CALIBRI
收藏arXiv2025-12-10 更新2025-12-11 收录
下载链接:
https://huggingface.co/datasets/lavis-nlp/CALIBRI
下载链接
链接失效反馈官方服务:
资源简介:
CALIBRI数据集由莱茵美因应用科学大学的研究团队开发,旨在支持代码生成大语言模型(LLM)的校准研究。该数据集包含代码生成样本、对应的正确性标签以及令牌似然值,数据来源为最新生成的代码样本,有效降低了数据泄露风险。数据集通过多校准方法,针对代码复杂度、编程语言等因素进行分组校准,显著提升了模型置信度与真实正确性之间的匹配度。其核心应用领域为代码生成质量评估,通过提供细粒度的校准基准,助力提升开发者在代码审查中的效率与准确性。
The CALIBRI dataset was developed by a research team at RheinMain University of Applied Sciences to support calibration research for code-generating Large Language Models (LLMs). This dataset includes code generation samples, corresponding correctness labels, and token likelihood values. Its data is sourced from freshly generated code samples, which effectively mitigates the risk of data leakage. The dataset employs multi-calibration methodologies to conduct grouped calibration based on factors including code complexity and programming languages, significantly improving the alignment between model confidence and actual correctness. Its core application domain is code generation quality assessment. By providing fine-grained calibration benchmarks, it helps enhance the efficiency and accuracy of developers in code review.
提供机构:
莱茵美因应用科学大学
创建时间:
2025-12-10
原始信息汇总
CALIBRI 数据集概述
数据集简介
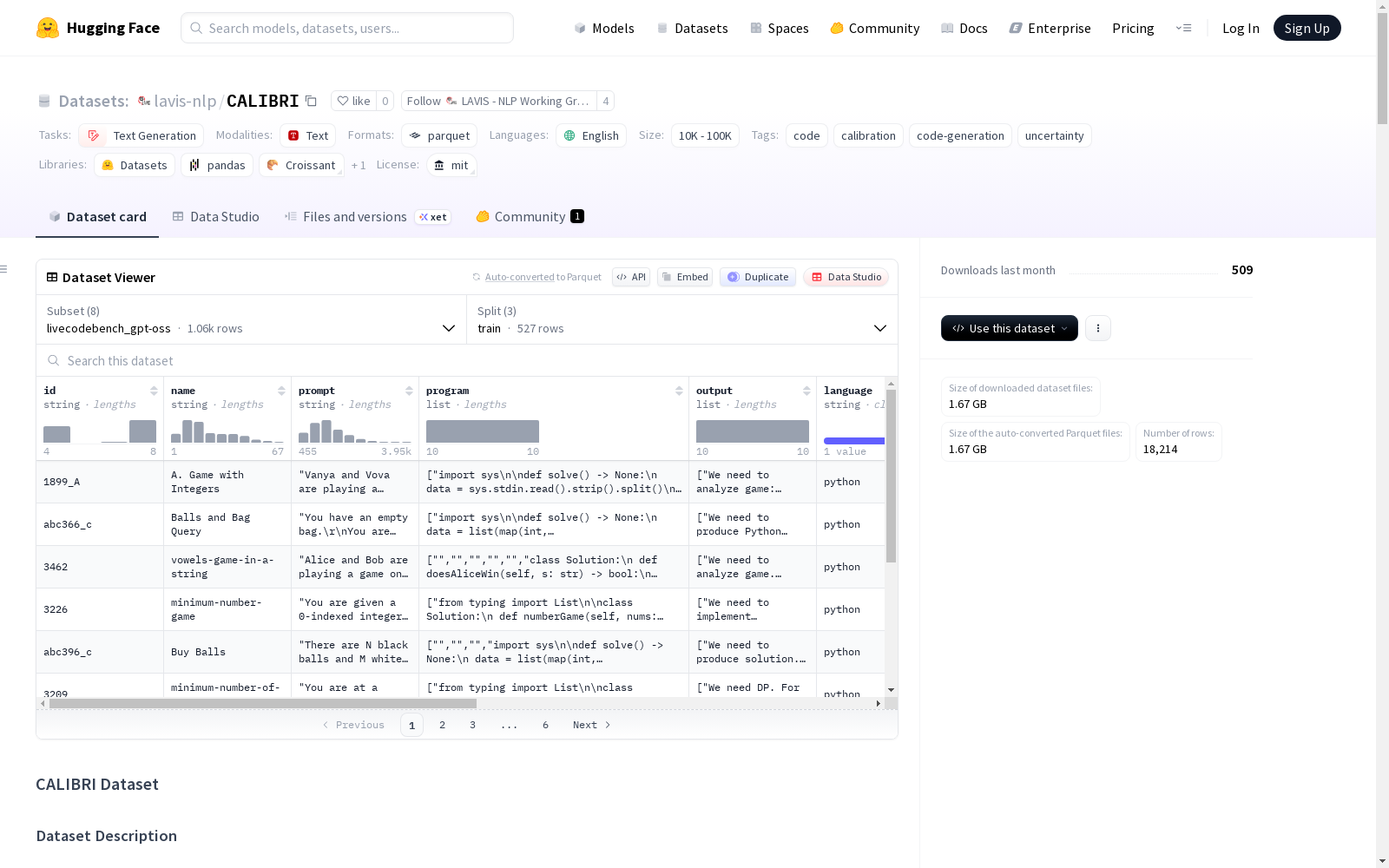
CALIBRI 是一个用于研究基于大语言模型的代码生成校准的综合数据集。它包含来自多个先进语言模型在三个成熟基准测试上的代码生成结果,并附带了用于校准分析的令牌级似然信息以及使用基准测试提供的测试套件生成的正确性标签。每个样本为每个问题提供10种不同的生成结果。
数据集详情
数据集构成
数据集包含8种配置,每种配置对应一个特定的模型与基准测试组合。所有配置均包含训练集、验证集和测试集。
配置列表
- livecodebench_gpt-oss
- 模型: GPT-OSS-20B
- 基准测试: LiveCodeBench
- livecodebench_qwen3
- 模型: Qwen3-Coder-30B-A3B-Instruct
