damlab/HIV_PI
收藏Hugging Face2022-03-09 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/damlab/HIV_PI
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
---
# Dataset Description
## Dataset Summary
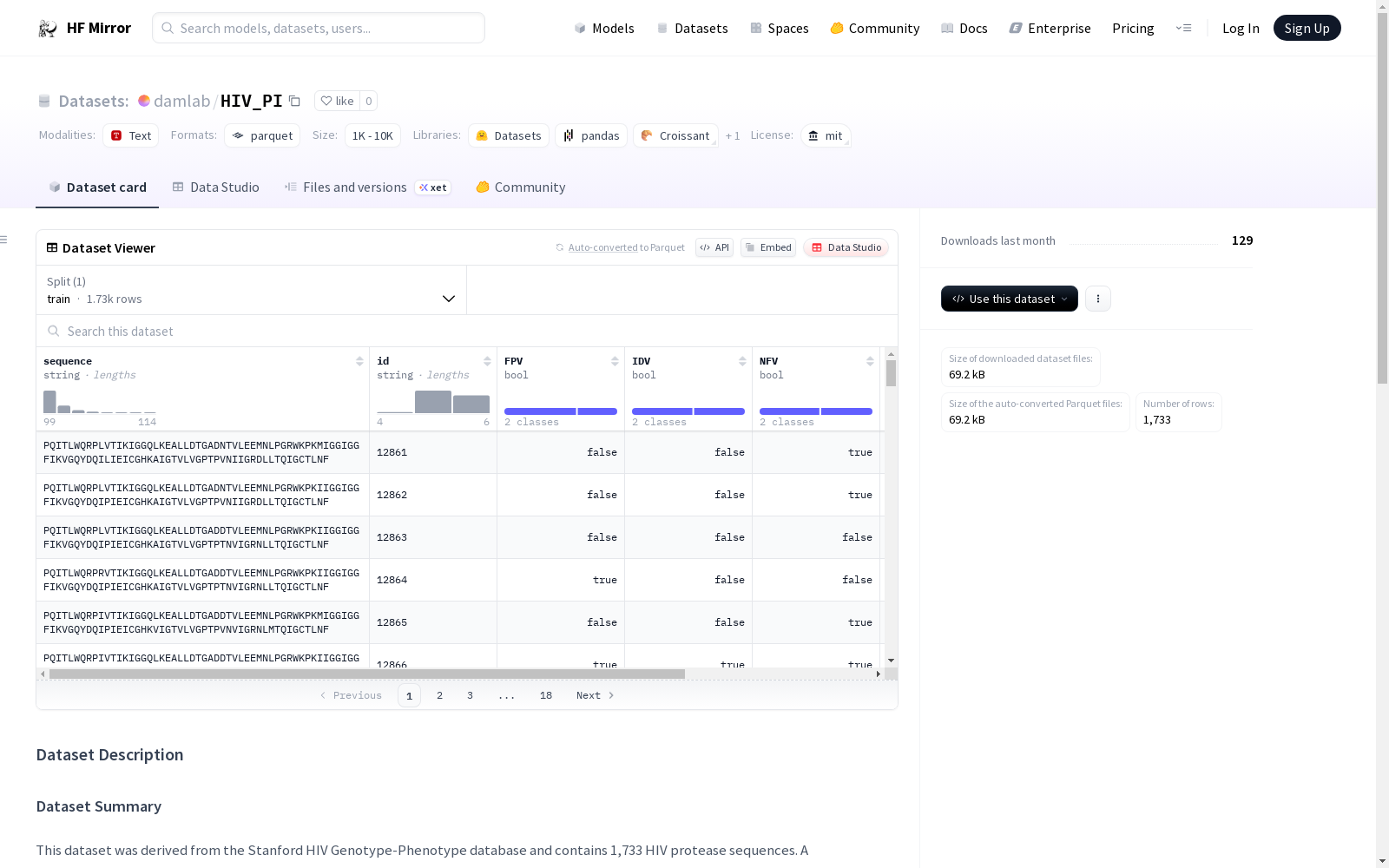
This dataset was derived from the Stanford HIV Genotype-Phenotype database and contains 1,733 HIV protease sequences. A
pproximately half of the sequences are resistant to at least one antiretroviral therapeutic (ART).
