EarthSpeciesProject/ROOTS
收藏Hugging Face2026-05-07 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/EarthSpeciesProject/ROOTS
下载链接
链接失效反馈官方服务:
资源简介:
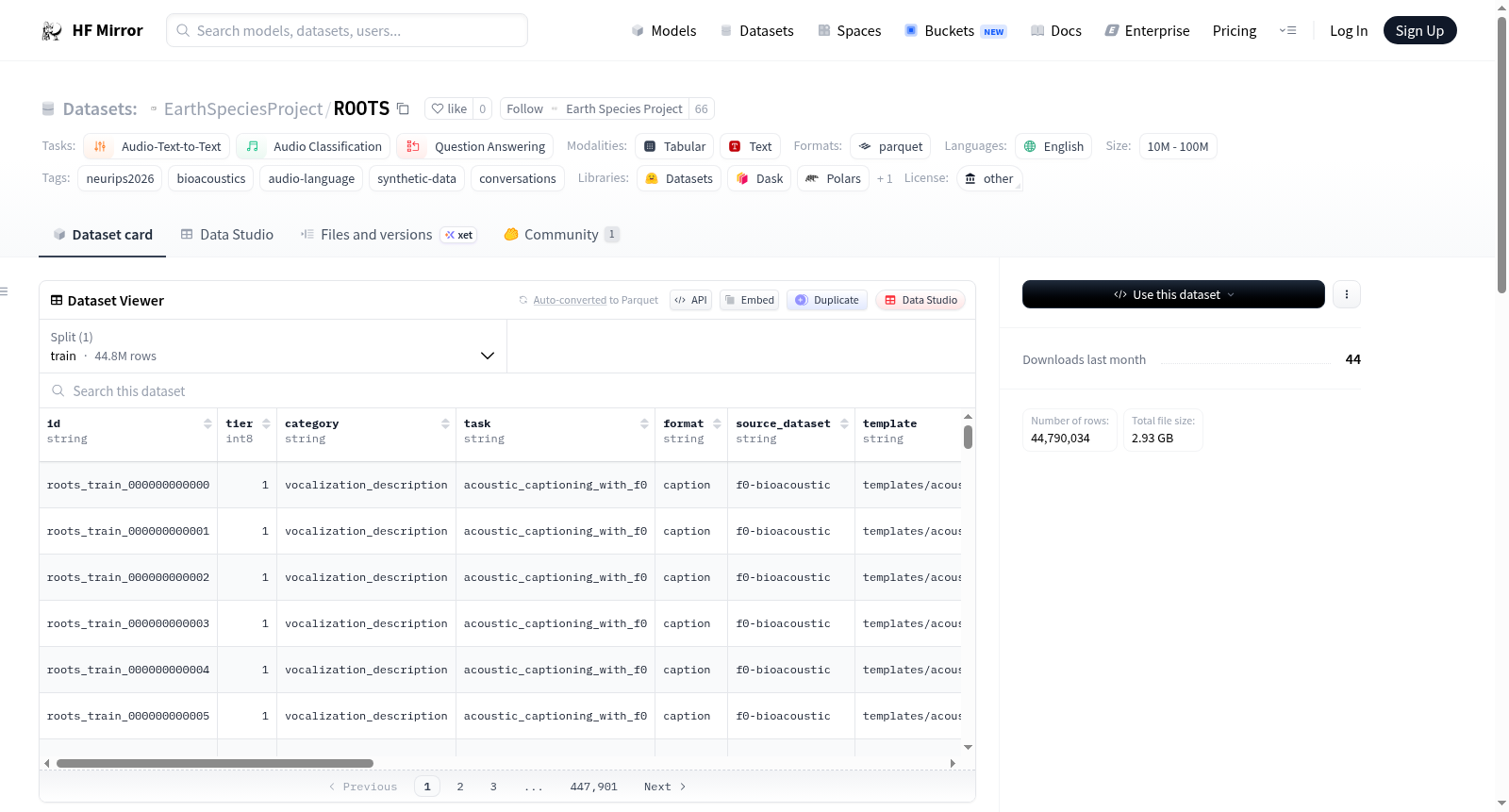
ROOTS是一个生物声学的音频-语言训练数据集,包含生成的语言任务与源音频的引用。该存储库仅包含语言/对话内容和公开的音频标识符,不包含音频文件本身。数据集包含44,790,034行数据,分为9,074个Parquet分片。数据集的模式(Schema)包括多个字段,如ID、训练层级、任务类别、任务、格式、源数据集、模板、源ID、音频路径、源音频ID、源URL、音频开始和结束时间、音频数量以及对话消息等。音频文件不包含在数据集中,部分行引用了公共源数据集(如Xeno-Canto或iNaturalist)的ID和URL,其他行则仅通过相对文件名/路径引用合成或私有源音频,这些音频文件可能无法从该数据集中公开获取。
ROOTS is a bioacoustic audio-language training dataset containing generated language tasks paired with references to source audio. This repository contains language/conversation content and public-oriented audio identifiers only; it does not host audio files. The dataset consists of 44,790,034 rows, divided into 9,074 Parquet shards. The schema includes fields such as ID, training tier, task category, task, format, source dataset, template, source ID, audio paths, source audio IDs, source URLs, audio start and end times, number of audios, and conversation messages. Audio files are not included in the dataset; some rows reference public source datasets like Xeno-Canto or iNaturalist through IDs and URLs, while others reference synthetic or private-source audio by relative filename/path only, which may not be publicly retrievable from this dataset alone.
