DiffSeg30k
收藏arXiv2025-11-24 更新2025-11-26 收录
下载链接:
https://huggingface.co/datasets/Chaos2629/Diffseg30k
下载链接
链接失效反馈官方服务:
资源简介:
DiffSeg30k是由新加坡国立大学与华南理工大学联合构建的扩散编辑检测基准数据集,包含3万张具备像素级标注的扩散编辑图像。该数据集融合真实场景图像与AI生成内容,涵盖八种前沿扩散模型的多轮序列编辑,每幅图像最多经历三次局部修改。通过视觉语言模型驱动的自动化流程,系统实现语义区域识别与上下文感知的编辑提示生成,支持添加、删除及属性修改三类操作。该数据集专为细粒度AIGC检测而设计,推动研究从二值分类转向语义分割范式,致力于解决扩散模型局部编辑的精准定位与溯源 attribution 等核心挑战。
DiffSeg30k is a benchmark dataset for diffusion edit detection, jointly constructed by the National University of Singapore and South China University of Technology. It contains 30,000 diffusion-edited images with pixel-level annotations. This dataset blends real-world scene images and AI-generated content, covering multi-round sequential edits from eight state-of-the-art diffusion models, with each image undergoing up to three local modifications. Through an automated pipeline driven by vision-language models, the system enables semantic region recognition and context-aware edit prompt generation, supporting three types of operations: addition, deletion, and attribute modification. Designed specifically for fine-grained AIGC detection, this dataset promotes the shift of research from binary classification to semantic segmentation paradigms, and aims to address core challenges such as accurate localization and attribution of local edits by diffusion models.
提供机构:
新加坡国立大学, 华南理工大学
创建时间:
2025-11-24
原始信息汇总
DiffSeg30k 数据集概述
数据集简介
DiffSeg30k 是一个用于分割基于扩散编辑的多轮编辑数据集,适用于训练和评估能够定位编辑区域并识别底层扩散模型的模型。
数据集内容
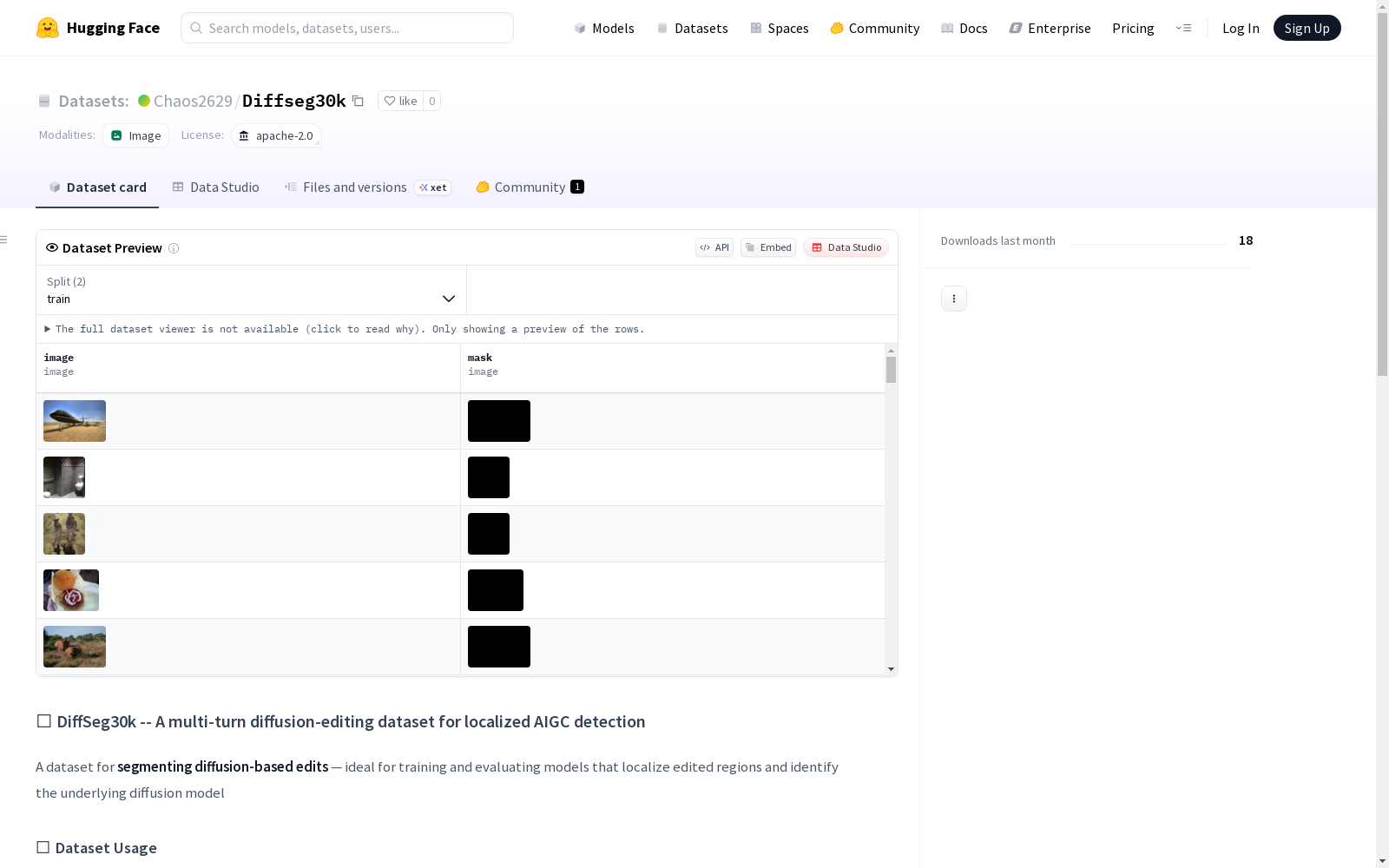
- 编辑图像文件:格式为
xxxxxxxx.image.png,每张图像可能经过1次、2次或3次编辑操作 - 对应掩码文件:格式为
xxxxxxxx.mask.png,像素值编码编辑类型和使用的扩散模型
数据加载方式
python from datasets import load_dataset dataset = load_dataset("Chaos2629/Diffseg30k", split="train") image, mask = dataset[0][image], dataset[0][mask]
掩码标注规范
掩码为灰度图像(PNG格式),像素值与特定编辑模型的对应关系:
| 掩码值 | 编辑模型 |
|---|---|
| 0 | background |
| 1 | stabilityai/stable-diffusion-2-inpainting |
| 2 | kolors |
