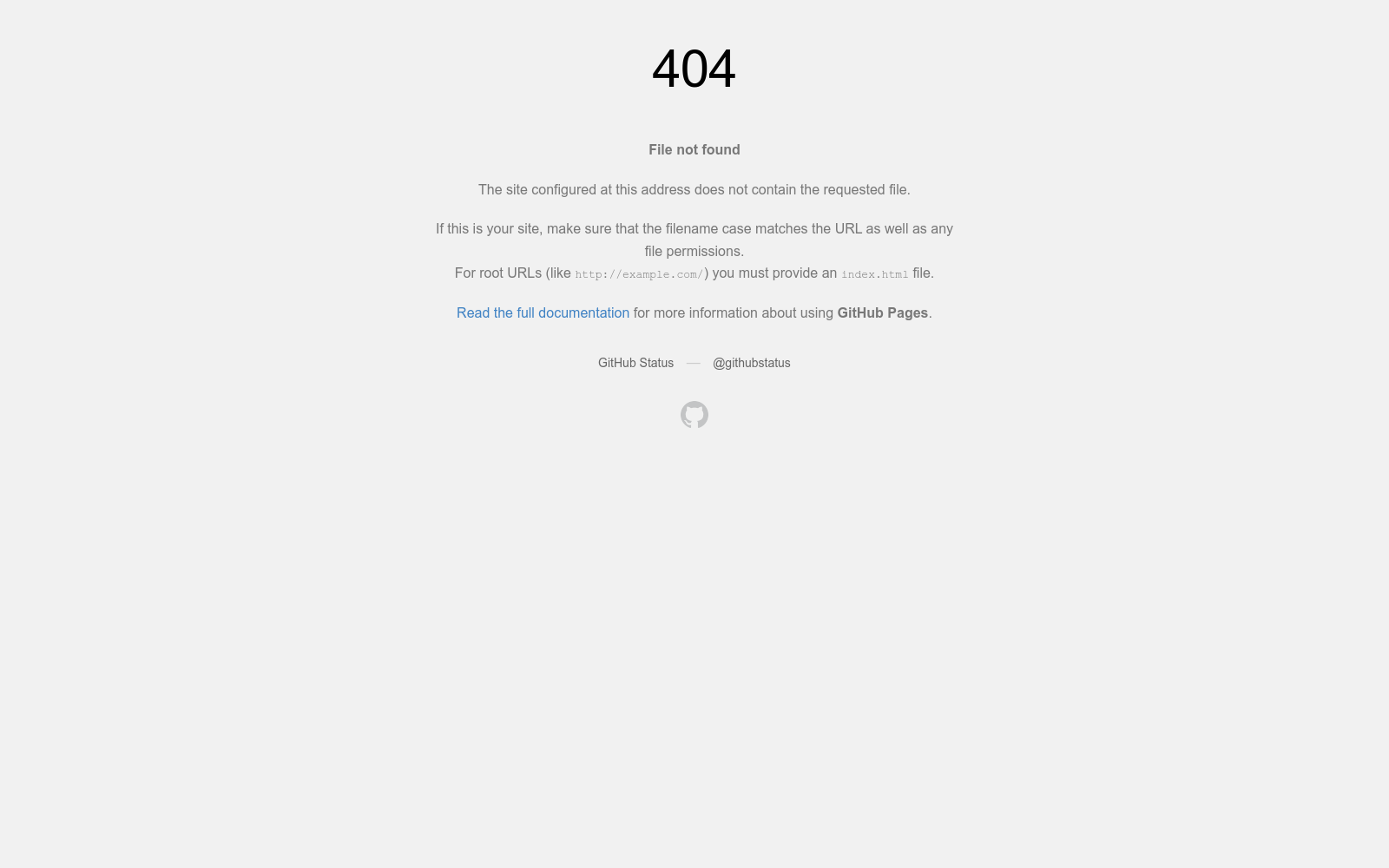
构建方式
MME-Reasoning数据集的构建过程经过精心设计,以确保全面评估多模态大语言模型(MLLMs)的逻辑推理能力。首先,研究团队从多种来源收集问题,包括教科书、在线资源、逻辑推理书籍、合成问题以及现有基准数据集中的样本。随后,通过严格的人工筛选过程,剔除了仅依赖视觉识别或需要复杂领域知识的问题,确保每个问题都能有效评估核心推理能力而非感知技能或知识广度。最终,数据集包含1,188个问题,涵盖归纳、演绎和溯因三种推理类型,并分为简单、中等和困难三个难度级别。
特点
MME-Reasoning数据集具有三个显著特点。首先,它系统覆盖了逻辑推理的三种主要类型(归纳、演绎和溯因),填补了现有基准在溯因推理评估上的空白。其次,数据集特别设计了五种关键能力评估维度:计算、规划与探索、时空推理、模式分析和因果链分析,为模型能力提供细粒度评估。最后,数据集采用多样化的评估形式,包括多选题、自由回答题和基于规则的问题(如数独谜题),确保评估的全面性和灵活性。
使用方法
使用MME-Reasoning数据集时,研究人员可通过三种主要方式进行评估。对于多选题,直接比对模型输出与参考答案;对于自由回答题,使用GPT等模型判断答案一致性;对于基于规则的问题,先将模型输出转换为中间格式,再通过特定脚本验证其正确性。评估过程重点关注模型在不同推理类型(归纳/演绎/溯因)和不同难度级别上的表现差异。此外,数据集支持对"思维模式"和基于规则的强化学习等方法的效果分析,为提升模型推理能力提供系统化见解。
背景与挑战
背景概述
MME-Reasoning是由上海人工智能实验室、复旦大学、香港中文大学多媒体实验室等机构的研究团队于2025年提出的多模态大语言模型逻辑推理评测基准。该数据集包含1,188个经过精心设计的问题,全面覆盖归纳、演绎和溯因三种基本推理类型,旨在系统评估模型在计算、规划探索、时空推理、模式分析和因果链分析等五大核心能力上的表现。作为首个完整涵盖经典逻辑推理类型的多模态评测基准,MME-Reasoning通过严格控制感知干扰和领域知识依赖,确保了评测结果真实反映模型的推理能力而非其他干扰因素。