Supported Tasks and Leaderboards: None
Languages: English
## Dataset Structure
### Data Instances
Each column represents the protein amino acid sequence of the HIV protease protein. The ID field indicates the Genbank reference ID for future cross-referencing. There are 1,733 total protease sequences.
Data Fields: ID, sequence, fold, FPV, IDV, NFV, SQV
Data Splits: None
## Dataset Creation
Curation Rationale: This dataset was curated to train a model (HIV-BERT-PI) designed to predict whether an HIV protease sequence would result in resistance to certain antiretroviral (ART) drugs.
Initial Data Collection and Normalization: Dataset was downloaded and curated on 12/21/2021.
## Considerations for Using the Data
Social Impact of Dataset: Due to the tendency of HIV to mutate, drug resistance is a common issue when attempting to treat those infected with HIV.
Protease inhibitors are a class of drugs that HIV is known to develop resistance via mutations.
Thus, by providing a collection of protease sequences known to be resistant to one or more drugs, this dataset provides a significant collection of data that could be utilized to perform computational analysis of protease resistance mutations.
Discussion of Biases: Due to the sampling nature of this database, it is predominantly composed of subtype B sequences from North America and Europe with only minor contributions of Subtype C, A, and D.
Currently, there was no effort made to balance the performance across these classes.
As such, one should consider refinement with additional sequences to perform well on non-B sequences.
## Additional Information:
- Dataset Curators: Will Dampier
- Citation Information: TBA
许可证:MIT许可证
# 数据集描述
## 数据集摘要
本数据集源自斯坦福HIV基因型-表型数据库(Stanford HIV Genotype-Phenotype database),共包含1733条HIV蛋白酶序列,其中约半数序列对至少一种抗逆转录病毒治疗药物(antiretroviral therapeutic, ART)具有耐药性。
支持任务与排行榜:无
语言:英语
## 数据集结构
### 数据实例
每一列对应HIV蛋白酶(HIV protease)的蛋白质氨基酸序列。ID字段用于标注基因银行(GenBank)参考编号,以便后续交叉引用。本数据集共包含1733条蛋白酶序列。
数据字段:ID、序列(sequence)、fold、FPV、IDV、NFV、SQV
数据划分:无
## 数据集构建
### 整理依据
本数据集的整理旨在用于训练HIV-BERT-PI模型,该模型用于预测某条HIV蛋白酶序列是否会对特定抗逆转录病毒治疗(ART)药物产生耐药性。
初始数据收集与标准化处理:本数据集于2021年12月21日完成下载与整理。
## 数据使用注意事项
### 数据集社会影响
由于HIV具有高频突变特性,在治疗HIV感染者过程中,耐药性是常见问题。蛋白酶抑制剂是一类HIV可通过突变产生耐药性的药物。本数据集收录了已知对一种或多种药物具有耐药性的蛋白酶序列,可为蛋白酶耐药突变的计算分析提供高质量的研究数据资源。
