CohereForAI/xP3x
收藏Hugging Face2024-04-10 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/CohereForAI/xP3x
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators:
- expert-generated
- crowdsourced
language:
- af
- ar
- az
- be
- bg
- bn
- br
- bs
- ca
- ch
- cs
- cv
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fo
- fr
- fy
- ga
- gd
- gl
- gn
- he
- hi
- hr
- hu
- hy
- ia
- id
- ie
- io
- is
- it
- ja
- jv
- ka
- kk
- km
- ko
- ku
- kw
- la
- lb
- lt
- lv
- mi
- mk
- ml
- mn
- mr
- ms
- mt
- my
- nb
- nl
- nn
- 'no'
- oc
- pl
- pt
- qu
- rn
- ro
- ru
- sh
- sl
- sq
- sr
- sv
- sw
- ta
- te
- th
- tk
- tl
- tr
- tt
- ug
- uk
- ur
- uz
- vi
- vo
- yi
- zh
- ace
- acm
- acq
- aeb
- af
- ajp
- ak
- als
- am
- apc
- ar
- ars
- ary
- arz
- as
- ast
- awa
- ayr
- azb
- azj
- ba
- bm
- ban
- be
- bem
- bn
- bho
- bjn
- bo
- bs
- bug
- bg
- ca
- ceb
- cs
- cjk
- ckb
- crh
- cy
- da
- de
- dik
- dyu
- dz
- el
- en
- eo
- et
- eu
- ee
- fo
- fj
- fi
- fon
- fr
- fur
- fuv
- gaz
- gd
- ga
- gl
- gn
- gu
- ht
- ha
- he
- hi
- hne
- hr
- hu
- hy
- ig
- ilo
- id
- is
- it
- jv
- ja
- kab
- kac
- kam
- kn
- ks
- ka
- kk
- kbp
- kea
- khk
- km
- ki
- rw
- ky
- kmb
- kmr
- knc
- kg
- ko
- lo
- lij
- li
- ln
- lt
- lmo
- ltg
- lb
- lua
- lg
- luo
- lus
- lvs
- mag
- mai
- ml
- mar
- min
- mk
- mt
- mni
- mos
- mi
- my
- nl
- nn
- nb
- npi
- nso
- nus
- ny
- oc
- ory
- pag
- pa
- pap
- pbt
- pes
- plt
- pl
- pt
- prs
- quy
- ro
- rn
- ru
- sg
- sa
- sat
- scn
- shn
- si
- sk
- sl
- sm
- sn
- sd
- so
- st
- es
- sc
- sr
- ss
- su
- sv
- swh
- szl
- ta
- taq
- tt
- te
- tg
- tl
- th
- ti
- tpi
- tn
- ts
- tk
- tum
- tr
- tw
- tzm
- ug
- uk
- umb
- ur
- uzn
- vec
- vi
- war
- wo
- xh
- ydd
- yo
- yue
- zh
- zsm
- zu
programming_language:
- Java
- Python
- Jupyter-Notebook
license:
- apache-2.0
multilinguality:
- multilingual
pretty_name: xP3x
size_categories:
- 100M<n<1B
task_categories:
- other
---
# Dataset Card for xP3x
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Repository:** https://github.com/bigscience-workshop/xmtf
- **Paper:** [Crosslingual Generalization through Multitask Finetuning](https://arxiv.org/abs/2211.01786)
- **Point of Contact:** [Niklas Muennighoff](mailto:n.muennighoff@gmail.com)
### Dataset Summary
> xP3x (Crosslingual Public Pool of Prompts eXtended) is a collection of prompts & datasets across 277 languages & 16 NLP tasks. It contains all of xP3 + much more! It is used for training future contenders of mT0 & BLOOMZ at project Aya @[C4AI](https://cohere.for.ai/) 🧡
>
- **Creation:** The dataset can be recreated using instructions available [here](https://github.com/bigscience-workshop/xmtf#create-xp3) together with the file in this repository named `xp3x_create.py`. We provide this version to save processing time.
- **Languages:** 277
- **xP3 Dataset Family:**
<table>
<tr>
<th>Name</th>
<th>Explanation</th>
<th>Example models</th>
</tr>
<tr>
<td><a href=https://huggingface.co/datasets/Muennighoff/xP3x>xP3x</a></t>
<td>Mixture of 17 tasks in 277 languages with English prompts</td>
<td>WIP - Join us at Project Aya @<a href=https://cohere.for.ai/>C4AI</a> to help!</td>
</tr>
<tr>
<td><a href=https://huggingface.co/datasets/bigscience/xP3>xP3</a></t>
<td>Mixture of 13 training tasks in 46 languages with English prompts</td>
<td><a href=https://huggingface.co/bigscience/bloomz>bloomz</a> & <a href=https://huggingface.co/bigscience/mt0-xxl>mt0-xxl</a></td>
</tr>
<tr>
<td><a href=https://huggingface.co/datasets/bigscience/xP3mt>xP3mt</a></t>
<td>Mixture of 13 training tasks in 46 languages with prompts in 20 languages (machine-translated from English)</td>
<td><a href=https://huggingface.co/bigscience/bloomz-mt>bloomz-mt</a> & <a href=https://huggingface.co/bigscience/mt0-xxl-mt>mt0-xxl-mt</a></td>
</tr>
<tr>
<td><a href=https://huggingface.co/datasets/bigscience/xP3all>xP3all</a></t>
<td>xP3 + evaluation datasets adding an additional 3 tasks for a total of 16 tasks in 46 languages with English prompts</td>
<td></td>
</tr>
<tr>
<td><a href=https://huggingface.co/datasets/bigscience/xP3megds>xP3megds</a></t>
<td><a href=https://github.com/bigscience-workshop/Megatron-DeepSpeed>Megatron-DeepSpeed</a> processed version of xP3</td>
<td><a href=https://huggingface.co/bigscience/bloomz>bloomz</a></td>
</tr>
<tr>
<td><a href=https://huggingface.co/datasets/Muennighoff/P3>P3</a></t>
<td>Repreprocessed version of the English-only <a href=https://huggingface.co/datasets/bigscience/P3>P3</a> with 8 training tasks</td>
<td><a href=https://huggingface.co/bigscience/bloomz-p3>bloomz-p3</a> & <a href=https://huggingface.co/bigscience/mt0-xxl-p3>mt0-xxl-p3</a></td>
</tr>
</table>
## Dataset Structure
### Data Instances
An example looks as follows:
```json
{
'inputs': '11月、遂にクロームはファイヤーフォックスを引き離し始めた。_はインターネットユーザーの評価が高まったのだ。\nReplace the _ in the above sentence with the correct option: \n- ファイヤーフォックス\n- クローム',
'targets': 'クローム',
'language': 'jpn_Jpan',
'split': 'test',
'template': 'Replace',
'dataset': 'Muennighoff/xwinograd',
'config': 'jp'
}
```
### Data Fields
The data fields are the same among all splits:
- `inputs`: the natural language input fed to the model
- `targets`: the natural language target that the model has to generate
- `language`: The language code. The codes are an extension of the FLORES-200 codes, where the first part is the language code and the second part the script code.
