jgov
收藏Hugging Face2025-09-16 更新2025-09-17 收录
下载链接:
https://huggingface.co/datasets/Silviase/jgov
下载链接
链接失效反馈官方服务:
资源简介:
e-Gov PDF Page Images with Text数据集包含了来自e-Gov Open Data门户的PDF文档的页面级渲染和提取的文本(非OCR)。文本是通过PDF的文本层提取的,没有嵌入文本的页面可能是空的。图像使用MuPDF以200 DPI渲染。该数据集遵循特定的生成规范,并使用CC-BY-4.0许可证。
创建时间:
2025-09-12
原始信息汇总
数据集概述:Silviase/jgov
基本信息
- 数据集名称:JA-eGov-OCR
- 许可证:CC-BY-4.0
- 语言:日语(ja)
- 任务类别:图像到文本(image-to-text)
- 标签:pdf、ocr
- 数据规模:100K<n<1M
数据内容
- 来源:日本电子政务开放数据门户(https://data.e-gov.go.jp/)
- 使用条款:https://data.e-gov.go.jp/info/terms
- 内容描述:包含从电子政务开放数据门户发布的PDF中提取的页面级渲染图像和文本(非OCR)
数据集结构
特征字段
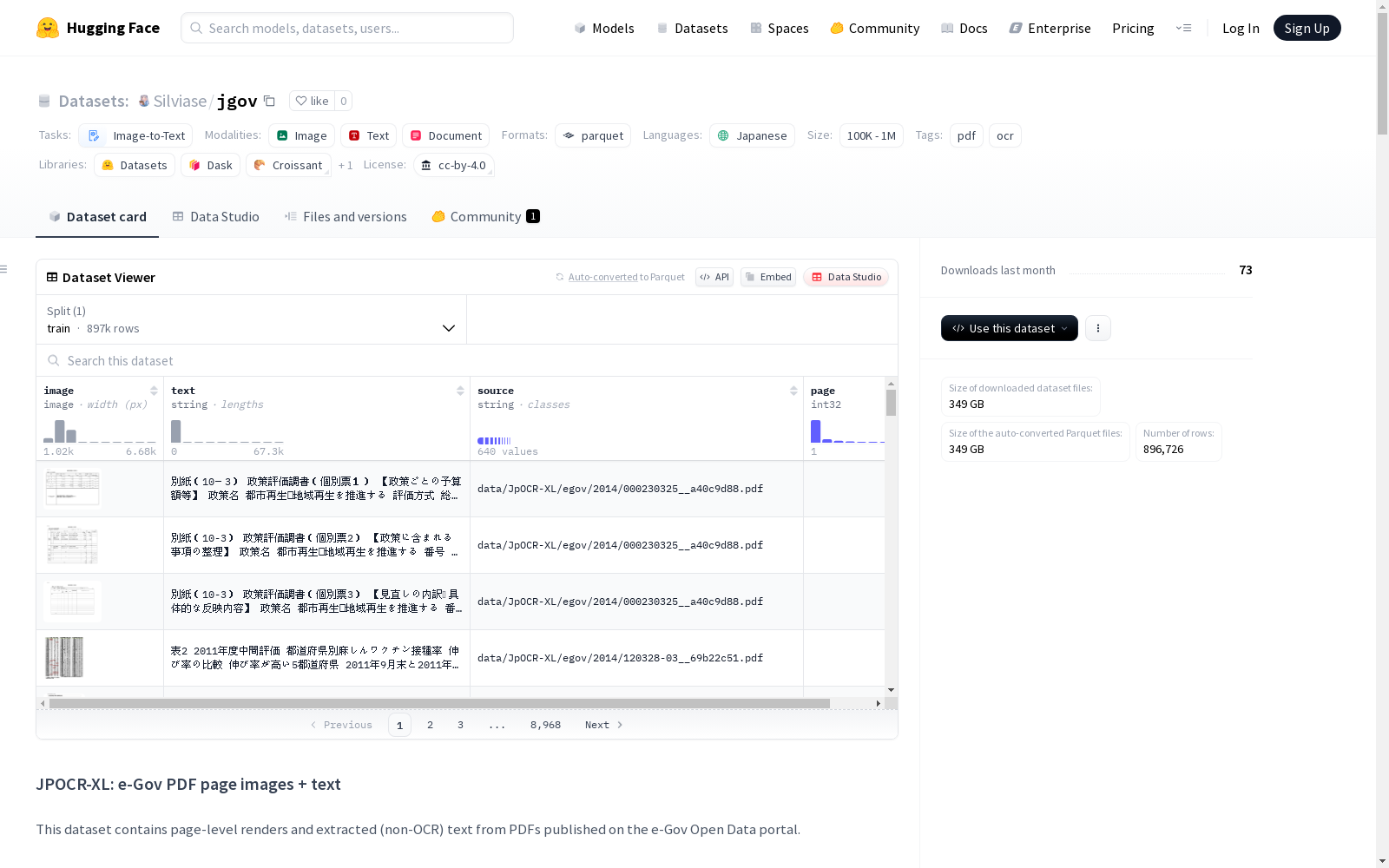
image:图像数据类型(datasets.Image())text:字符串类型(页面文本,可能为空)source:字符串类型(原始PDF路径)page:int32类型(页码,从1开始)
数据划分
- 训练集(train):
- 样本数量:896,726
- 数据大小:356,398,007,967.244字节
- 下载大小:349,404,229,020字节
数据生成规范
渲染规范
- 工具库:MuPDF(pymupdf/fitz)
- 分辨率:200 DPI(默认)
- 色彩模式:RGB(alpha=False)
- 输出格式:PNG图像(示例:_p0001.png)
文本提取
- 工具库:pdfplumber
- 方法:从PDF文本层提取(ToUnicode),不进行OCR处理
- 备注:无嵌入文本的页面将为空字符串
存储布局
- PDF文件:data/JpOCR-XL/egov/<年份>/*.pdf
- 页面图像:data/JpOCR-XL/egov/images/<年份>/<pdf_stem>/<pdf_stem>_p0001.png
- 本地数据集存储:data/JpOCR-XL/egov/dataset
许可和使用要求
- 原始许可证:CC-BY-4.0(需要署名)
- 再分发要求:必须注明出处(e-Gov Open Data)并保持CC-BY-4.0许可证
搜集汇总
数据集介绍
构建方式
