pulze/intent-v0.1-dataset
收藏Hugging Face2024-05-03 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/pulze/intent-v0.1-dataset
下载链接
链接失效反馈官方服务:
资源简介:
# pulze-intent-v0.1
Intent-tuned LLM router that selects the best LLM for a user query. Use with [knn-router](https://github.com/pulzeai-oss/knn-router).
## Models
- claude-3-haiku-20240307
- claude-3-opus-20240229
- claude-3-sonnet-20240229
- command-r
- command-r-plus
- dbrx-instruct
- gpt-3.5-turbo-0125
- gpt-4-turbo-2024-04-09
- llama-3-70b-instruct
- mistral-large
- mistral-medium
- mistral-small
- mixtral-8x7b-instruct
## Data
### Prompts and Intent Categories
Prompt and intent categories are derived from the [GAIR-NLP/Auto-J scenario classification dataset](https://github.com/GAIR-NLP/auto-j/blob/2ae17a3965d933232e9cd50302aa0f176249c83b/README.md?plain=1#L582).
Citation:
```
@article{li2023generative,
title={Generative Judge for Evaluating Alignment},
author={Li, Junlong and Sun, Shichao and Yuan, Weizhe and Fan, Run-Ze and Zhao, Hai and Liu, Pengfei},
journal={arXiv preprint arXiv:2310.05470},
year={2023}
}
```
### Response Evaluation
Candidate model responses were evaluated pairwise using `openai/gpt-4-turbo-2024-04-09`, with the following prompt:
```
You are an expert, impartial judge tasked with evaluating the quality of responses generated by two AI assistants.
Think step by step, and evaluate the responses, <response1> and <response2> to the instruction, <instruction>. Follow these guidelines:
- Avoid any position bias and ensure that the order in which the responses were presented does not influence your judgement
- Do not allow the length of the responses to influence your judgement - a concise response can be as effective as a longer one
- Consider factors such as adherence to the given instruction, helpfulness, relevance, accuracy, depth, creativity, and level of detail
- Be as objective as possible
Make your decision on which of the two responses is better for the given instruction from the following choices:
If <response1> is better, use "1".
If <response2> is better, use "2".
If both answers are equally good, use "0".
If both answers are equally bad, use "0".
<instruction>
{INSTRUCTION}
</instruction>
<response1>
{RESPONSE1}
</response1>
<response2>
{RESPONSE2}
</response2>
```
Each pair of models is subject to 2 matches, with the positions of the respective responses swapped in the evaluation prompt. A model is considered a winner only if
it wins both matches.
For each prompt, we then compute Bradley-Terry scores for the respective models using the same [method](https://github.com/lm-sys/FastChat/blob/f2e6ca964af7ad0585cadcf16ab98e57297e2133/fastchat/serve/monitor/elo_analysis.py#L57) as that used in the [LMSYS Chatbot Arena Leaderboard](https://chat.lmsys.org/?leaderboard). Finally, we normalize all scores to a scale from 0 to 1 for interoperability with other weighted ranking systems.