- `template`: The name of the prompt used.
- `dataset`: The Hugging Face dataset identifier of where the data stems from.
- `config`: The config of the Hugging Face dataset.
### Usage
The dataset has 680 gigabytes and 530 million samples. You may want to filter it and then deduplicate depending on your needs.
Loading by language:
```python
# pip install -q datasets
from datasets import load_dataset
ds = load_dataset("Muennighoff/xP3x", "zho_Hans", streaming=True) # Use streaming to not download all at once
for x in ds["train"]:
print(x)
break
```
You can then filter down by the data fields to e.g. only get certain configs or datasets.
As every dataset-config-template is its own jsonl file, you can also decide on the datasets, configs and templates you want and only download them.
For example, to download all Japanese xwinograd samples, you could do:
```python
# pip install -q datasets
from datasets import load_dataset
import multiprocessing
# pip install --upgrade huggingface-hub
from huggingface_hub import HfFileSystem, hf_hub_url
fs = HfFileSystem()
fps = fs.glob(f"datasets/CohereForAI/xP3x/data/jpn_Jpan/*xwinograd*")
resolved_paths = [fs.resolve_path(file) for file in fps]
data_files = [hf_hub_url(resolved_path.repo_id, resolved_path.path_in_repo, repo_type=resolved_path.repo_type) for resolved_path in resolved_paths]
ds = load_dataset("json", data_files=data_files, num_proc=8)["train"]
```
Sometimes it may be faster to clone the entire repo. To download all English files, you could do e.g.
```bash
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/datasets/CohereForAI/xP3x
cd xP3x
git lfs pull --include="data/eng_Latn/*"
```
### Data Splits
|Language|Code|Kilobytes|%|Samples|%|
|--------|------:|------:|-:|---:|-:|
|Emilian|egl_Latn|104|0.0|402|0.0|
|Swiss German|gsw_Latn|104|0.0|408|0.0|
|Novial|nov_Latn|116|0.0|432|0.0|
|Ainu (Latin script)|ain_Latn|120|0.0|410|0.0|
|Chamorro|cha_Latn|120|0.0|452|0.0|
|Gothic|got_Goth|120|0.0|402|0.0|
|Prussian|prg_Latn|120|0.0|424|0.0|
|Picard|pcd_Latn|140|0.0|530|0.0|
|Northern Frisian|frr_Latn|156|0.0|554|0.0|
|Uzbek (Latin script)|uzb_Latn|156|0.0|600|0.0|
|Ottoman Turkish (Latin script)|ota_Latn|188|0.0|632|0.0|
|Swahili (macrolanguage)|swa_Latn|212|0.0|772|0.0|
|Talossan|tzl_Latn|220|0.0|836|0.0|
|Kven Finnish|fkv_Latn|260|0.0|910|0.0|
|Zaza|zza_Latn|260|0.0|1,056|0.0|
|Frisian|fry_Latn|268|0.0|956|0.0|
|Piemontese|pms_Latn|276|0.0|998|0.0|
|Kalmyk|xal_Cyrl|288|0.0|976|0.0|
|Hunsrik|hrx_Latn|352|0.0|1,380|0.0|
|Romany|rom_Latn|364|0.0|1,410|0.0|
|Ancient Greek (to 1453)|grc_Grek|392|0.0|1,226|0.0|
|Tase Naga|nst_Latn|424|0.0|1,608|0.0|
|Albanian|sqi_Latn|596|0.0|2,216|0.0|
|Guadeloupean Creole French|gcf_Latn|608|0.0|2,326|0.0|
|Yakut|sah_Cyrl|608|0.0|1,986|0.0|
|Ho (Latin script)|hoc_Latn|632|0.0|2,634|0.0|
|Khasi|kha_Latn|676|0.0|2,664|0.0|
|Algerian Arabic|arq_Arab|688|0.0|2,278|0.0|
|Lower Sorbian|dsb_Latn|692|0.0|2,596|0.0|
|Chuvash|chv_Cyrl|716|0.0|2,446|0.0|
|Old Russian|orv_Cyrl|752|0.0|2,586|0.0|
|Pampanga|pam_Latn|784|0.0|2,984|0.0|
|Kurdish (Latin script)|kur_Latn|796|0.0|3,050|0.0|
|Ottoman Turkish|ota_Arab|832|0.0|2,772|0.0|
|Kotava|avk_Latn|864|0.0|3,118|0.0|
|Upper Sorbian|hsb_Latn|900|0.0|3,474|0.0|
|Buryat|bua_Cyrl|924|0.0|3,218|0.0|
|Swabian|swg_Latn|996|0.0|3,366|0.0|
|Coastal Kadazan|kzj_Latn|1,136|0.0|3,766|0.0|
|Chavacano|cbk_Latn|1,352|0.0|4,994|0.0|
|Quechua|que_Latn|1,704|0.0|5,312|0.0|