### 偏差说明
受数据库采样方式限制,本数据集主要包含来自北美与欧洲的B亚型序列,仅少量收录C、A、D亚型序列。目前未针对各亚型类别进行性能均衡处理,因此在应用于非B亚型序列分析时,建议通过补充额外序列对数据集进行优化。
## 补充信息
- 数据集整理者:Will Dampier
- 引用信息:待补充(TBA)
提供机构:
damlab
原始信息汇总
数据集概述
数据集总结
该数据集源自斯坦福HIV基因型-表型数据库,包含1,733条HIV蛋白酶序列。约半数序列对至少一种抗逆转录病毒疗法(ART)具有抗药性。
数据集结构
数据实例
- 列信息:每列代表HIV蛋白酶蛋白的氨基酸序列。ID字段指示Genbank参考ID,用于未来交叉引用。
- 数据字段:ID, 序列, 折叠, FPV, IDV, NFV, SQV
- 总序列数:1,733
数据集创建
- 数据整理理由:用于训练HIV-BERT-PI模型,预测HIV蛋白酶序列对特定抗逆转录病毒药物的抗药性。
- 初始数据收集与规范化:数据集于2021年12月21日下载并整理。
使用数据时的考虑
- 社会影响:HIV的变异倾向导致药物抗性成为治疗感染者时的常见问题。本数据集提供了一组已知对一种或多种药物具有抗性的蛋白酶序列,可用于进行蛋白酶抗性突变的计算分析。
- 偏见讨论:数据集主要由北美和欧洲的B亚型序列组成,仅有少量C、A和D亚型序列。目前未对这些类别进行性能平衡,建议在使用时考虑加入更多序列以提高非B亚型序列的性能。
附加信息
- 数据集整理者:Will Dampier
- 引用信息:待定
搜集汇总
数据集介绍
构建方式
damlab/HIV_PI数据集的构建旨在为研究HIV蛋白酶抑制剂抗性提供数据支持。该数据集源自斯坦福大学HIV基因型-表型数据库,通过精心筛选,包含了1733条HIV蛋白酶氨基酸序列,其中约一半的序列对至少一种抗逆转录病毒疗法(ART)表现出抗性。数据集的构建过程涉及数据的下载、筛选和规范化,确保了数据的质量和可用性。
使用方法
使用damlab/HIV_PI数据集时,研究人员可以将其用于训练模型,以预测HIV蛋白酶序列对特定抗逆转录病毒药物的敏感性。由于数据集的构建目的明确,适用于药物抗性预测的相关计算分析。在使用过程中,应注意数据集的样本偏差,可能需要对数据集进行扩充或调整,以提高模型在非B亚型上的表现。
背景与挑战
背景概述
在艾滋病病毒(HIV)研究领域,药物耐药性是治疗过程中的一大挑战。damlab/HIV_PI数据集应运而生,其源自斯坦福大学HIV基因型-表型数据库,包含了1733条HIV蛋白酶序列,其中约一半的序列对至少一种抗逆转录病毒疗法(ART)表现出耐药性。该数据集的创建旨在训练一种名为HIV-BERT-PI的模型,以预测特定HIV蛋白酶序列是否会导致对某些抗逆转录病毒药物产生耐药性。数据集的构建时间为2021年12月21日,由数据科学家Will Dampier负责 curated,其对于理解HIV病毒变异和药物耐药性机制的研究具有重要的参考价值。
当前挑战
damlab/HIV_PI数据集在构建和应用过程中面临诸多挑战。首先,数据集在药物耐药性预测领域中的应用挑战在于,HIV病毒具有高度的变异性,导致耐药性成为一个动态变化的复杂问题。其次,在数据集构建过程中,由于样本采集的偏差,数据集主要包含来自北美和欧洲的B亚型序列,其他亚型序列较少,这可能导致模型在处理非B亚型序列时性能下降。因此,未来的研究需要在数据集的多样性和平衡性上进行改进,以提高模型的泛化能力和准确性。
常用场景
经典使用场景
在生物信息学领域,damlab/HIV_PI数据集以其独特的序列数据,成为研究HIV蛋白酶抑制剂耐药性的重要资源。该数据集的经典使用场景在于,研究者可利用其丰富的序列信息,通过机器学习模型预测HIV蛋白酶序列对特定抗逆转录病毒药物的耐药性,进而指导临床用药策略的制定。
解决学术问题
该数据集解决了学术界在HIV治疗过程中面临的耐药性问题。通过分析HIV蛋白酶的氨基酸序列,研究者能够识别出导致耐药性的关键突变,为开发新型抗病毒药物及个性化治疗方案提供了理论基础。这对于控制HIV传播、提高患者生存质量具有重要意义。
实际应用
在实际应用中,damlab/HIV_PI数据集助力于医疗健康领域,特别是对于HIV/AIDS的治疗。医生和研究人员可以借助该数据集,评估患者病毒株对现有药物的敏感性,从而优化治疗方案,减少耐药性的发生。
数据集最近研究
最新研究方向
在艾滋病病毒研究领域,damlab/HIV_PI数据集的构建与运用正推动着预测HIV蛋白酶抑制剂抗药性的研究走向深入。该数据集以其包含的1,733个HIV蛋白酶序列,特别是其中约一半的序列对至少一种抗逆转录病毒疗法具有抗药性,为科研工作者提供了宝贵的资源。当前,基于该数据集的研究主要集中在开发能够准确预测抗药性的模型,例如HIV-BERT-PI模型,这对于优化艾滋病治疗方案和克服药物抗性具有重要意义。此外,该数据集揭示了HIV病毒变异与药物抗性之间的复杂关系,为未来艾滋病治疗策略的制定提供了科学依据。
以上内容由遇见数据集搜集并总结生成


