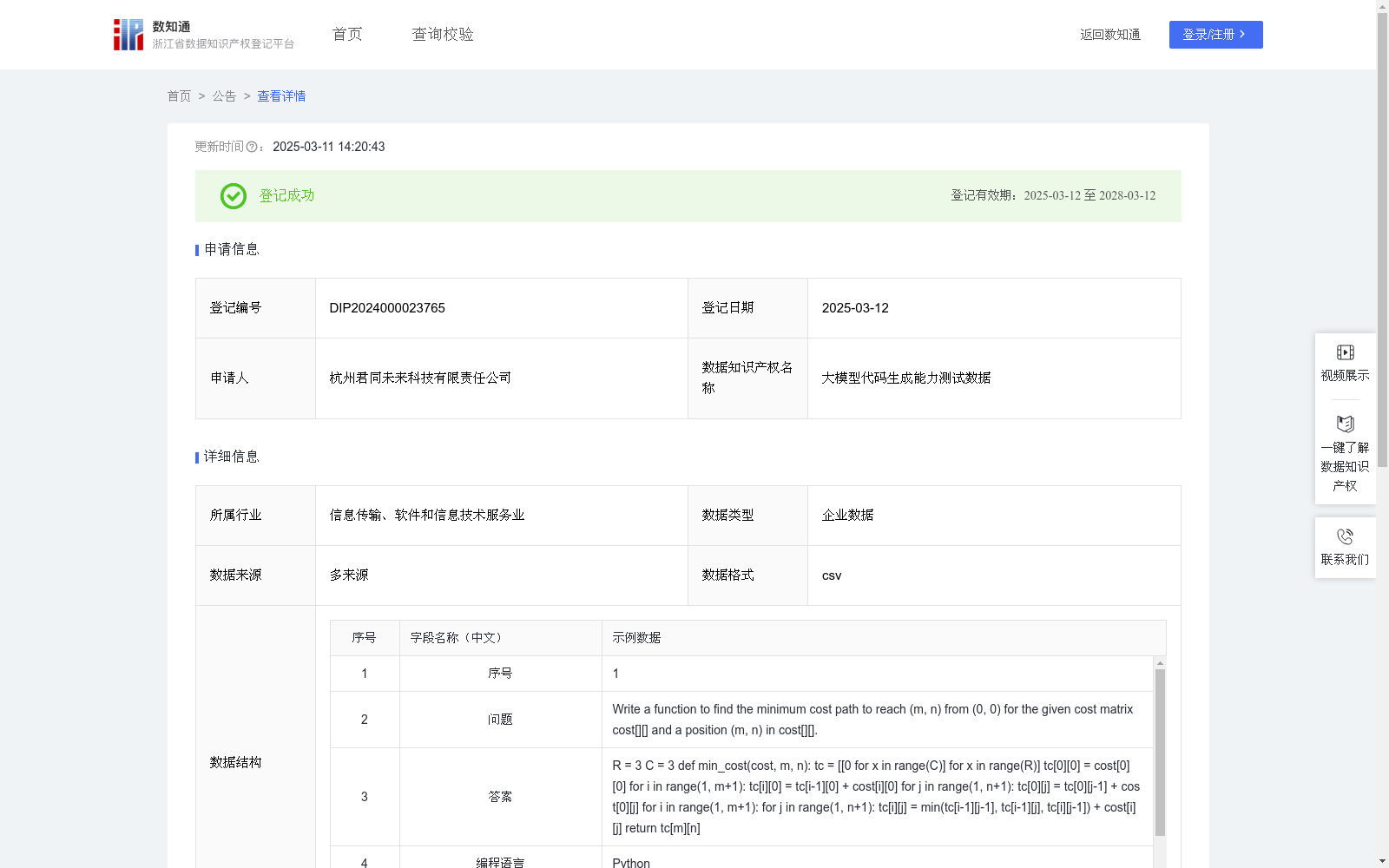
大模型代码生成能力测试数据
收藏浙江省数据知识产权登记平台2025-03-11 更新2025-03-12 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/116745
下载链接
链接失效反馈官方服务:
资源简介:
通过精心设计和多层次的数据加工流程,大模型代码生成能力测试数据集被构建为高质量、高标准化的评估集。这些数据涵盖了广泛的编程主题,包括算法设计、数据结构、面向对象编程、并发编程、代码优化、调试技巧等。代码生成能力测试数据集为大语言模型提供全面的编程能力测试素材,帮助了解模型在编写代码时的逻辑思维和实现能力。通过测试评估大模型的代码生成语言、快速提取需求、推导实现过程的能力,适应多样化应用场景,如软件开发、自动化测试、技术支持和代码审查等。本次评估的编程语言为Python、C++。(1) 数据来源:原始数据来源于公开编程题库、学术会议论文中的编程问题、在线编程学习平台的题目集合,以及人工设计的创新编程问题,并为数据添加来源。
(2) 数据标准化处理:对收集到的编程题目进行标准化处理,包括统一题目格式、语言规范化、变量定义标准化,以及排除歧义性描述,确保题目表达清晰、易于模型解析。
(3) 关键信息标注:为题目附加详细的标注信息,包括问题、答案、编程语言、回答类型、功能相似度等。标注的信息为模型的代码生成分析提供多层次验证依据。其中,功能相似度为生成的算法功能点与输入语料中的算法要求功能重合度。
(4) 问题改编与生成:基于基础题目集合,应用数据改编技术生成同类但具有不同表达形式的题目,例如对题目语言进行变换、数据替换、条件扩展。
(5) 测试指标设计:设计针对代码生成能力测试的多维评估指标,包括问题理解正确率、代码生成准确率、算法优化能力、代码风格规范性,以及对提示性问题和开放性问题的响应质量。
(6) 模型评估与验证:使用数据集对大模型进行全面评估,分析其在理解编程问题、生成有效代码及优化代码表现上的能力,并通过对比不同大模型的评估结果,形成对模型编程能力的系统性评价。
提供机构:
杭州君同未来科技有限责任公司
创建时间:
2024-12-23
搜集汇总
数据集介绍
特点
大模型代码生成能力测试数据集是一个包含1138条记录的企业数据集,格式为CSV,用于评估大语言模型在多种编程主题上的代码生成能力。数据集涵盖了Python和C++等编程语言,并通过标准化处理和关键信息标注确保数据质量,适用于软件开发、自动化测试等多样化应用场景。
以上内容由遇见数据集搜集并总结生成


