Faces in Things
收藏资源简介:
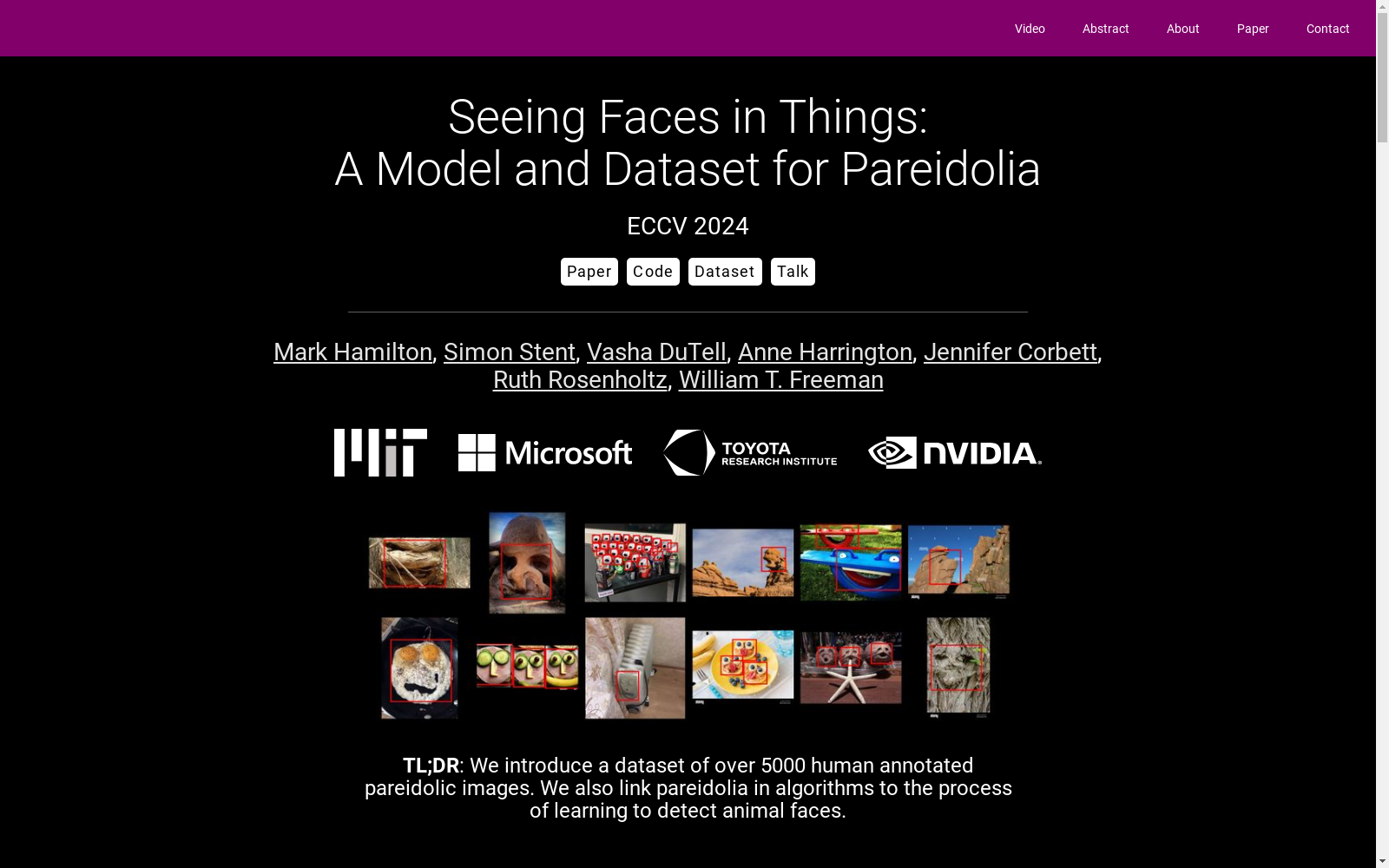
Faces in Things数据集由麻省理工学院和微软等机构创建,包含5000张标注了人脸幻觉(pareidolia)的网络图片。该数据集用于研究计算机视觉中的人脸检测系统是否表现出类似人类的幻觉现象。数据集内容包括图片的边界框和基本面部属性,如情感、性别和意图。创建过程涉及从LAION-5B数据集中采样候选图片,并通过人工标注去除包含实际人类或动物面部的图片。该数据集主要应用于计算机视觉领域,旨在解决人脸检测系统中的幻觉现象,并探索如何改进这些系统的性能。
The Faces in Things dataset was created by institutions such as the Massachusetts Institute of Technology (MIT) and Microsoft. It contains 5000 web images annotated for pareidolia (face illusions). This dataset is designed to investigate whether face detection systems in computer vision exhibit pareidolia similar to that observed in humans. The dataset includes bounding boxes of the images and basic facial attributes including emotion, gender, and intent. Its creation involved sampling candidate images from the LAION-5B dataset, followed by manual annotation to remove images containing actual human or animal faces. Primarily applied in the field of computer vision, this dataset aims to address pareidolia in face detection systems and explore ways to improve the performance of such systems.
FacesInThings 数据集概述
数据集简介
- 名称: FacesInThings
- 描述: 一个包含超过5000张人类标注的幻觉人脸图像的数据集,用于研究幻觉人脸现象(pareidolia)。
- 来源: 数据集基于LAION-5B数据集,并进行了关键人脸属性和边界框的标注。
数据集内容
- 图像数量: 5000+
- 标注信息: 包含人脸属性和边界框的标注。
研究目标
- 主要研究方向: 从计算机视觉角度研究幻觉人脸现象。
- 研究内容:
- 评估现有最先进的人脸检测器在幻觉人脸检测中的表现。
- 探索通过在动物人脸数据上微调人脸检测器来改进幻觉人脸检测的方法。
- 提出一个简单的统计模型来预测图像中幻觉人脸的出现。
相关资源
- 论文: Seeing Faces in Things: A Model and Dataset for Pareidolia
- 代码: GitHub 代码库
- 数据集下载: FacesInThings 数据集
- 视频讲解: YouTube 视频
作者信息
- 主要作者:
- Mark Hamilton
- Simon Stent
- Vasha DuTell
- Anne Harrington
- Jennifer Corbett
- Ruth Rosenholtz
- William T. Freeman
联系信息
- 联系人: Mark Hamilton
- 邮箱: markth@mit.edu
- 1Seeing Faces in Things: A Model and Dataset for Pareidolia麻省理工学院, 微软, 丰田研究院, NVIDIA · 2024年


