Scouter-ai-dataset
收藏Hugging Face2026-01-29 更新2026-01-30 收录
下载链接:
https://huggingface.co/datasets/yonaitay/Scouter-ai-dataset
下载链接
链接失效反馈官方服务:
资源简介:
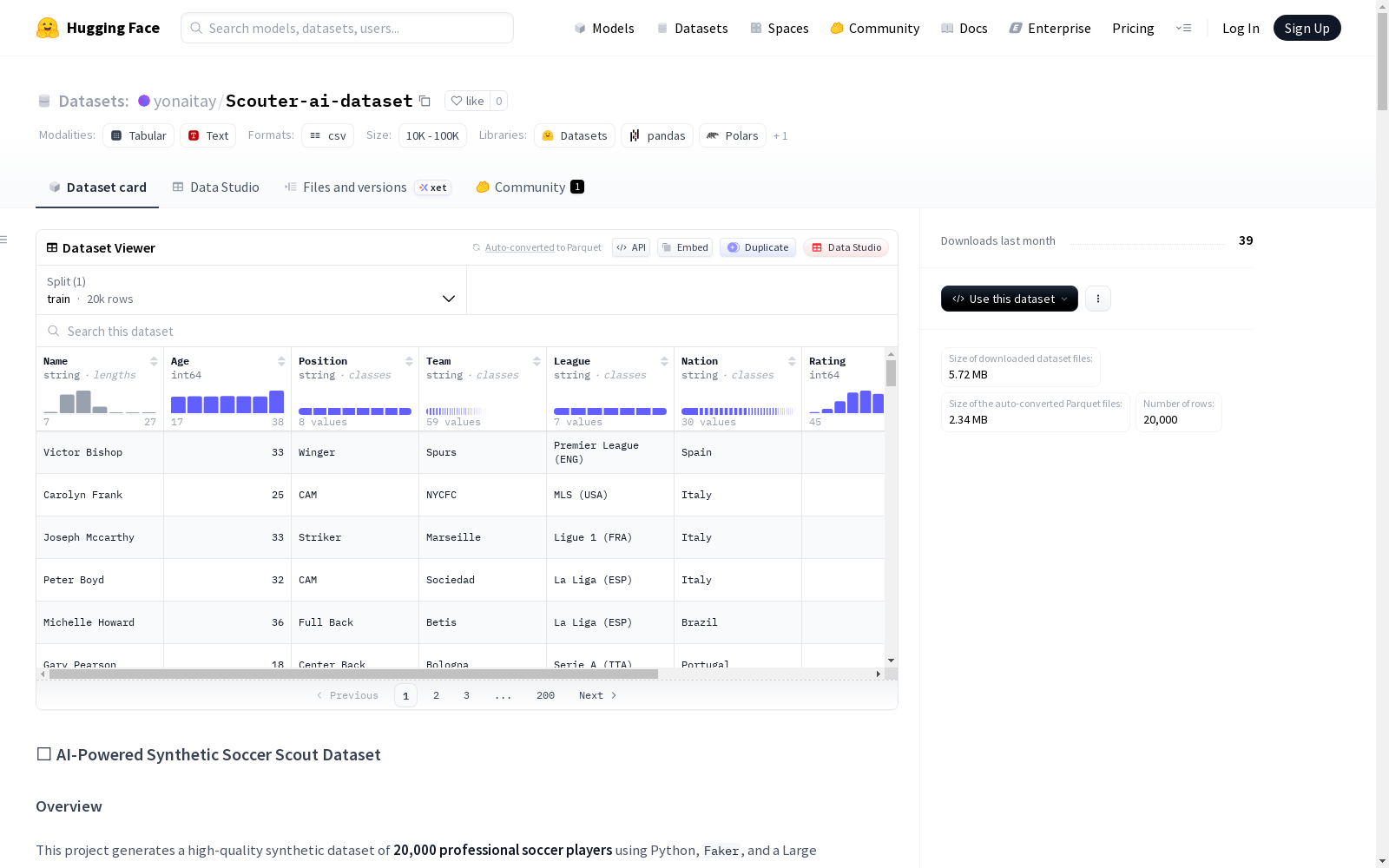
该数据集是一个由AI生成的合成足球球探数据集,包含20,000名职业足球球员的详细资料。数据集使用Python、Faker和大型语言模型(LLM)生成,具有高度真实性和多样性。每个球员的资料包括姓名、年龄、位置、所属球队、联赛、国籍、技能评分、市场价值和球探报告。市场价值通过自定义算法根据年龄、评分和潜力计算得出,球探报告则由Qwen-2.5-0.5B-Instruct模型生成。数据集适用于自然语言处理(NLP)任务、回归分析和数据可视化。数据集结构为CSV格式,包含以下字段:Name(球员姓名)、Age(年龄,17-38岁)、Position(位置,如前锋、中后卫、门将等)、Team(所属球队,来自真实世界的联赛如英超、西甲等)、League(所属联赛)、Nation(国籍)、Rating(技能评分,45-99)、Market_Value(市场价值,以欧元为单位)、Scout_Report(AI生成的球探报告,描述球员的打法和潜力)。
创建时间:
2026-01-21
原始信息汇总
数据集概述
基本信息
- 数据集名称:AI-Powered Synthetic Soccer Scout Dataset
- 发布地址:https://huggingface.co/datasets/yonaitay/Scouter-ai-dataset
- 数据规模:包含20,000个独特的职业足球运动员合成档案。
- 数据文件:soccer_scout_data.csv
数据特征
数据集包含以下9个字段:
- Name:合成生成的球员姓名。
- Age:球员年龄,为17至38之间的整数。
- Position:球员位置,例如前锋、中后卫、守门员等。
- Team:球员所属俱乐部,分配自真实世界联赛。
- League:俱乐部所属的联赛。
- Nation:球员国籍。
- Rating:球员综合技能评分,范围为45至99。
- Market_Value:预估转会价值,以欧元格式表示。
- Scout_Report:由大型语言模型生成的单句球探报告,描述球员风格和潜力。
生成方法与技术栈
- 生成方法:使用Python、
Faker库以及大型语言模型(LLM)Qwen/Qwen2.5-0.5B-Instruct合成生成。 - 技术栈:
- 语言:Python
- 环境:Google Colab(需T4 GPU)
- 主要库:
transformers,torch,pandas,faker,accelerate,adjustText
- 核心逻辑:
