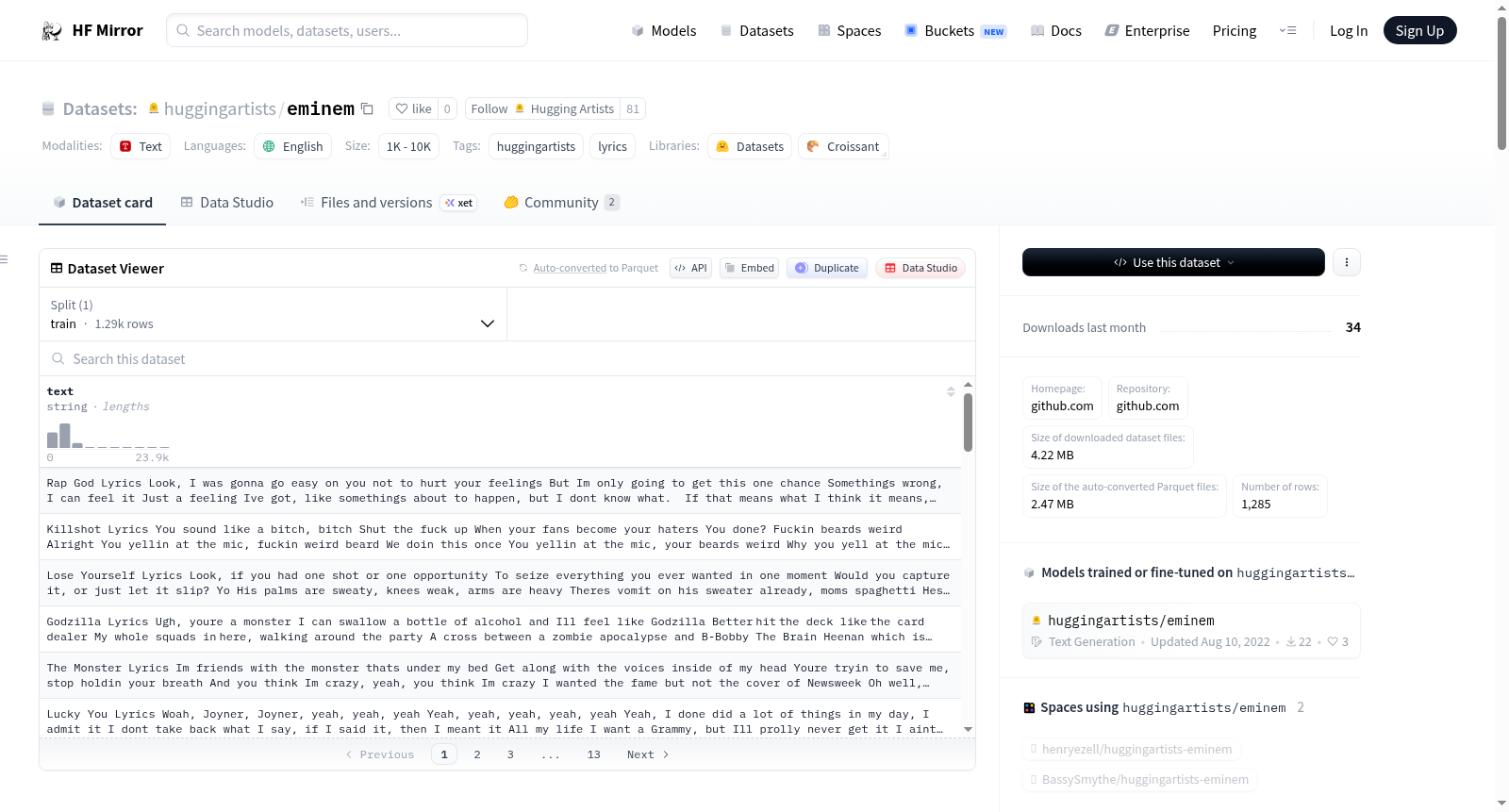
huggingartists/eminem
收藏Hugging Face2022-10-25 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/huggingartists/eminem
下载链接
链接失效反馈官方服务:
资源简介:
---
language:
- en
tags:
- huggingartists
- lyrics
---
# Dataset Card for "huggingartists/eminem"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [How to use](#how-to-use)
- [Dataset Structure](#dataset-structure)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [About](#about)
## Dataset Description
- **Homepage:** [https://github.com/AlekseyKorshuk/huggingartists](https://github.com/AlekseyKorshuk/huggingartists)
- **Repository:** [https://github.com/AlekseyKorshuk/huggingartists](https://github.com/AlekseyKorshuk/huggingartists)
- **Paper:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of the generated dataset:** 8.291956 MB
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div style="display:DISPLAY_1; margin-left: auto; margin-right: auto; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://images.genius.com/c7367126e7e6ebc13fcea9d4efca0204.1000x1000x1.jpg')">
</div>
</div>
<a href="https://huggingface.co/huggingartists/eminem">
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 HuggingArtists Model 🤖</div>
</a>
<div style="text-align: center; font-size: 16px; font-weight: 800">Eminem</div>
<a href="https://genius.com/artists/eminem">
<div style="text-align: center; font-size: 14px;">@eminem</div>
</a>
</div>
### Dataset Summary
The Lyrics dataset parsed from Genius. This dataset is designed to generate lyrics with HuggingArtists.