| 3 | stabilityai/stable-diffusion-3.5-medium |
| 4 | flux |
| 5 | diffusers/stable-diffusion-xl-1.0-inpainting-0.1 |
| 6 | glide |
| 7 | Tencent-Hunyuan/HunyuanDiT-Diffusers |
| 8 | kandinsky-community/kandinsky-2-2-decoder-inpaint |
重要说明
- 每张编辑图像可能经过多轮编辑,对应掩码可能包含多个不同的标签值(范围0-8)
许可证
Apache-2.0
搜集汇总
数据集介绍
构建方式
在人工智能生成内容检测领域,DiffSeg30k数据集通过模拟真实场景中的多轮扩散编辑过程构建而成。该数据集采用基于视觉语言模型的自动化流程,首先从COCO数据集中选取真实图像或通过扩散模型生成基础图像,随后利用Grounded-SAM技术识别语义显著区域并生成对象掩码。编辑阶段结合上下文感知提示,随机选择八种先进扩散模型对选定区域执行属性修改、对象添加或移除等操作,每张图像最多经历三轮独立编辑,最终形成包含像素级标注的3万张样本。
特点
DiffSeg30k的显著特征体现在其多维度平衡设计策略。数据集涵盖真实场景与AI生成的基础图像,确保内容多样性;集成八种前沿扩散模型,覆盖广泛的编辑技术谱系;通过多轮编辑机制模拟网络图像被不同用户反复修改的现实情境。特别值得注意的是,该数据集不仅标注编辑区域边界,还精确记录每处编辑对应的扩散模型,将传统二值分类任务升维为同步实现编辑定位与模型溯源的语义分割任务,为细粒度AIGC检测研究提供全新范式。
使用方法
该数据集支持语义分割任务的双重应用路径:在基础层面可实现编辑区域的二值分割定位,进阶层面则能同步识别编辑区域对应的特定扩散模型。研究人员可采用经典分割架构如FCN、SegFormer或Deeplabv3+进行模型训练,通过像素级精度评估指标(mIoU、边界F1分数)量化性能。数据集特别适用于研究多轮编辑场景下的模型鲁棒性,以及探索分割模型在未见过的扩散生成器上的泛化能力,为构建可部署的AIGC定位系统提供基准支持。
背景与挑战
背景概述
随着生成式人工智能技术的迅猛发展,扩散模型驱动的图像编辑技术能够对局部区域进行高度逼真的修改,这为数字内容真实性验证带来了严峻挑战。DiffSeg30k数据集由新加坡国立大学Show实验室与华南理工大学研究团队于2025年联合创建,旨在解决现有AIGC检测基准局限于整体图像分类而忽视局部编辑定位的缺陷。该数据集包含三万张经过多轮扩散编辑的图像,并配备像素级标注,通过模拟真实场景中多用户、多模型的序列编辑过程,将AIGC检测范式从二元分类推进至语义分割层面,显著提升了检测任务的细粒度与实用性。
当前挑战
在领域问题层面,DiffSeg30k致力于解决扩散模型局部编辑的精准检测与溯源难题,其核心挑战在于如何同时实现编辑区域的像素级定位和对应生成模型的准确识别,这要求模型具备对多轮交错编辑的复杂模式理解能力。在构建过程中,研究团队面临自动化流水线生成低质量编辑样本的困境,包括扩散模型编辑能力局限导致的残缺修改,以及基础分割模型产生的掩码误差。此外,为保持数据多样性而设计的平衡策略——涵盖八种扩散模型、三种编辑类型和多轮编辑序列——也大幅增加了数据采集与质量控制的复杂度。
常用场景
经典使用场景
在数字内容真实性验证领域,DiffSeg30k数据集主要用于评估扩散模型编辑区域的精细定位能力。该数据集通过模拟真实网络环境中图像被多次独立编辑的场景,为研究者提供了研究多轮扩散编辑检测的理想平台。其经典应用体现在训练语义分割模型同时定位编辑区域并识别所使用的扩散模型,推动了AIGC检测从整体图像分类向像素级分析的技术转型。
实际应用
在实际应用层面,DiffSeg30k为数字取证领域提供了关键技术支持。其多轮编辑模拟机制能够有效检测社交媒体平台中经过多次篡改的图像内容,在新闻真实性验证、版权保护等场景发挥重要作用。基于该数据集训练的模型已展现出卓越的跨生成器泛化能力,为构建实用的AIGC检测系统奠定了坚实基础。
衍生相关工作
该数据集的发布催生了一系列基于分割范式的AIGC检测研究。SegFormer和Deeplabv3+等模型在该数据集上的基准测试揭示了语义分割方法在编辑定位任务中的巨大潜力。后续研究围绕提升模型对图像压缩等后处理的鲁棒性展开,同时探索了分割模型作为强分类器的双重用途,推动了细粒度AIGC检测技术路线的创新发展。
以上内容由遇见数据集搜集并总结生成


