作业批改AI训练集数据
收藏浙江省数据知识产权登记平台2024-12-09 更新2024-12-10 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/98314
下载链接
链接失效反馈官方服务:
资源简介:
通过数据处理和数据加工流程,作业批改AI训练数据被转化为高质量、高标注准确性的训练集。这些数据可提供给AI模型进行训练,帮助模型深入学习并理解作业答案的评估标准,包括答案的正确性、书写规范、逻辑推理过程以及解答的创造性等关键要素。经过训练的AI模型能够更准确地评估学生的作业答案,无论是数学问题、语言作文、科学实验报告还是其他学科的作业。此外,超参数调优和模型优化能进一步提升模型的鲁棒性。这确保了AI模型在教育评估、个性化学习、自动化测试评分、教学辅助、智能辅导、教育研究分析等多种应用场景中发挥着重要作用。经过训练的AI模型不仅优化了作业批改的效率和准确性,还提高了教育反馈的速度和教学质量,同时为教育决策和教学改进提供了数据支持,极大地丰富了教育管理的智能化水平和教学方法的多样性。步骤1:数据收集与预处理,收集作业批改相关的原始数据,这些数据来源于公司自研题库。记录每份作业的作业ID、题目ID和学生答案。进行数据清洗,确保数据质量。 步骤2:数据集分类与标注,将作业批改数据分类为训练集和测试集,对训练集作业进行详细的标注,包括参考答案、学生答案、批改记录等标签。 步骤3:模型选择与初始化,选择基于Transformer的语言模型作为作业批改的预训练模型,用于理解和评估作业答案。初始化模型参数,并设置合理的超参数,如学习率(learning_rate)、批量大小(batch_size)等,以优化模型的训练过程。 步骤4:模型训练,使用PyTorch深度学习框架加载和初始化模型。将准备好的训练集数据输入模型进行训练,模型将不断调整权重,以提高答案评估的准确性。记录训练时长和训练周期(迭代次数),监控模型在训练过程中的性能提升。 步骤5:模型评估,在训练完成后,使用测试集对模型进行评估。计算模型在不同类型作业上的性能指标,包括准确率、召回率、F1分数等,确保模型的准确性和鲁棒性。 步骤6:将训练和测试后的模型应用到实际的作业批改中,评估实时测试集检测准确率和处理速度。
Through data processing and refinement workflows, the training data for AI-powered homework grading is converted into a high-quality, highly accurately annotated training dataset. This dataset can be provided for training AI models, enabling the models to deeply learn and understand the evaluation criteria for homework answers, including key factors such as answer correctness, writing standards, logical reasoning processes, and the creativity of solutions. The trained AI models can then more accurately assess students' homework answers across various subjects, including mathematical problems, language compositions, scientific experiment reports, and other academic assignments. Additionally, hyperparameter tuning and model optimization can further enhance the model's robustness. This ensures that the AI models play a critical role in a wide range of application scenarios, such as educational assessment, personalized learning, automated test scoring, teaching assistance, intelligent tutoring, and educational research analysis. The trained AI models not only optimize the efficiency and accuracy of homework grading but also improve the speed of educational feedback and teaching quality, while providing data support for educational decision-making and teaching improvement, greatly enriching the intelligent level of educational management and the diversity of teaching methods.
Step 1: Data Collection and Preprocessing
Collect raw data related to homework grading, which originates from the company's self-developed question bank. Record the homework ID, question ID, and student's answer for each assignment. Perform data cleaning to ensure data quality.
Step 2: Dataset Classification and Annotation
Classify the homework grading data into training set and test set, and conduct detailed annotations on the training set, including labels such as reference answers, student answers, and grading records.
Step 3: Model Selection and Initialization
Select a Transformer-based language model as the pre-trained model for homework grading, which is used to understand and evaluate homework answers. Initialize the model parameters and set reasonable hyperparameters such as learning_rate, batch_size, etc., to optimize the model's training process.
Step 4: Model Training
Use the PyTorch deep learning framework to load and initialize the model. Input the prepared training set data into the model for training, and the model will continuously adjust its weights to improve the accuracy of answer evaluation. Record the training duration and training cycles (number of iterations), and monitor the performance improvement of the model during training.
Step 5: Model Evaluation
After training is completed, use the test set to evaluate the model. Calculate the performance metrics of the model on different types of assignments, including accuracy, recall, F1 score, etc., to ensure the model's accuracy and robustness.