提供机构:
pulze
原始信息汇总
数据集概述
数据集名称
pulze-intent-v0.1
数据集用途
用于选择最适合用户查询的大型语言模型(LLM)路由器。
模型列表
- claude-3-haiku-20240307
- claude-3-opus-20240229
- claude-3-sonnet-20240229
- command-r
- command-r-plus
- dbrx-instruct
- gpt-3.5-turbo-0125
- gpt-4-turbo-2024-04-09
- llama-3-70b-instruct
- mistral-large
- mistral-medium
- mistral-small
- mixtral-8x7b-instruct
数据来源
- 提示和意图分类:来源于GAIR-NLP/Auto-J 场景分类数据集。
响应评估方法
- 评估模型:使用
openai/gpt-4-turbo-2024-04-09进行候选模型响应的成对评估。 - 评估流程:每对模型进行两次匹配,交换评估提示中的响应位置。模型只有在两次匹配中均获胜才被视为胜利者。
- 评分计算:使用与LMSYS Chatbot Arena Leaderboard相同的方法计算Bradley-Terry分数,并将所有分数归一化至0到1的范围内。
搜集汇总
数据集介绍
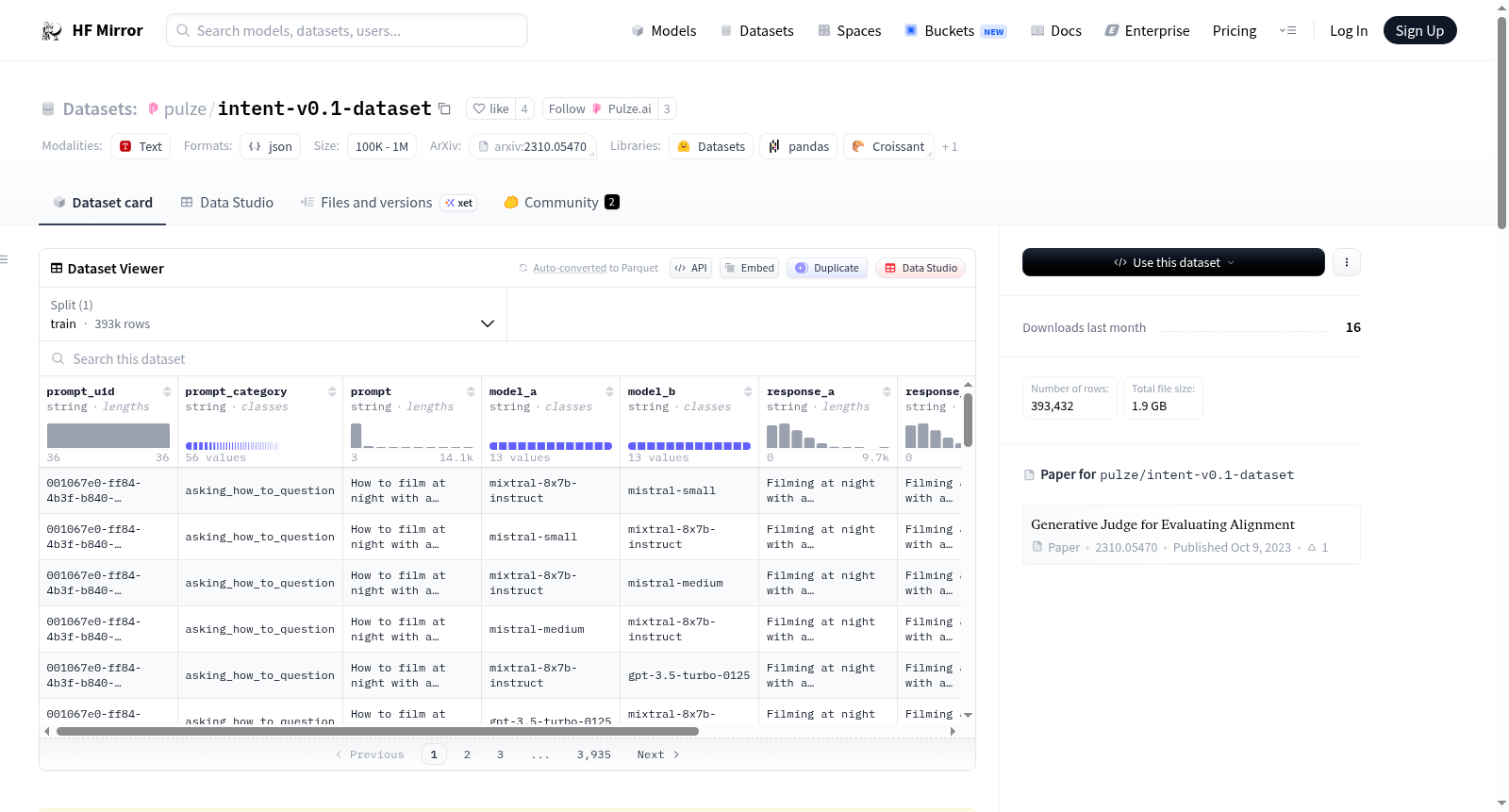
构建方式
在大型语言模型路由优化领域,pulze/intent-v0.1-dataset的构建体现了严谨的工程化流程。其提示词与意图类别源自GAIR-NLP/Auto-J场景分类数据集,确保了任务场景的多样性与学术基础。核心构建环节采用成对比较评估机制,通过GPT-4-Turbo作为公正评判员,对涵盖Claude系列、GPT系列、Llama等十三种主流模型的生成响应进行两轮交叉盲评。最终依据Bradley-Terry模型计算标准化得分,形成具有统计显著性的模型性能排序,为意图感知的路由决策提供了量化依据。
特点
该数据集的核心特征在于其多层次的结构化设计。它不仅整合了经过学术验证的多样化意图分类体系,更构建了覆盖前沿闭源与开源模型的横向对比矩阵。数据集的评估维度深度融合了指令遵循度、信息准确性、创造性等多元质量指标,并通过位置轮换与双重验证机制有效消除了评估偏差。其输出的归一化分数具备良好的系统互操作性,使得不同权重排名体系能够基于统一标尺进行模型效能解析,为动态路由策略提供了细粒度参考框架。
使用方法
该数据集主要服务于大型语言模型路由系统的开发与优化。研究人员可将其与knn-router等路由框架结合,通过意图分类与模型性能映射关系,构建查询感知的模型选择器。实际部署时,系统通过解析用户查询的意图特征,检索数据集中对应场景下各模型的标准化性能分数,进而动态调度最优模型生成响应。该使用方法能够显著提升复杂任务场景下的响应质量与资源分配效率,为构建自适应、高性能的模型服务层提供关键数据支撑。