|Lingua Franca Nova (Cyrillic script)|lfn_Cyrl|1,740|0.0|5,458|0.0|
|Gronings|gos_Latn|1,864|0.0|7,462|0.0|
|Volapük|vol_Latn|1,948|0.0|7,712|0.0|
|Yue Chinese (Simplified)|yue_Hans|2,300|0.0|7,872|0.0|
|Mari (Russia)|chm_Cyrl|2,540|0.0|7,496|0.0|
|Kadazan Dusun|dtp_Latn|2,548|0.0|8,892|0.0|
|Breton|bre_Latn|3,048|0.0|11,868|0.0|
|Ladino|lad_Latn|3,224|0.0|11,916|0.0|
|Cornish|cor_Latn|3,492|0.0|13,880|0.0|
|Interlingue|ile_Latn|3,700|0.0|14,468|0.0|
|Wu Chinese|wuu_Hans|3,784|0.0|13,062|0.0|
|Japanese (Katakana)|jpn_Kana|4,208|0.0|13,942|0.0|
|Ido|ido_Latn|6,180|0.0|23,742|0.0|
|Yiddishi|yid_Hebr|9,896|0.0|34,412|0.01|
|Klingon|tlh_Latn|11,716|0.0|46,010|0.01|
|Lingua Franca Nova|lfn_Latn|13,328|0.0|46,826|0.01|
|Lojban|jbo_Latn|17,468|0.0|66,694|0.01|
|Low German|nds_Latn|18,364|0.0|68,098|0.01|
|Interlingua (International Auxiliary Language Association)|ina_Latn|25,700|0.0|76,584|0.01|
|Java|java|25,904|0.0|13,551|0.0|
|Japanese (Kanji)|jpn_Hani|26,292|0.0|89,978|0.02|
|Norwegian|nor_Latn|26,724|0.0|93,116|0.02|
|Toki Pona|toki_Latn|26,808|0.0|97,170|0.02|
|Latin|lat_Latn|28,900|0.0|101,390|0.02|
|Serbo-Croatian|hbs_Latn|29,452|0.0|105,748|0.02|
|Nigerian Pidgin|pcm_Latn|145,872|0.02|88,992|0.02|
|Azerbaijani (South or North; Latin script)|aze_Latn|147,564|0.02|77,875|0.01|
|Serbian (Latin script)|srp_Latn|179,072|0.03|131,101|0.02|
|Japanese (Hiragana)|jpn_Hira|188,944|0.03|628,758|0.12|
|Berber (Latin script)|ber_Latn|201,464|0.03|693,602|0.13|
|Jupyter Notebook|jupyter_notebook|416,056|0.06|400,000|0.08|
|Yue Chinese|yue_Hant|613,352|0.09|1,227,429|0.23|
|Haitian Creole|hat_Latn|629,420|0.09|1,228,281|0.23|
|Mossi|mos_Latn|630,416|0.09|1,223,481|0.23|
|Pangasinan|pag_Latn|630,684|0.09|1,223,481|0.23|
|Twi|twi_Latn|631,172|0.09|1,223,481|0.23|
|Bosnian|bos_Latn|633,016|0.09|1,224,479|0.23|
|Ewe|ewe_Latn|633,292|0.09|1,223,481|0.23|
|Bambara|bam_Latn|634,520|0.09|1,223,481|0.23|
|Javanese|jav_Latn|635,248|0.09|1,224,003|0.23|
|Southwestern Dinka|dik_Latn|635,416|0.09|1,223,481|0.23|
|Kabuverdianu|kea_Latn|636,144|0.09|1,223,481|0.23|
|Dyula|dyu_Latn|636,464|0.09|1,223,481|0.23|
|Venetian|vec_Latn|637,412|0.09|1,223,481|0.23|
|Chokwe|cjk_Latn|637,532|0.09|1,223,481|0.23|
|Latgalian|ltg_Latn|637,612|0.09|1,223,481|0.23|
|Sundanese|sun_Latn|638,120|0.09|1,223,481|0.23|
|Asturian|ast_Latn|638,708|0.09|1,223,481|0.23|
|Akan|aka_Latn|639,648|0.09|1,223,481|0.23|
|Mizo|lus_Latn|639,680|0.09|1,223,481|0.23|
|Guarani|grn_Latn|641,540|0.09|1,225,647|0.23|
|Limburgish|lim_Latn|642,368|0.09|1,223,481|0.23|
|Faroese|fao_Latn|642,432|0.09|1,224,067|0.23|
|Buginese|bug_Latn|643,472|0.09|1,223,481|0.23|
|Sango|sag_Latn|643,596|0.09|1,223,481|0.23|
|Luba-Kasai|lua_Latn|643,640|0.09|1,223,481|0.23|
|Papiamento|pap_Latn|643,648|0.09|1,223,481|0.23|
|Silesian|szl_Latn|644,608|0.09|1,223,481|0.23|
|Sicilian|scn_Latn|645,636|0.1|1,223,481|0.23|
|Kimbundu|kmb_Latn|645,964|0.1|1,223,481|0.23|
|Basque|eus_Latn|646,084|0.1|1,246,877|0.23|
|Balinese|ban_Latn|646,408|0.1|1,223,481|0.23|
|Norwegian Nynorsk|nno_Latn|646,996|0.1|1,229,699|0.23|
|Central Aymara|ayr_Latn|647,236|0.1|1,223,481|0.23|
|Tamasheq (Latin script)|taq_Latn|648,656|0.1|1,223,481|0.23|
|Kikongo|kon_Latn|648,992|0.1|1,223,481|0.23|
|Friulian|fur_Latn|649,272|0.1|1,223,481|0.23|
|Ayacucho Quechua|quy_Latn|649,992|0.1|1,223,481|0.23|
|Maori|mri_Latn|650,336|0.1|1,224,211|0.23|
|Icelandic|isl_Latn|650,372|0.1|1,246,623|0.23|
