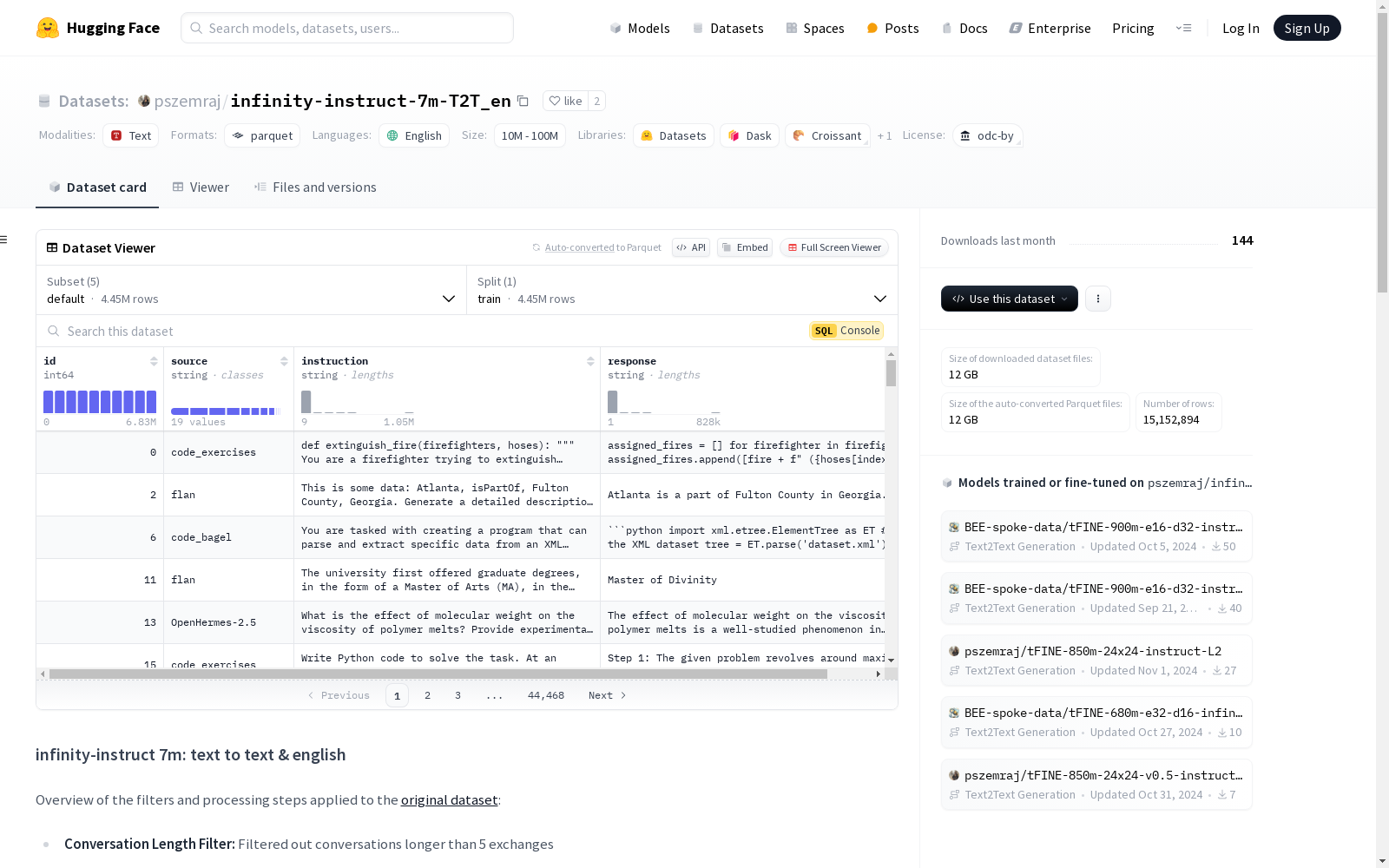
infinity-instruct-7m-T2T_en
收藏infinity-instruct 7m: text to text & english
数据集概述
语言和许可
- 语言:英语
- 许可:odc-by
数据集大小
- 大小范围:1M < n < 10M
数据集配置
配置:all
- 特征:
- id: int64
- source: string
- instruction: string
- response: string
- 分割:
- train:
- 字节数:6535504042.293433
- 示例数:5088189
- train:
- 下载大小:3698456025
- 数据集大小:6535504042.293433
配置:deduped-L1
- 特征:
- id: int64
- source: string
- instruction: string
- response: string
- 分割:
- train:
- 字节数:2830462741.1176167
- 示例数:1768972
- train:
- 下载大小:1617594800
- 数据集大小:2830462741.1176167
配置:deduped-L2
- 特征:
- id: int64
- source: string
- instruction: string
- response: string
- 分割:
- train:
- 字节数:1788639157.8823833
- 示例数:1117857
- train:
- 下载大小:954292977
- 数据集大小:1788639157.8823833
配置:default
- 特征:
- id: int64
- source: string
- instruction: string
- response: string
- 分割:
- train:
- 字节数:6045124855.509772
- 示例数:4506651
- train:
- 下载大小:3384546897
- 数据集大小:6045124855.509772
配置:en-deduped
- 特征:
- id: int64
- source: string
- instruction: string
- response: string
- 分割:
- train:
- 字节数:4619101899.0
- 示例数:2886829
- train:
- 下载大小:2581331059
- 数据集大小:4619101899.0
数据文件配置
-
配置:all
- 分割:train
- 路径:all/train-*
-
配置:deduped-L1
- 分割:train
- 路径:deduped-L1/train-*
-
配置:deduped-L2
- 分割:train
- 路径:deduped-L2/train-*
-
配置:default
- 分割:train
- 路径:data/train-*
-
配置:en-deduped
- 分割:train
- 路径:en-deduped/train-*
数据处理步骤
- 对话长度过滤:过滤掉超过5个交流的对话
- 语言检测过滤:使用默认的