背景与挑战
背景概述
在大型语言模型(LLM)技术迅猛发展的背景下,模型性能的评估与选择成为自然语言处理领域的关键议题。pulze/intent-v0.1-dataset由Pulze AI团队于2024年构建,其核心研究问题聚焦于开发一种基于意图感知的LLM路由机制,旨在根据用户查询的语义意图,从多样化的预训练模型中智能选取最优响应者。该数据集通过整合GAIR-NLP/Auto-J场景分类数据,并引入多模型响应与GPT-4驱动的成对评估框架,为LLM性能的细粒度比较提供了标准化基准,对推动高效模型部署与资源优化具有显著影响力。
当前挑战
该数据集致力于解决LLM路由选择中的核心挑战:如何在多样化的用户意图场景下,实现跨模型性能的精准评估与动态匹配。具体挑战包括:第一,在领域问题层面,需克服不同模型在响应质量、风格与适用性上的异构性,建立公平且无偏见的评估指标;第二,在构建过程中,依赖自动化评估框架可能引入模型偏好偏差,且成对比较机制的计算复杂度较高,同时数据来源的多样性与标注一致性也难以保证。
常用场景
经典使用场景
在大型语言模型(LLM)路由与优化领域,pulze/intent-v0.1-dataset为研究者提供了一个标准化的评估基准。该数据集通过精心设计的提示词与意图分类,结合多模型响应配对比较,旨在系统性地衡量不同LLM在多样化任务中的表现差异。其经典使用场景集中于构建智能路由系统,即根据用户查询的语义意图,自动选择最适配的预训练模型,以提升响应质量与效率。
衍生相关工作
围绕该数据集衍生的经典工作主要包括意图驱动的模型路由算法与评估体系拓展。例如,基于k近邻(knn-router)的实时路由系统实现了低延迟的模型匹配;同时,其采用的配对比较与评分方法被后续研究广泛借鉴,用于构建更细粒度的多维度评估基准。这些工作共同推动了LLM生态中自适应路由与性能监控技术的演进,促进了开源工具链的完善。
数据集最近研究
最新研究方向
在大型语言模型(LLM)路由与优化领域,pulze/intent-v0.1-dataset的推出标志着意图驱动模型选择机制的前沿探索。该数据集基于GAIR-NLP/Auto-J场景分类数据构建,通过集成Claude-3、GPT系列、Llama等十余种主流模型,并采用GPT-4-Turbo进行成对响应评估与Bradley-Terry评分归一化,为多模型协同系统的性能优化提供了基准。当前研究聚焦于利用意图分类与k近邻路由技术,实现查询与最优模型的动态匹配,旨在提升响应质量、降低计算成本,推动高效、可扩展的LLM服务架构发展,对人工智能服务部署与资源分配策略具有重要参考意义。
以上内容由遇见数据集搜集并总结生成