- 基准测试: LiveCodeBench
- mceval_gpt-oss
- 模型: GPT-OSS-20B
- 基准测试: McEval
- mceval_qwen3
- 模型: Qwen3-Coder-30B-A3B-Instruct
- 基准测试: McEval
- mceval_r1-distill
- 模型: DeepSeek-R1-Distill-Qwen-32B
- 基准测试: McEval
- multipl-e_gpt-oss
- 模型: GPT-OSS-20B
- 基准测试: MultiPL-E
- multipl-e_qwen3
- 模型: Qwen3-Coder-30B-A3B-Instruct
- 基准测试: MultiPL-E
- multipl-e_r1-distill
- 模型: DeepSeek-R1-Distill-Qwen-32B
- 基准测试: MultiPL-E
数据字段说明
通用字段(所有基准测试)
id(string): 问题的唯一标识符。prompt(string): 问题描述或函数签名。language(string): 编程语言(例如 "python"、"java")。program(list[string]): 生成的代码解决方案(每个问题10个样本)。is_correct(list[bool]): 每个解决方案是否通过测试套件。token_logprobs(list[list[list[string]]]): 每个生成的令牌级对数概率,以概率/令牌对的形式存储。model(string): 生成代码的模型名称。
LiveCodeBench 特定字段
name(string): 人类可读的问题名称。code_token_idx(list[list[int]]): 起始和结束代码令牌的索引。output(list[string]): 完整的生成内容(包括推理过程)。difficulty(string): 问题难度等级。
McEval 特定字段
output(list[string]): 完整的生成内容(包括推理过程)。difficulty(string): 问题难度等级。
数据规模统计
| 配置名称 | 训练集样本数 | 验证集样本数 | 测试集样本数 | 训练集字节数 | 验证集字节数 | 测试集字节数 | 总大小(字节) |
|---|---|---|---|---|---|---|---|
| livecodebench_gpt-oss | 527 | 264 | 264 | 260,675,054 | 140,233,980 | 132,904,389 | 533,813,423 |
| livecodebench_qwen3 | 527 | 264 | 264 | 207,332,257 | 111,191,870 | 106,361,543 | 424,885,670 |
| mceval_gpt-oss | 853 | 427 | 427 | 303,551,837 | 151,085,271 | 153,387,105 | 608,024,213 |
| mceval_qwen3 | 853 | 427 | 427 | 175,036,630 | 879,055,71 | 90,385,087 | 353,327,288 |
| mceval_r1-distill | 853 | 427 | 427 | 352,895,447 | 178,075,927 | 177,882,943 | 708,854,317 |
| multipl-e_gpt-oss | 1814 | 920 | 927 | 192,412,187 | 93,260,407 | 108,359,223 | 394,031,817 |