language列移除非英语对话 - 指令-响应提取:从每个对话中提取第一个人类指令和相应的LLM响应
- 拒绝响应过滤:移除包含拒绝词(如“sorry”或“I cant”)的响应行(仅在第一句中)
- 语言复查:使用fasttext-langdetect进行另一次英语语言检查
- 词数过滤:移除少于3个词的响应(默认配置)
此外,还有一个en-deduped配置,使用minhash在response上进行去重,阈值为0.6
来源统计
响应中包含3个或更多词的来源统计(默认配置)
[(OpenHermes-2.5, 809467), (flan, 740331), (MetaMath, 686537), (code_exercises, 553399), (Orca-math-word-problems-200k, 397577), (code_bagel, 360434), (MathInstruct, 327734), (Subjective, 265090), (python-code-dataset-500k, 78278), (CodeFeedback, 75244), (instructional_code-search-net-python, 74101), (self-oss-instruct-sc2-exec-filter-50k, 48428), (Evol-Instruct-Code-80K, 31763), (CodeExercise-Python-27k, 27088), (code_instructions_122k_alpaca_style, 13333), (Code-Instruct-700k, 10859), (Glaive-code-assistant-v3, 8935), (Python-Code-23k-ShareGPT, 2272), (python_code_instructions_18k_alpaca, 1848)]
所有来源统计
[(flan, 1307829), (OpenHermes-2.5, 820335), (MetaMath, 686537), (code_exercises, 553445), (Orca-math-word-problems-200k, 397579), (code_bagel, 360467), (MathInstruct, 327745), (Subjective, 267898), (python-code-dataset-500k, 78294), (CodeFeedback, 75273), (instructional_code-search-net-python, 74104), (self-oss-instruct-sc2-exec-filter-50k, 48428), (Evol-Instruct-Code-80K, 31932), (CodeExercise-Python-27k, 27088), (code_instructions_122k_alpaca_style, 13390), (Code-Instruct-700k, 10859), (Glaive-code-assistant-v3, 8935), (Python-Code-23k-ShareGPT, 2272), (python_code_instructions_18k_alpaca, 1850)]