- 采用定制算法,基于年龄、评分和潜力计算
Market_Value。 - 模拟真实世界人才分布,一级国家产生精英球员的概率更高。
- 采用定制算法,基于年龄、评分和潜力计算
探索性数据分析(EDA)内容
对合成数据进行了以下分析以验证其真实性并揭示趋势:
- 数据转换与基本检查:将原始Excel输出转换为CSV格式并进行完整性检查。
- IQR钟形曲线与异常值检测:使用四分位距方法可视化球员评分分布,识别“普通”球员与“异常值”。
- 国家效率分析:通过散点图分析各国球员数量与总市场价值的关系。
- 联赛实力排名:通过箱形图可视化不同联赛的球员技能分布,按评分中位数排序。
- 相关性热力图:分析年龄、评分与市场价值之间的数学相关性。
- 特征重要性分析:使用随机森林回归器,确定影响市场价值的主要特征。
嵌入模型评估与应用流程
- 嵌入模型评估:为给球探报告生成向量嵌入,举办了模型“锦标赛”,评估了三个模型在推理速度与语义质量上的平衡。根据加权效率得分(质量分占60%,速度分占40%),最终胜出模型为
paraphrase-MiniLM-L3-v2。 - 应用架构流程:基于该数据集的应用包含以下4步流程:
- 输入翻译:将用户输入的足球术语映射为标准化的数据集标签。
- 智能筛选:根据用户预算筛选符合财务约束的球员。
- 语义搜索:使用选定的MiniLM-L3嵌入模型,通过余弦相似度在数据库中查找与描述风格匹配的球员。
- 自动内容生成:使用动态模板引擎生成模拟记者风格的“突发新闻”推文。
相关资源
- 数据集卡片:https://huggingface.co/datasets/yonaitay/Scouter-ai-dataset
- 项目笔记本:存储库中的
Showcase_Notebook.ipynb文件包含完整的代码分析。
搜集汇总
数据集介绍
构建方式
在足球数据分析领域,合成数据集的构建为研究提供了可控且丰富的实验材料。Scouter-ai-dataset的构建过程融合了程序化生成与人工智能技术,首先生成20,000名虚拟职业球员的基本属性,包括姓名、年龄、位置、所属球队、联赛、国籍与技能评分。随后,通过定制算法依据年龄与评分动态计算市场价值,并引入分层技能分布逻辑模拟现实世界的人才分布格局。核心环节采用Qwen-2.5-0.5B-Instruct大型语言模型为每位球员生成独一无二的球探报告文本,确保了数据在统计规律与语义表达上的双重真实性。
特点
该数据集展现出多维度特征,其规模庞大且结构完整,覆盖了球员从基础属性到文本描述的全方位信息。数值字段经过精心设计,市场价值通过智能算法关联年龄与评分,呈现出符合足球经济规律的分布模式。文本字段则由先进语言模型生成,每份球探报告均具备语境感知能力,能够反映球员的技术特点与发展潜力。数据整体模拟了真实足球世界的层级结构,例如精英球员更可能出现在传统足球强国,不同联赛之间也存在明显的实力梯度差异,为量化分析提供了高度仿真的基础。
使用方法