提供机构:
EarthSpeciesProject
搜集汇总
数据集介绍
构建方式
ROOTS数据集是一个面向生物声学领域的音频-语言训练数据集,其构建方式兼具系统性与层次性。该数据集共包含44,790,034行数据,划分为四个训练层级(tier 1至4),每一层级对应不同的任务复杂度。数据集的每一行都通过ID、类别、任务标签、答案格式、来源数据集及生成模板等多维字段进行精确描述,确保了内容的结构化与可追溯性。音频数据以相对路径和公共来源标识符(如Xeno-Canto或iNaturalist的ID与URL)的形式引用,而非直接托管音频文件。此外,部分行通过规则或模板自动生成,体现了在数据生成过程中的自动化与规则化策略。所有数据以Parquet格式分片存储,并附有详细的导出摘要统计文件,便于用户了解各层级的分布情况。
特点
ROOTS数据集的核心特点在于其高度结构化的多模态对话内容与生物声学领域的深度融合。其对话消息以角色(role)和内容(content)为基本单元,支持字幕、多选题、二值判断、开放式问答及多标签分类等多种答案格式,覆盖了从简单识别到复杂推理的广泛任务。数据集按四个训练层级渐进式组织,有助于模型训练的难度递进与能力构建。每个任务行都关联具体的音频时间戳(起止秒数),支持精确的音频片段定位。特别值得一提的是,该数据集强调公共与合成音频来源的结合,既引用了自然录音库中的可公开获取资源,也包含通过相对路径标识的合成或私有音频,这为其在现实场景与模拟环境中的迁移学习提供了独特优势。
使用方法
使用ROOTS数据集时,用户可通过HuggingFace的datasets库便捷加载,仅需一行Python代码即可获取训练分割中的所有数据。由于音频文件并未直接包含在该数据集中,用户在利用音频数据进行模型训练或评估前,需要根据每条记录中的音频路径及公共URL自行获取相应的音频源文件,或使用本地存储的合成音频。数据集提供的时间戳字段(audio_start_seconds与audio_end_seconds)可用于对长音频进行切片,从而高效构建对齐的音频-语言对。此外,附带的提示模板文件(templates/)可用于重现或自定义数据生成流程,支持对任务格式和对话结构进行灵活调整,特别适用于少样本学习与零样本评估等场景。
背景与挑战
背景概述
ROOTS是一个面向生物声学领域的音频-语言训练数据集,于2025年由Earth Species Project团队创建,旨在推动非人类物种声音理解与跨物种沟通的研究。该数据集包含近4480万条生成式语言任务对,覆盖描述、问答、多选题等多种回答格式,并与来自Xeno-Canto、iNaturalist等公开及合成音频源交叉引用。核心研究问题聚焦于如何利用自然语言处理技术来解读动物发声模式,进而服务于生态监测与动物行为研究。其影响力体现在为生物声学领域提供了首个大规模、多任务的联合学习基准,被视为推动语言模型从人类中心转向生态感知的关键资源。
当前挑战
当前面临的核心挑战涵盖两大维度。首先是领域问题层面,生物声学音频缺乏像人类语言那样的标准化标注体系,模型需应对物种间声学信号的高度异质性与信噪比失衡,同时要处理自然环境中背景噪音、多源混叠与远场录制带来的鲁棒性难题。其次是数据集构建层面,原始音频因版权与隐私限制不能直接分发,仅靠ID和URL引用导致部分来源不可复现;此外,合成数据与模板生成任务虽扩大规模,但可能引入虚假关联与分布偏移,使得模型在真实野外场景下的泛化能力缺乏验证。
常用场景
经典使用场景
在生物声学与人工智能的交叉领域中,ROOTS数据集以其海量的音频-语言对齐样本,定义了多模态学习的新范式。该数据集包含近4500万条记录,涵盖从简单标注到复杂对话的多种任务格式,为训练能够理解动物声音与人类语言映射关系的模型提供了坚实基础。经典使用方式包括利用其分层任务结构(从层级1至4)进行多阶段课程学习,或结合其多元回答格式(如描述、多选题、开放性问答)构建具备跨任务泛化能力的音频语言模型。研究者常以ROOTS作为预训练语料库,通过大规模监督学习使模型掌握生物声学信号与语义概念之间的深层关联。
衍生相关工作
ROOTS数据集的发布催生了一系列开创性的后续工作,有力推动了生物声学人工智能领域的蓬勃发展。在其基础上,研究者构建了首个能够同时处理跨物种声学描述、地域性方言识别与环境声景理解的统一音频语言模型,验证了大规模多任务预训练范式在生物声学领域的迁移有效性。相关衍生工作包括专门针对濒危物种声纹识别的微调框架,以及融合时空信息的生物声学问答系统。同时,ROOTS的分层任务设计激励了课程学习策略的优化研究,衍生出动态难度调整的自动化训练流程。这些工作不仅深化了人类对动物声音世界的理解,也为更广泛的生态智能感知系统构建提供了方法论借鉴。
数据集最近研究
最新研究方向
ROOTS作为生物声学与语言模型交叉领域的前沿数据集,聚焦于利用大规模合成对话与音频任务推动生态声学智能体的发展。其最新研究方向涵盖多模态音频-语言对齐、弱监督声学分类与开放域问答,尤其在NeurIPS 2026发布的背景下,该数据集通过结构化任务层级(Tier 1-4)与模板化生成策略,显著提升了模型在零样本生物声学事件检测与物种识别中的泛化能力。结合Xeno-Canto等公开音频源,ROOTS为构建可交互的生态监测对话系统提供了关键训练资源,对保护生物学中的自动化声学监控与濒危物种响应具有里程碑意义。
以上内容由遇见数据集搜集并总结生成


