kjswaroopNU/celebahq-128-gray
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/kjswaroopNU/celebahq-128-gray
下载链接
链接失效反馈官方服务:
资源简介:
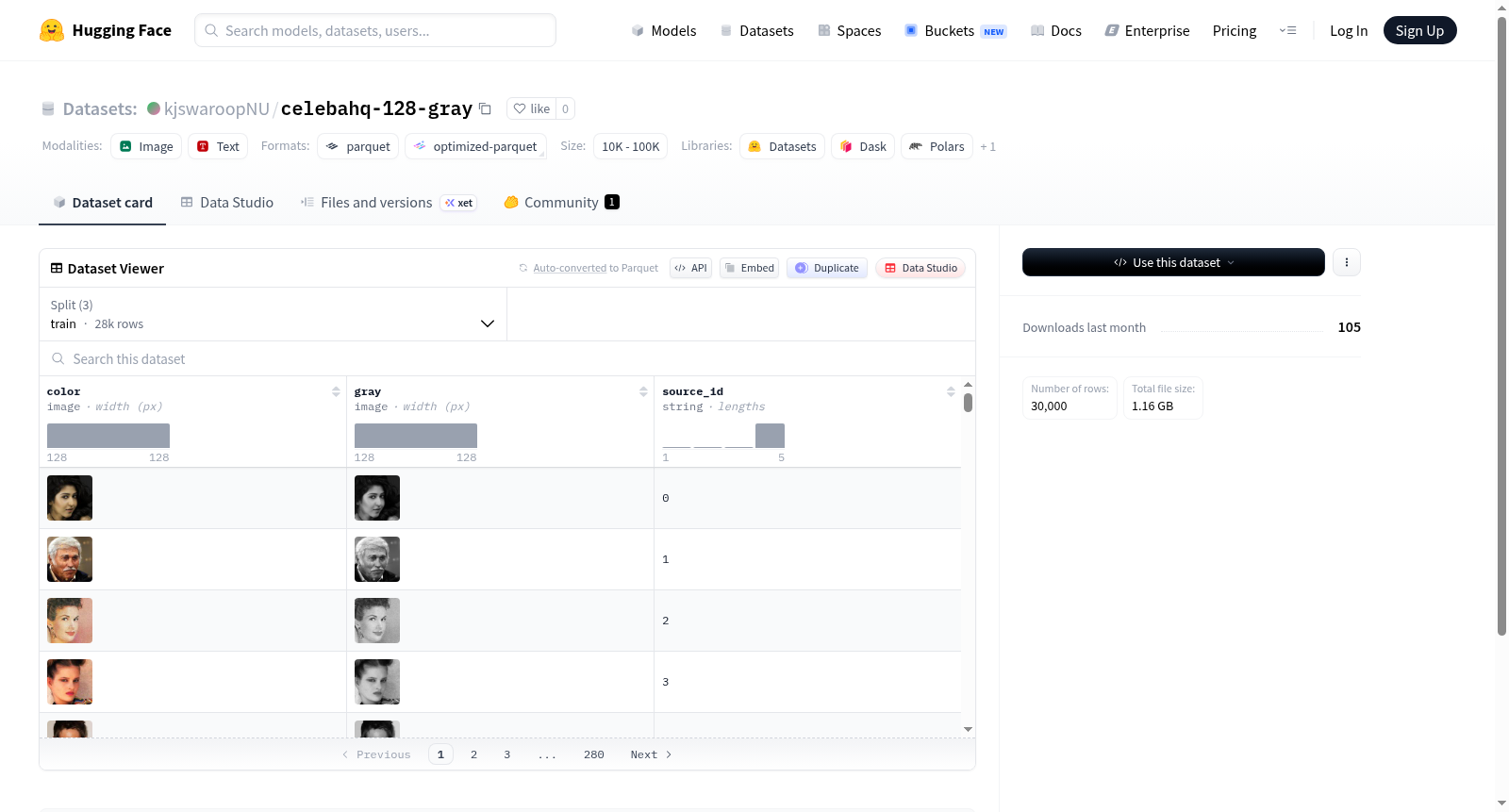
该数据集包含图像数据,主要特征为彩色图像(color)、灰度图像(gray)和源标识符(source_id)。数据集分为训练集(28,000个示例)、验证集(1,000个示例)和测试集(1,000个示例),总大小约为1.16 GB。数据用于图像处理或计算机视觉任务,但具体应用背景未在README中说明。
This dataset contains image data with features including color images, grayscale images, and source identifiers. It is split into training set (28,000 examples), validation set (1,000 examples), and test set (1,000 examples), with a total size of approximately 1.16 GB. The data is intended for image processing or computer vision tasks, but the specific application context is not detailed in the README.