|Galician|glg_Latn|652,088|0.1|1,233,291|0.23|
|Catalan|cat_Latn|652,116|0.1|1,241,381|0.23|
|Lombard|lmo_Latn|652,120|0.1|1,223,481|0.23|
|Banjar (Latin script)|bjn_Latn|652,372|0.1|1,223,481|0.23|
|Fijian|fij_Latn|652,796|0.1|1,223,481|0.23|
|Crimean Tatar|crh_Latn|653,920|0.1|1,223,895|0.23|
|Northern Kurdish|kmr_Latn|654,108|0.1|1,223,481|0.23|
|Ligurian|lij_Latn|654,432|0.1|1,223,481|0.23|
|Occitan|oci_Latn|655,676|0.1|1,227,945|0.23|
|Turkmen|tuk_Latn|658,672|0.1|1,241,205|0.23|
|Luxembourgish|ltz_Latn|658,768|0.1|1,225,339|0.23|
|Cebuano|ceb_Latn|659,124|0.1|1,226,039|0.23|
|Samoan|smo_Latn|659,704|0.1|1,223,481|0.23|
|Sardinian|srd_Latn|660,000|0.1|1,223,481|0.23|
|Bemba|bem_Latn|660,504|0.1|1,223,481|0.23|
|Minangkabau (Latin script)|min_Latn|660,672|0.1|1,223,481|0.23|
|Acehnese (Latin script)|ace_Latn|661,084|0.1|1,223,481|0.23|
|Ilocano|ilo_Latn|661,184|0.1|1,227,663|0.23|
|Irish|gle_Latn|661,660|0.1|1,227,357|0.23|
|Fon|fon_Latn|663,124|0.1|1,223,481|0.23|
|Waray|war_Latn|664,120|0.1|1,226,503|0.23|
|Norwegian Bokmål|nob_Latn|666,240|0.1|1,300,607|0.24|
|Tosk Albanian|als_Latn|666,692|0.1|1,223,481|0.23|
|Standard Malay|zsm_Latn|667,088|0.1|1,270,715|0.24|
|Southern Sotho|sot_Latn|667,728|0.1|1,223,481|0.23|
|Kabyle|kab_Latn|668,128|0.1|1,346,605|0.25|
|Jingpho|kac_Latn|669,464|0.1|1,223,481|0.23|
|Lingala|lin_Latn|670,428|0.1|1,323,481|0.25|
|Wolof|wol_Latn|670,568|0.1|1,373,481|0.26|
|Central Kanuri (Latin script)|knc_Latn|670,800|0.1|1,223,481|0.23|
|Kikuyu|kik_Latn|672,096|0.1|1,223,481|0.23|
|Tok Pisin|tpi_Latn|672,916|0.1|1,223,481|0.23|
|Nuer|nus_Latn|673,632|0.1|1,223,481|0.23|
|Tagalog|tgl_Latn|673,684|0.1|1,247,417|0.23|
|Tumbuka|tum_Latn|676,948|0.1|1,223,481|0.23|
|Plateau Malagasy|plt_Latn|677,852|0.1|1,223,481|0.23|
|Afrikaans|afr_Latn|679,164|0.1|1,337,091|0.25|
|North Azerbaijani|azj_Latn|679,820|0.1|1,223,481|0.23|
|Kabiyè|kbp_Latn|684,880|0.1|1,223,481|0.23|
|Modern Standard Arabic (Romanized)|arb_Latn|685,408|0.1|1,223,481|0.23|
|Scottish Gaelic|gla_Latn|708,620|0.1|1,243,627|0.23|
|Sindhi|snd_Arab|718,680|0.11|1,223,481|0.23|
|North Levantine Arabic|apc_Arab|720,048|0.11|1,223,481|0.23|
|Tunisian Arabic|aeb_Arab|720,360|0.11|1,223,481|0.23|
|South Levantine Arabic|ajp_Arab|720,488|0.11|1,223,481|0.23|
|Dari|prs_Arab|720,500|0.11|1,223,481|0.23|
|Moroccan Arabic|ary_Arab|722,904|0.11|1,223,481|0.23|
|Egyptian Arabic|arz_Arab|723,356|0.11|1,223,481|0.23|
|Najdi Arabic|ars_Arab|725,784|0.11|1,223,481|0.23|
|Acehnese (Arabic script)|ace_Arab|726,272|0.11|1,223,481|0.23|
|Mesopotamian Arabic|acm_Arab|728,472|0.11|1,223,481|0.23|
|Ta’izzi-Adeni Arabic|acq_Arab|734,780|0.11|1,223,481|0.23|
|South Azerbaijani|azb_Arab|735,728|0.11|1,223,481|0.23|
|Central Kanuri (Arabic script)|knc_Arab|746,936|0.11|1,223,481|0.23|
|Rundi|run_Latn|749,792|0.11|1,296,111|0.24|
|Banjar (Arabic script)|bjn_Arab|751,112|0.11|1,223,481|0.23|
|Central Kurdish|ckb_Arab|756,804|0.11|1,223,481|0.23|
|Bashkir|bak_Cyrl|758,816|0.11|1,223,481|0.23|
|Kashmiri (Arabic script)|kas_Arab|759,140|0.11|1,223,481|0.23|
|Tatar|tat_Cyrl|764,212|0.11|1,247,685|0.23|
|Minangkabau (Arabic script)|min_Arab|765,384|0.11|1,223,481|0.23|
|Kazakh|kaz_Cyrl|766,176|0.11|1,232,697|0.23|
|Halh Mongolian|khk_Cyrl|776,384|0.11|1,224,353|0.23|
|Tajik|tgk_Cyrl|780,452|0.11|1,223,481|0.23|
|Eastern Yiddish|ydd_Hebr|781,452|0.12|1,223,481|0.23|