Step 6: Apply the trained and tested model to actual homework grading, and evaluate the detection accuracy and processing speed of the real-time test set.
提供机构:
可之(宁波)人工智能科技有限公司
创建时间:
2024-10-31
搜集汇总
数据集介绍
特点
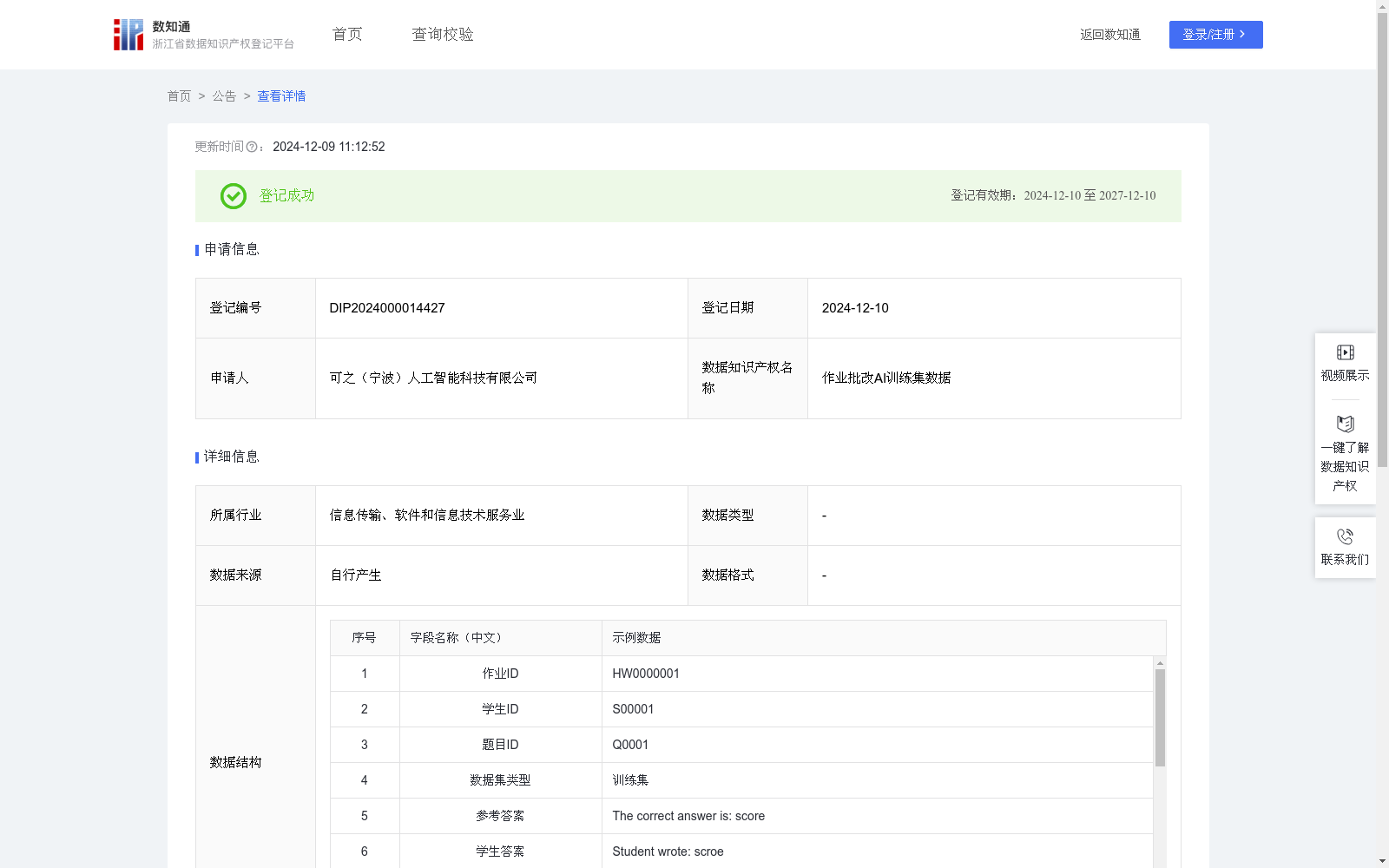
该数据集是用于训练作业批改AI模型的训练集数据,包含1077条记录,每日更新,涵盖作业ID、学生答案、批改记录等关键字段。数据集应用于教育评估、个性化学习等多个场景,通过详细的算法规则说明展示了从数据收集到模型评估的全流程。
以上内容由遇见数据集搜集并总结生成