提供机构:
kjswaroopNU
搜集汇总
数据集介绍
构建方式
该数据集源自广受认可的CelebA-HQ人脸数据集,通过精心的预处理流程构建而成。原始高分辨率人脸图像被统一缩放到128×128像素尺寸,随后通过色彩空间转换生成对应的灰度图像,形成一一对应的彩色-灰度图像对。数据集划分为训练集、验证集和测试集三个子集,分别包含28000、1000和1000个样本,并以高效的分片格式存储,便于分布式加载与处理。
特点
数据集的核心特点在于其精心设计的彩色与灰度图像对结构,每张图片均包含color和gray两个字段,为图像复原、超分辨率及色彩化等任务提供了天然的训练与评估基准。所有图像均为128×128像素的统一分辨率,降低了模型输入处理的复杂度。此外,数据集保留了source_id字段,方便溯源至原始CelebA-HQ数据集,增强了研究的可复现性与可拓展性。
使用方法
该数据集可通过HuggingFace Datasets库便捷加载,使用load_dataset函数指定数据集名称即可获取。加载后返回的数据集包含color与gray两个图像字段,用户可根据任务需求自由选择输入与目标模态。典型应用场景包括将gray图像作为输入、color图像作为目标进行训练,或反之实现图像去色与着色模型的构建。数据集已预分好训练、验证、测试集,可直接用于模型评估与对比实验。
背景与挑战
背景概述
在计算机视觉与图像生成领域,人脸图像因其高度的结构性和丰富的信息,常被作为研究图像去噪、超分辨率以及颜色迁移等任务的标准载体。CelebA-HQ数据集作为广泛使用的CelebA数据集的高质量版本,由香港中文大学等多机构的研究者于2018年前后发布,提供了超过三万张高分辨率、具有丰富标注信息的人脸图像,显著推进了人脸属性编辑与生成的研究。在此基础之上,celebahq-128-gray数据集将原始彩色人脸图像转换为128×128像素的灰度版本,并保留了对应的彩色图像,从而为探究从灰度到彩色的色彩复原任务提供了精准的监督信号。该数据集通过其规范化的图像尺寸与配对形式,降低了模型训练的计算开销,同时保持了人脸关键区域的可辨识度,成为评估色彩化算法在细粒度人脸细节重建能力上的重要基准,对低层次视觉任务的发展产生了积极影响。
当前挑战
该数据集所聚焦的色彩化任务本质上是将单通道的灰度图像映射至三通道的彩色空间,属于多模态的一对多映射问题,其核心挑战在于仅凭亮度信息难以唯一确定合理的色彩分布,尤其在人脸区域,肤色、唇色与发色等微细差异需要模型具备上下文语义理解能力。此外,构建过程中将原始CelebA-HQ图像下采样至128×128分辨率并转为灰度,这一操作虽统一了尺寸,却也丢失了高频纹理与色彩细节,使得训练样本中的监督信号本身存在信息瓶颈,要求模型在有限输入下重建丰富的色彩信息。同时,数据集中仅包含正面或半正面的人脸,缺乏姿态与光照的多样性,容易导致模型在真实场景下对侧面人脸或复杂光照条件产生色彩偏移,进一步凸显了数据集规模与场景覆盖度对泛化性能的制约。
常用场景
经典使用场景
celebahq-128-gray数据集在计算机视觉领域中被广泛用作图像去着色任务的标准基准。该数据集以CelebA-HQ为基础,提供了128×128分辨率的彩色人脸图像及其对应的灰度版本,使得研究者能够系统性地评估从灰度图像恢复自然色彩的能力。无论是基于深度学习的端到端生成模型,还是传统方法的色彩传播算法,该数据集都为其提供了高质量且规模适中的训练与测试样本,从而推动了图像着色技术的革新与演进。
衍生相关工作
基于celebahq-128-gray数据集,衍生出了一系列经典工作,例如利用条件生成对抗网络(cGAN)实现的图像着色方法,以及结合自注意力机制和感知损失的先进网络结构。此外,该数据集也催生了用于评估语义引导着色效果的标准协议,并启发了后续如颜色分布对齐、跨域迁移学习等相关研究,进一步拓展了图像到图像翻译领域的理论边界与实践深度。
数据集最近研究
最新研究方向
celeba-hq-128-gray数据集作为CelebA-HQ的灰度化变体,在计算机视觉领域的前沿研究中扮演着关键角色,特别是在人脸图像生成与修复方向。该数据集通过提供对齐的高质量灰度人脸图像及其对应彩色版本,为跨模态图像翻译任务提供了理想基准。当前研究热点集中于结合扩散模型与生成对抗网络进行灰度图像上色,以及探索自监督学习框架下的人脸先验知识提取。随着AI伦理与隐私保护议题升温,灰度人脸数据在规避肤色调偏见、提升模型公平性方面的独特价值日益凸显,推动了无偏面部识别与隐私保护生成模型的发展。
以上内容由遇见数据集搜集并总结生成