|Uyghur|uig_Arab|785,444|0.12|1,256,999|0.24|
|Armenian|hye_Armn|789,952|0.12|1,228,171|0.23|
|Hebrew|heb_Hebr|793,144|0.12|1,604,365|0.3|
|Belarusian|bel_Cyrl|806,588|0.12|1,261,197|0.24|
|Macedonian|mkd_Cyrl|813,436|0.12|1,384,567|0.26|
|Welsh|cym_Latn|821,036|0.12|1,321,455|0.25|
|Northern Uzbek|uzn_Latn|835,560|0.12|1,273,404|0.24|
|Central Atlas Tamazight|tzm_Tfng|843,508|0.12|1,223,481|0.23|
|Tamasheq (Tifinagh script)|taq_Tfng|848,104|0.12|1,223,481|0.23|
|Magahi|mag_Deva|851,360|0.13|1,223,481|0.23|
|Bhojpuri|bho_Deva|854,848|0.13|1,223,481|0.23|
|Awadhi|awa_Deva|857,096|0.13|1,224,037|0.23|
|Chhattisgarhi|hne_Deva|859,332|0.13|1,223,481|0.23|
|Kyrgyz|kir_Cyrl|860,700|0.13|1,250,163|0.23|
|Maithili|mai_Deva|863,476|0.13|1,223,481|0.23|
|Assamese|asm_Beng|865,904|0.13|1,223,481|0.23|
|Kashmiri (Devanagari script)|kas_Deva|867,232|0.13|1,223,481|0.23|
|Sanskrit|san_Deva|879,236|0.13|1,223,481|0.23|
|Lao|lao_Laoo|888,240|0.13|1,223,481|0.23|
|Odia|ory_Orya|890,508|0.13|1,223,481|0.23|
|Santali|sat_Olck|902,300|0.13|1,223,481|0.23|
|Kannada|kan_Knda|909,260|0.13|1,223,481|0.23|
|Meitei (Bengali script)|mni_Beng|917,984|0.14|1,223,481|0.23|
|Georgian|kat_Geor|928,712|0.14|1,226,729|0.23|
|Kamba|kam_Latn|936,468|0.14|2,136,615|0.4|
|Tigrinya|tir_Ethi|949,608|0.14|1,276,536|0.24|
|Swati|ssw_Latn|950,564|0.14|2,195,002|0.41|
|Malayalam|mal_Mlym|953,984|0.14|1,225,083|0.23|
|Nigerian Fulfulde|fuv_Latn|956,328|0.14|2,126,652|0.4|
|Umbundu|umb_Latn|974,104|0.14|2,264,553|0.43|
|Ganda|lug_Latn|975,780|0.14|2,273,481|0.43|
|Northern Sotho|nso_Latn|978,484|0.14|2,250,971|0.42|
|Khmer|khm_Khmr|984,756|0.14|1,227,825|0.23|
|Luo|luo_Latn|993,068|0.15|2,249,242|0.42|
|Standard Tibetan|bod_Tibt|993,732|0.15|1,223,481|0.23|
|Tswana|tsn_Latn|1,009,328|0.15|2,323,481|0.44|
|Kinyarwanda|kin_Latn|1,010,752|0.15|2,273,481|0.43|
|Sinhala|sin_Sinh|1,012,012|0.15|1,256,582|0.24|
|Xhosa|xho_Latn|1,019,804|0.15|2,323,481|0.44|
|Shona|sna_Latn|1,026,320|0.15|2,273,481|0.43|
|Esperanto|epo_Latn|1,029,444|0.15|2,612,083|0.49|
|Tsonga|tso_Latn|1,031,856|0.15|2,323,481|0.44|
|Dzongkha|dzo_Tibt|1,033,552|0.15|1,223,481|0.23|
|Zulu|zul_Latn|1,039,296|0.15|2,323,481|0.44|
|Serbian|srp_Cyrl|1,040,024|0.15|1,362,598|0.26|
|Nyanja|nya_Latn|1,061,780|0.16|2,323,481|0.44|
|Shan|shn_Mymr|1,074,940|0.16|1,223,481|0.23|
|Igbo|ibo_Latn|1,095,300|0.16|2,282,301|0.43|
|Hausa|hau_Latn|1,112,272|0.16|2,335,738|0.44|
|West Central Oromo|gaz_Latn|1,115,600|0.16|2,343,260|0.44|
|Nepali|npi_Deva|1,144,676|0.17|1,281,430|0.24|
|Yoruba|yor_Latn|1,164,540|0.17|2,334,801|0.44|
|Southern Pashto|pbt_Arab|1,170,840|0.17|1,365,533|0.26|
|Somali|som_Latn|1,198,320|0.18|2,482,437|0.47|
|Burmese|mya_Mymr|1,228,196|0.18|1,279,882|0.24|
|Amharic|amh_Ethi|1,261,128|0.19|1,980,215|0.37|
|Eastern Panjabi|pan_Guru|1,305,636|0.19|1,307,897|0.25|
|Gujarati|guj_Gujr|1,331,780|0.2|1,317,314|0.25|
|Marathi|mar_Deva|1,494,024|0.22|1,443,950|0.27|
|Bengali|ben_Beng|1,650,272|0.24|1,411,514|0.27|
|Chinese (Traditional)|zho_Hant|1,778,736|0.26|1,956,189|0.37|
|Tamil|tam_Taml|1,833,328|0.27|1,394,473|0.26|
|Swahili|swh_Latn|1,970,784|0.29|4,185,608|0.79|
|Telugu|tel_Telu|2,224,480|0.33|1,573,325|0.3|
|Ukrainian|ukr_Cyrl|2,227,616|0.33|2,216,119|0.42|
|Western Persian|pes_Arab|2,389,340|0.35|1,811,121|0.34|
|Turkish|tur_Latn|3,106,600|0.46|4,146,153|0.78|
|Urdu|urd_Arab|3,553,960|0.52|3,513,218|0.66|
|Korean|kor_Hang|4,642,468|0.68|3,415,920|0.64|