| multipl-e_qwen3 | 1814 | 920 | 927 | 87,843,809 | 38,680,366 | 49,219,493 | 175,743,668 |
| multipl-e_r1-distill | 1814 | 920 | 927 | 190,392,589 | 92,138,706 | 103,350,099 | 385,881,394 |
注:上表“样本数”指问题数量。每个问题包含10个生成程序,因此总生成程序数为问题数的10倍。
数据集用途
- 代码生成评估
- 模型校准分析
- 不确定性量化
支持的研究方向
- 代码生成模型的多重校准技术
- 程序合成中的不确定性估计
- 跨不同架构和基准测试的模型校准
- 生成代码的置信度评分
语言
数据集包含多达40种编程语言的代码,具体取决于基准测试配置。
许可信息
本数据集基于 MIT 许可证发布。
引用信息
bibtex @misc{CALIBRI, author = {Viola Campos}, title = {CALIBRI - Replication dataset for the paper Multicalibration for LLM-based Code Generation}, year = {2025}, publisher = {Hugging Face}, howpublished = {url{https://huggingface.co/datasets/lavis-nlp/CALIBRI}} }
搜集汇总
数据集介绍
构建方式
在代码生成领域,确保大语言模型置信度与代码正确性真实概率的一致性,是提升开发效率与代码质量的关键。CALIBRI数据集的构建基于严谨的实验设计,研究者选取了三个具有代表性的代码生成基准测试——MultiPL-E、McEval与LiveCodeBench,涵盖了从简单到复杂、从单语言到多语言的多样化编程任务。通过使用Qwen3 Coder、GPT-OSS和DeepSeek-R1-Distill等前沿开源推理模型,对每个样本提示生成十个代码序列,并记录其对应的词元似然度。随后,利用基准测试中提供的单元测试套件对生成的代码进行功能验证,从而为每个提示-生成对标注了二进制正确性标签。最终,数据集整合了超过17万个包含提示、生成代码、词元似然度及正确性标签的元组,为后续的校准研究提供了坚实的数据基础。
使用方法
该数据集主要用于推动代码生成中不确定性估计与模型校准的研究。研究者可利用CALIBRI中提供的词元似然度与正确性标签,评估不同的初始置信度度量方法(如对整个输出序列、仅代码部分或尾部词元的平均似然度)与真实正确性的对齐程度。在此基础上,可以系统比较多种后处理校准技术,包括经典的Platt缩放和直方图分箱,以及更先进的多重校准方法,如组条件无偏回归和迭代分组线性分箱。通过将样本按代码复杂度、编程语言或生成长度等特征分组,能够深入分析不同语义信息对校准效果的贡献。最终,该数据集支持开发能够更准确反映代码正确性概率的置信度评分模型,以辅助开发者更高效地审查LLM生成的代码。
背景与挑战
背景概述
随着基于人工智能的代码生成技术日益普及,确保代码大语言模型(Code LLMs)的置信度评分能够真实反映代码正确性的概率,已成为软件工程领域的关键研究议题。在此背景下,由莱茵美因应用科学大学的Viola Campos、Robin Kuschnereit和Adrian Ulges等研究人员于2025年创建的CALIBRI数据集应运而生。该数据集旨在推动代码大语言模型校准技术的研究,其核心研究问题聚焦于如何通过多校准(Multicalibration)方法,将代码复杂度、长度及编程语言等多维度信息纳入置信度估计过程,从而提升模型预测的可靠性。CALIBRI的发布为评估和改善最新开源推理模型在代码生成任务中的不确定性量化提供了重要基准,对促进软件开发中人工智能辅助工具的可靠集成具有显著影响力。