数据集适用于自然语言处理、回归分析与数据可视化等多种研究场景。使用者可加载CSV文件,利用球员属性进行统计分析,例如探究年龄、评分与市场价值之间的相关性。球探报告文本字段可用于语义搜索或文本嵌入任务,通过计算余弦相似度来匹配特定风格的球员。此外,数据集内嵌的探索性分析示例展示了从异常值检测到特征重要性评估的完整流程,为后续的机器学习模型训练,如随机森林回归,提供了可直接参考的数据预处理与特征工程范式。
背景与挑战
背景概述
在体育数据分析与人工智能交叉领域,合成数据集正成为推动研究创新的关键工具。Scouter-ai-dataset由研究人员yonaitay于近期创建,旨在模拟职业足球运动员的全面档案,涵盖从基础属性到专业球探报告的多维度信息。该数据集的核心研究问题聚焦于如何利用大规模语言模型生成高质量、结构化的合成数据,以支持自然语言处理、回归分析与数据可视化等任务。通过整合真实世界联赛、国家队层级与智能估值逻辑,该数据集为足球人才评估、市场价值预测及语义搜索应用提供了基准资源,对体育科技与数据科学领域具有显著的参考价值。
当前挑战
该数据集致力于解决足球运动员评估与球探报告自动生成的复杂问题,其核心挑战在于如何确保合成数据的真实性与统计合理性,例如模拟球员评级与市场价值的关联性需符合现实足球经济规律。在构建过程中,研究人员面临多重技术挑战:一是利用有限参数规模的大型语言模型生成多样且上下文连贯的球探文本,需平衡生成效率与语义质量;二是设计分层技能分布与智能估值算法,以反映真实世界中不同国家与联赛的人才差异;三是通过嵌入模型锦标赛优化语义搜索流程,在计算速度与表征准确性之间寻求最佳权衡,确保应用端实时响应的可行性。
常用场景
经典使用场景
在体育数据分析领域,Scouter-ai-dataset以其大规模合成球员档案与AI生成的球探报告,为机器学习模型提供了丰富的训练与测试平台。该数据集常用于自然语言处理任务,例如通过语义搜索匹配球员风格描述,或进行回归分析以预测球员市场价值。其结构化属性与文本报告的结合,使得研究人员能够探索多模态学习框架,评估模型在理解足球专业术语与数值特征关联方面的性能。
实际应用
在实际应用中,Scouter-ai-dataset可服务于足球俱乐部的球探系统与转会策略制定。基于语义搜索的球员匹配功能,能够帮助球探快速识别符合特定战术风格的候选球员,而市场价值预测模型则辅助俱乐部进行财务规划与谈判。此外,该数据集生成的合成报告可用于自动化内容创作,例如模拟转会新闻的生成,为媒体与球迷互动提供即时、个性化的信息素材。
衍生相关工作
围绕该数据集衍生的经典工作主要集中在嵌入模型优化与多任务学习框架上。例如,通过举办嵌入模型锦标赛,比较不同模型在球探报告向量化中的效率与质量平衡,推动了轻量级模型在实时语义搜索中的应用。此外,结合随机森林回归器进行特征重要性分析的研究,进一步深化了球员价值驱动因素的可解释性探索,为后续的合成数据生成与体育分析工具开发提供了方法论参考。
以上内容由遇见数据集搜集并总结生成