|Python|python|4,728,504|0.7|3,142,962|0.59|
|Japanese|jpn_Jpan|5,079,788|0.75|4,193,570|0.79|
|Thai|tha_Thai|6,860,704|1.01|4,666,299|0.88|
|Chinese (Simplified)|zho_Hans|8,063,684|1.19|7,355,509|1.38|
|Vietnamese|vie_Latn|8,398,824|1.24|6,194,925|1.16|
|Indonesian|ind_Latn|9,380,144|1.38|5,301,812|1.0|
|Hindi|hin_Deva|9,914,328|1.46|5,612,176|1.05|
|Croatian|hrv_Latn|10,028,028|1.48|5,583,975|1.05|
|Modern Standard Arabic|arb_Arab|11,051,064|1.63|7,232,551|1.36|
|Romanian|ron_Latn|11,441,636|1.68|5,594,927|1.05|
|Maltese|mlt_Latn|11,614,488|1.71|5,513,885|1.04|
|Slovenian|slv_Latn|12,014,912|1.77|5,533,689|1.04|
|Estonian|est_Latn|12,126,212|1.79|5,584,057|1.05|
|Lithuanian|lit_Latn|12,253,976|1.8|5,603,047|1.05|
|Slovak|slk_Latn|12,286,300|1.81|5,513,481|1.04|
|Standard Latvian|lvs_Latn|12,298,584|1.81|5,517,287|1.04|
|Polish|pol_Latn|12,409,684|1.83|5,868,631|1.1|
|Hungarian|hun_Latn|12,607,420|1.86|6,086,621|1.14|
|Russian|rus_Cyrl|13,110,908|1.93|8,798,927|1.65|
|Czech|ces_Latn|14,316,052|2.11|6,418,462|1.21|
|Bulgarian|bul_Cyrl|14,615,468|2.15|7,265,885|1.37|
|Swedish|swe_Latn|14,646,656|2.16|5,634,363|1.06|
|Finnish|fin_Latn|15,011,464|2.21|6,077,501|1.14|
|Danish|dan_Latn|16,136,612|2.38|5,831,109|1.1|
|Dutch|nld_Latn|22,387,020|3.3|8,992,864|1.69|
|Greek|ell_Grek|23,144,296|3.41|7,224,001|1.36|
|Italian|ita_Latn|23,952,824|3.53|9,967,738|1.87|
|Portuguese|por_Latn|27,297,252|4.02|11,242,808|2.11|
|German|deu_Latn|27,909,808|4.11|15,806,969|2.97|
|French|fra_Latn|28,428,608|4.18|16,365,984|3.08|
|Spanish|spa_Latn|30,969,580|4.56|16,315,928|3.07|
|English|eng_Latn|69,530,384|10.24|53,015,690|9.96|
|Total|-|679,318,704|100|532,107,156|100|
#### Language specifics
- `Japanese`: Data in `jpn_Hira`, `jpn_Kana`, `jpn_Hani` is guaranteed to have Hiragana, Katakana or Kanji, respectively in each sample. However, they may still include other styles. So while all samples in `jpn_Kana` are guaranteed to have Katakana, there may still be Hiragana or Kanji.
## Dataset Creation
### Source Data
#### Training datasets
- Code Miscellaneous
- [CodeComplex](https://huggingface.co/datasets/codeparrot/codecomplex)
- [Docstring Corpus](https://huggingface.co/datasets/teven/code_docstring_corpus)
- [GreatCode](https://huggingface.co/datasets/great_code)
- [State Changes](https://huggingface.co/datasets/Fraser/python-state-changes)
- Closed-book QA
- [Hotpot QA](https://huggingface.co/datasets/hotpot_qa)
- [Trivia QA](https://huggingface.co/datasets/trivia_qa)
- [Web Questions](https://huggingface.co/datasets/web_questions)
- [Wiki QA](https://huggingface.co/datasets/wiki_qa)
- Extractive QA
- [Adversarial QA](https://huggingface.co/datasets/adversarial_qa)
- [CMRC2018](https://huggingface.co/datasets/cmrc2018)
- [DRCD](https://huggingface.co/datasets/clue)
- [DuoRC](https://huggingface.co/datasets/duorc)
- [MLQA](https://huggingface.co/datasets/mlqa)
- [Quoref](https://huggingface.co/datasets/quoref)
- [ReCoRD](https://huggingface.co/datasets/super_glue)
- [ROPES](https://huggingface.co/datasets/ropes)
- [SQuAD v2](https://huggingface.co/datasets/squad_v2)
- [xQuAD](https://huggingface.co/datasets/xquad)
- TyDI QA
- [Primary](https://huggingface.co/datasets/khalidalt/tydiqa-primary)
- [Goldp](https://huggingface.co/datasets/khalidalt/tydiqa-goldp)
- Multiple-Choice QA
- [ARC](https://huggingface.co/datasets/ai2_arc)
- [C3](https://huggingface.co/datasets/c3)