当前挑战
CALIBRI数据集致力于解决代码生成领域中模型置信度校准的挑战,即如何使模型输出的置信度分数与其生成代码的实际正确概率精确对齐。这一问题的复杂性在于,代码生成任务的表现受到问题复杂度、代码长度和编程语言等多种因素的显著影响,传统的整体校准方法难以捕捉这些异质性。在数据集构建过程中,研究人员面临多重挑战:首先,需要从MultiPL-E、McEval和LiveCodeBench等多个基准中整合高质量、低数据泄露风险的代码生成样本及其正确性标签;其次,为支持多校准研究,必须为每个样本系统性地标注代码复杂度、长度等语义层面的分组信息;最后,还需处理不同开源推理模型在生成格式上的不一致性,以确保代码提取与置信度计算的可靠性。
常用场景
经典使用场景
在基于大语言模型的代码生成研究领域,CALIBRI数据集为模型置信度校准提供了关键评估基准。该数据集整合了Qwen3 Coder、GPT-OSS等前沿代码大模型在MultiPL-E、LiveCodeBench等基准测试中生成的代码样本,并标注了代码正确性标签与词元似然度。研究者通过分析模型输出的置信度分数与实际正确率之间的偏差,系统评估了多校准方法在提升代码生成可靠性方面的效能。该数据集支持对代码复杂度、编程语言、代码长度等多维度分组进行精细化校准分析,为代码生成模型的置信度可靠性研究建立了标准化实验框架。
解决学术问题
CALIBRI数据集有效解决了代码生成领域置信度校准的核心学术问题。传统代码大模型常存在置信度分数与真实正确率不匹配的校准偏差问题,导致开发者难以准确评估生成代码的可靠性。该数据集通过引入多校准技术,将代码复杂度、编程语言等语义特征纳入校准过程,显著提升了置信度分数的预测准确性。实验表明,采用多校准方法后,模型区分正确与错误代码的准确率提升幅度可达58.3%,这为代码生成模型的可靠性评估提供了量化依据,推动了软件工程领域对AI生成代码质量可控性的深入研究。
实际应用
在软件开发实践中,CALIBRI数据集支撑的校准技术可直接集成到代码生成工具链中。开发者在利用大语言模型生成代码时,系统可实时提供经过校准的置信度分数,准确提示代码片段的潜在错误风险。这种机制显著降低了代码审查的认知负荷,使开发者能够优先检查低置信度的生成代码,提升代码审查效率与软件质量。此外,该技术可应用于持续集成管道,对AI生成的测试代码或补丁进行可靠性筛选,避免将有缺陷的代码合并至主分支,为智能化软件开发提供了可信度保障。
数据集最近研究
最新研究方向
在人工智能驱动的代码生成领域,CALIBRI数据集的推出标志着对大型语言模型(LLM)置信度校准研究的重要进展。该数据集聚焦于代码生成任务中的多校准(multicalibration)方法,旨在通过整合代码复杂度、长度及编程语言等多维度信息,提升模型置信度评分与代码正确性之间的关联性。前沿研究探索了迭代分组线性分箱(IGLB)等先进校准策略,在MultiPL-E、LiveCodeBench等基准测试中显著改善了校准性能,准确率提升最高达58.3%。这一研究方向呼应了软件工程中对可靠AI辅助编程工具的迫切需求,为降低代码审查负担、增强开发者信任提供了关键技术支持,并推动了不确定性估计与模型校准在代码生成领域的理论深化与应用拓展。
相关研究论文
- 1Multicalibration for LLM-based Code Generation莱茵美因应用科学大学 · 2025年
以上内容由遇见数据集搜集并总结生成