该数据集源自日本政府开放数据门户(e-Gov),通过CKAN API系统检索PDF资源,采用自动化脚本精准抓取符合格式要求的文档。构建过程中运用MuPDF库以200 DPI分辨率将PDF页面渲染为RGB图像,同时通过pdfplumber库提取文本层内容,确保非OCR式原始文本保留。每份文档均遵循严格的文件命名规范,并附加哈希值以避免重复,最终整合为包含图像、文本、来源及页码的结构化数据。
特点
数据集涵盖近90万页日本政府公文图像与对应文本,呈现多元化的官方文档形态。其核心特征在于高质量的原生文本提取,避免了OCR可能引入的误差,同时保持文本与图像的精确对齐。所有数据均标注来源路径与页码信息,支持追溯至原始PDF文档。图像采用标准化200 DPI分辨率,兼顾视觉清晰度与存储效率,文本字段则完整保留政府公文的语言特征与格式细节。
使用方法
研究者可通过Hugging Face平台直接加载数据集,利用其图像-文本配对特性训练多模态模型。典型应用场景包括文档结构分析、日语自然语言处理任务以及跨模态检索系统开发。使用前需遵循CC-BY-4.0许可协议,明确标注数据来源自e-Gov开放平台。对于大规模处理需求,建议参考提供的生成脚本进行本地化重构,支持通过分步执行参数控制处理规模与输出格式。
背景与挑战
背景概述
日本电子政务开放数据平台(e-Gov)作为政府信息公开的重要载体,其PDF文档蕴含大量结构化与非结构化数据价值。JA-eGov-OCR数据集由Silviase团队于当代构建,专注于从e-Gov平台提取PDF页面图像与对应文本层内容,旨在推动日语文档分析与光学字符识别技术研究。该数据集通过MuPDF与pdfplumber工具链实现高精度渲染与文本提取,为多模态学习与文档数字化提供了规模化的基准资源,显著促进了公共部门文本挖掘与自然语言处理领域的交叉研究进展。
当前挑战
该数据集核心挑战在于解决日语文档复杂排版与文字混合场景下的精准文本提取问题,包括竖排文本、表格结构及手写体注释的识别困难。构建过程中需克服PDF文本层缺失导致的空文本问题,以及e-Gov平台CKAN API的异构数据检索限制,需通过多策略查询与动态格式验证确保数据完整性。此外,大规模PDF渲染的存储效率与版权合规性要求亦增加了技术实现复杂度。
常用场景
经典使用场景
在文档数字化处理领域,jgov数据集通过提供日本政府公开PDF文档的页面图像与对应文本,为光学字符识别技术研究提供了重要资源。该数据集典型应用于训练和评估多语言OCR模型,特别是针对日文文档的文本提取与识别任务,研究者可利用其大规模样本优化字符分割算法和布局分析模型。
实际应用
在实际应用中,jgov数据集支撑着政府档案数字化、历史文献保护等重要场景。基于该数据训练的模型已应用于日本行政文书自动化处理系统,大幅提升公文电子化效率,同时为法律文档检索系统和公共信息无障碍访问提供了技术基础。
衍生相关工作
该数据集催生了多项文档智能领域的创新研究,包括基于Transformer的日文文档结构分析模型GovDocBERT和跨模态检索系统JPDocRetriever。这些工作通过融合视觉与文本特征,推动了多模态预训练技术在东亚文字处理方面的前沿进展。
以上内容由遇见数据集搜集并总结生成