- [CoS-E](https://huggingface.co/datasets/cos_e)
- [Cosmos](https://huggingface.co/datasets/cosmos)
- [DREAM](https://huggingface.co/datasets/dream)
- [MultiRC](https://huggingface.co/datasets/super_glue)
- [OpenBookQA](https://huggingface.co/datasets/openbookqa)
- [PiQA](https://huggingface.co/datasets/piqa)
- [QUAIL](https://huggingface.co/datasets/quail)
- [QuaRel](https://huggingface.co/datasets/quarel)
- [QuaRTz](https://huggingface.co/datasets/quartz)
- [QASC](https://huggingface.co/datasets/qasc)
- [RACE](https://huggingface.co/datasets/race)
- [SciQ](https://huggingface.co/datasets/sciq)
- [Social IQA](https://huggingface.co/datasets/social_i_qa)
- [Wiki Hop](https://huggingface.co/datasets/wiki_hop)
- [WiQA](https://huggingface.co/datasets/wiqa)
- Paraphrase Identification
- [MRPC](https://huggingface.co/datasets/super_glue)
- [PAWS](https://huggingface.co/datasets/paws)
- [PAWS-X](https://huggingface.co/datasets/paws-x)
- [QQP](https://huggingface.co/datasets/qqp)
- Program Synthesis
- [APPS](https://huggingface.co/datasets/codeparrot/apps)
- [CodeContests](https://huggingface.co/datasets/teven/code_contests)
- [JupyterCodePairs](https://huggingface.co/datasets/codeparrot/github-jupyter-text-code-pairs)
- [MBPP](https://huggingface.co/datasets/Muennighoff/mbpp)
- [NeuralCodeSearch](https://huggingface.co/datasets/neural_code_search)
- [XLCoST](https://huggingface.co/datasets/codeparrot/xlcost-text-to-code)
- Structure-to-text
- [Common Gen](https://huggingface.co/datasets/common_gen)
- [Wiki Bio](https://huggingface.co/datasets/wiki_bio)
- Sentiment
- [Amazon](https://huggingface.co/datasets/amazon_polarity)
- [App Reviews](https://huggingface.co/datasets/app_reviews)
- [IMDB](https://huggingface.co/datasets/imdb)
- [Rotten Tomatoes](https://huggingface.co/datasets/rotten_tomatoes)
- [Yelp](https://huggingface.co/datasets/yelp_review_full)
- Simplification
- [BiSECT](https://huggingface.co/datasets/GEM/BiSECT)
- Summarization
- [CNN Daily Mail](https://huggingface.co/datasets/cnn_dailymail)
- [Gigaword](https://huggingface.co/datasets/gigaword)
- [MultiNews](https://huggingface.co/datasets/multi_news)
- [SamSum](https://huggingface.co/datasets/samsum)
- [Wiki-Lingua](https://huggingface.co/datasets/GEM/wiki_lingua)
- [XLSum](https://huggingface.co/datasets/GEM/xlsum)
- [XSum](https://huggingface.co/datasets/xsum)
- Topic Classification
- [AG News](https://huggingface.co/datasets/ag_news)
- [DBPedia](https://huggingface.co/datasets/dbpedia_14)
- [TNEWS](https://huggingface.co/datasets/clue)
- [TREC](https://huggingface.co/datasets/trec)
- [CSL](https://huggingface.co/datasets/clue)
- Translation
- [Flores-200](https://huggingface.co/datasets/Muennighoff/flores200)
- [Tatoeba](https://huggingface.co/datasets/Helsinki-NLP/tatoeba_mt)
- [MultiEURLEX](https://huggingface.co/datasets/multi_eurlex)
- Word Sense disambiguation
- [WiC](https://huggingface.co/datasets/super_glue)
- [XL-WiC](https://huggingface.co/datasets/pasinit/xlwic)
- Natural Language Inference (NLI)
- [ANLI](https://huggingface.co/datasets/anli)
- [CB](https://huggingface.co/datasets/super_glue)
- [RTE](https://huggingface.co/datasets/super_glue)
- [XNLI](https://huggingface.co/datasets/xnli)
- Coreference Resolution
- [Winogrande](https://huggingface.co/datasets/winogrande)
- [XWinograd](https://huggingface.co/datasets/Muennighoff/xwinograd)
- Sentence Completion