当前挑战
MME-Reasoning面临的核心挑战体现在两个方面:在领域问题层面,现有模型在三种推理类型上表现严重失衡,尤其溯因推理成为显著瓶颈,闭源与开源模型的平均性能差距分别达5.38和9.81个点;在构建过程层面,需解决推理类型系统覆盖、感知与推理严格区分、领域知识干扰排除等难题。具体挑战包括:1) 保持问题设计在知识轻量化与推理深度间的平衡;2) 开发适用于开放回答和规则型问题的自动化评测协议;3) 构建跨模态的复杂推理链标注体系。
常用场景
经典使用场景
MME-Reasoning数据集在评估多模态大语言模型(MLLMs)的逻辑推理能力方面具有广泛的应用。该数据集通过精心设计的1,188个问题,全面覆盖了归纳、演绎和溯因三种推理类型,适用于测试模型在不同难度和场景下的表现。研究人员利用该数据集可以系统地分析模型在计算、规划与探索、时空推理、模式分析和因果链分析等关键能力上的表现,从而揭示模型在复杂逻辑推理任务中的优势和不足。
解决学术问题
MME-Reasoning数据集解决了当前多模态推理评估中存在的两大核心问题:推理类型覆盖不全和推理与感知混淆。通过明确区分三种经典推理类型并剔除依赖纯感知或领域知识的问题,该数据集确保了评估的纯粹性和全面性。其创新性的数据标注体系(包括问题类型、难度层级和能力维度)为学术界提供了首个系统性评估MLLMs综合推理能力的基准,填补了现有评估工具在溯因推理和开放性问题求解等关键维度上的空白。
衍生相关工作
该数据集的发布推动了多项衍生研究:基于Rule-based RL的推理增强方法(如R1-VL、Vision-R1)通过MME-Reasoning验证了训练范式的有效性;思维链提示工程研究利用其长序列推理任务优化了CoT生成策略;测试时计算扩展技术(如MCTS)则以其复杂问题为基准探索推理效率与性能的平衡。相关工作进一步扩展了数据集在视频推理(Video-R1)、科学问题求解(SciVerse)等领域的应用场景。
以上内容由遇见数据集搜集并总结生成