- [COPA](https://huggingface.co/datasets/super_glue)
- [Story Cloze](https://huggingface.co/datasets/story_cloze)
- [XCOPA](https://huggingface.co/datasets/xcopa)
- [XStoryCloze](https://huggingface.co/datasets/Muennighoff/xstory_cloze)
#### Dataset specifics
- Flores-200: There are three prompts for Flores: `continuation`, `question`, `command`, which represent three commonly used prompting styles, i.e. making a prompt seem like a natural continuation, turning it into a question or commanding the model to do something.
- tatoeba_mt: Contains duplicates. For example, it has data that is both classified as `jpn_Kana` and `jpn_Jpan`, so you may want to deduplicate.
## Additional Information
### Licensing Information
The dataset collection is released under Apache 2.0. Note that individual datasets may have different licenses.
### Citation Information
```bibtex
@article{muennighoff2022crosslingual,
title={Crosslingual generalization through multitask finetuning},
author={Muennighoff, Niklas and Wang, Thomas and Sutawika, Lintang and Roberts, Adam and Biderman, Stella and Scao, Teven Le and Bari, M Saiful and Shen, Sheng and Yong, Zheng-Xin and Schoelkopf, Hailey and others},
journal={arXiv preprint arXiv:2211.01786},
year={2022}
}
```
### Contributions
Thanks to the contributors of [promptsource](https://github.com/bigscience-workshop/promptsource/graphs/contributors) for adding many prompts used in this dataset.
Thanks to the Aya team @[C4AI](https://cohere.for.ai/) 🧡
提供机构:
CohereForAI
原始信息汇总
数据集概述
- 名称: xP3x
- 语言: 支持277种语言,包括但不限于英语、中文、日语等。
- 编程语言: 支持Java、Python和Jupyter Notebook。
- 许可证: Apache-2.0
- 多语言性: 多语言支持
- 大小: 数据集大小介于100M至1B之间。
- 任务类别: 其他
数据集结构
- 数据实例: 每个实例包含输入、目标、语言、分割、模板、数据集来源和配置等字段。
- 数据字段: 包括输入、目标、语言代码、模板、数据集标识和配置。
- 数据分割: 数据按语言和代码分割,详细信息见README文件中的表格。
数据集创建
- 创建方式: 数据集可通过提供的
xp3x_create.py脚本和相关指令重新创建。 - 来源数据: 数据集包含多种来源,具体细节未在README中详细说明。
- 注释: 注释由专家生成和众包两种方式产生。
附加信息
- 许可证信息: 数据集遵循Apache-2.0许可证。
- 引用信息: 引用信息未在README中提供。
- 贡献: 贡献信息未在README中提供。
搜集汇总
数据集介绍
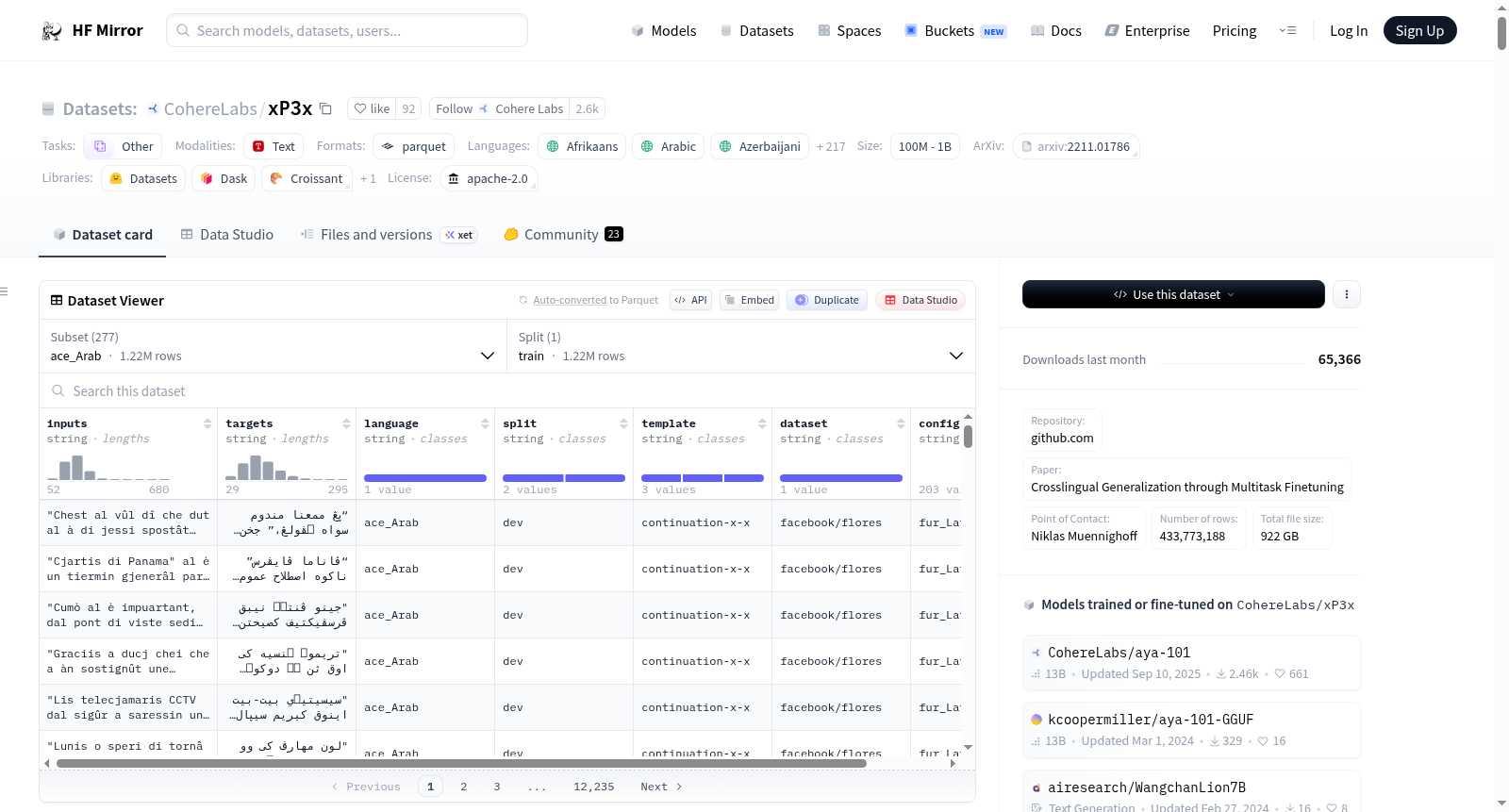
构建方式
在自然语言处理领域,多语言数据集对于推动模型泛化能力至关重要。xP3x数据集通过整合专家生成与大规模众包标注的方式构建,覆盖了超过一百种语言及多种文字体系,其数据规模介于亿级至十亿级之间。该数据集采用Apache 2.0开源协议,确保了数据的可访问性与使用的灵活性,为多语言任务提供了坚实的语料基础。
特点
xP3x数据集以其卓越的多语言覆盖能力脱颖而出,不仅囊括了英语、中文等主流语言,还涵盖了众多低资源语言及方言,如阿塞拜疆语、亚美尼亚语等。数据集进一步细化了语言变体,区分了不同文字体系,例如阿拉伯文、拉丁文、西里尔文等,这种精细划分有助于模型理解语言与文字间的复杂对应关系,为跨语言研究提供了丰富维度。
使用方法
研究人员可通过HuggingFace平台直接加载xP3x数据集,利用其预定义的配置项按语言或文字体系选择特定子集进行训练或评估。该数据集适用于多语言预训练、机器翻译、跨语言理解等多种任务,用户可结合Python等编程语言进行数据处理,通过灵活调用不同语言配置,深入探索模型在多样化语言环境下的性能表现。
背景与挑战
背景概述
在自然语言处理领域,多语言模型的训练长期受限于高质量平行语料的稀缺性,尤其是对于资源匮乏的语言。CohereForAI团队于2023年推出的xP3x数据集,正是为了应对这一挑战而构建。该数据集汇集了超过100种语言和多种编程语言的指令遵循数据,旨在通过跨语言任务统一格式,推动大规模多语言模型的指令微调研究。其核心研究问题聚焦于如何利用多样化语言数据提升模型的泛化能力和跨语言迁移性能,对促进语言技术的全球包容性具有深远影响。
当前挑战
xP3x数据集致力于解决多语言指令遵循任务的复杂性挑战,包括模型在低资源语言上的性能瓶颈、跨语言知识迁移的困难,以及文化语境差异导致的语义理解偏差。在构建过程中,面临的主要挑战涉及多语言数据的采集与清洗,需平衡不同语言的数据规模与质量;同时,标注过程需协调专家生成与众包策略,以确保指令的准确性与一致性;此外,处理多样化的书写系统与语言变体,也对数据标准化提出了严峻考验。
常用场景
经典使用场景
在自然语言处理领域,多语言模型的训练与评估长期面临数据稀缺的挑战。xP3x数据集以其覆盖逾百种语言和脚本的庞大规模,成为构建大规模多语言预训练模型的经典资源。研究者常利用其丰富的语言多样性,对模型进行跨语言指令微调,以提升模型在低资源语言上的泛化能力,探索语言间的知识迁移机制。
衍生相关工作
围绕xP3x数据集,学术界衍生出一系列重要研究。例如,基于其进行的多语言指令调优工作探索了模型对齐与跨语言泛化的边界;同时,它也被用于构建多语言基准测试集,以评估大语言模型在多样化语言任务上的性能,催生了关于模型公平性、偏见消减以及语言生态平衡的深入探讨。
数据集最近研究
最新研究方向
在自然语言处理领域,多语言模型的公平性与泛化能力已成为前沿探索的核心议题。xP3x数据集以其覆盖逾百种语言与脚本的庞大规模,为研究语言多样性下的指令微调与跨语言迁移提供了关键资源。当前研究聚焦于利用该数据集探索低资源语言的性能提升机制,分析语言间知识传递的潜在规律,并评估模型在全球化应用中的文化适应性。这些工作不仅推动了多语言人工智能的技术边界,也为构建包容性数字生态奠定了数据基础。
以上内容由遇见数据集搜集并总结生成