Model is available [here](https://huggingface.co/huggingartists/eminem).
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
en
## How to use
How to load this dataset directly with the datasets library:
```python
from datasets import load_dataset
dataset = load_dataset("huggingartists/eminem")
```
## Dataset Structure
An example of 'train' looks as follows.
```
This example was too long and was cropped:
{
"text": "Look, I was gonna go easy on you\nNot to hurt your feelings\nBut I'm only going to get this one chance\nSomething's wrong, I can feel it..."
}
```
### Data Fields
The data fields are the same among all splits.
- `text`: a `string` feature.
### Data Splits
| train |validation|test|
|------:|---------:|---:|
|1285| -| -|
'Train' can be easily divided into 'train' & 'validation' & 'test' with few lines of code:
```python
from datasets import load_dataset, Dataset, DatasetDict
import numpy as np
datasets = load_dataset("huggingartists/eminem")
train_percentage = 0.9
validation_percentage = 0.07
test_percentage = 0.03
train, validation, test = np.split(datasets['train']['text'], [int(len(datasets['train']['text'])*train_percentage), int(len(datasets['train']['text'])*(train_percentage + validation_percentage))])
datasets = DatasetDict(
{
'train': Dataset.from_dict({'text': list(train)}),
'validation': Dataset.from_dict({'text': list(validation)}),
'test': Dataset.from_dict({'text': list(test)})
}
)
```
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Citation Information
```
@InProceedings{huggingartists,
author={Aleksey Korshuk}
year=2022
}
```
## About
*Built by Aleksey Korshuk*
[](https://github.com/AlekseyKorshuk)
[](https://twitter.com/intent/follow?screen_name=alekseykorshuk)
[](https://t.me/joinchat/_CQ04KjcJ-4yZTky)
For more details, visit the project repository.
[](https://github.com/AlekseyKorshuk/huggingartists)
提供机构:
huggingartists
原始信息汇总
数据集概述
数据集描述
- 数据集名称: huggingartists/eminem
- 数据集大小: 8.291956 MB
- 语言: en
- 数据集摘要: 该数据集从Genius解析的歌词数据,旨在用于HuggingArtists生成歌词。
- 支持的任务和排行榜: 更多信息待补充
数据集结构
- 数据字段:
text: 字符串类型,包含歌词文本。
- 数据分割:
train: 1285条记录validation和test: 未直接提供,但可通过代码分割train数据获得。
使用方法
- 加载数据集: python from datasets import load_dataset dataset = load_dataset("huggingartists/eminem")
数据集创建
附加信息
搜集汇总
数据集介绍
构建方式
在音乐信息检索与自然语言处理交叉领域,歌词数据集为分析艺术家的语言风格提供了宝贵资源。该数据集通过自动化脚本从Genius平台系统性地爬取并解析了美国说唱歌手Eminem的歌词文本,构建过程聚焦于原始文本的采集与格式化,确保数据直接反映艺术家的创作内容。所有歌词均以纯文本形式存储,未经过多层级标注,保留了歌词的原始序列结构,便于后续的生成式建模任务。
特点
本数据集的核心特征在于其高度的领域专一性,集中收录了Eminem职业生涯中的1285条歌词文本,为研究其独特的韵律、词汇使用及主题演变提供了密集的语料。数据以单一的`text`字段呈现,结构简洁统一,所有样本均归属于训练集,赋予了研究者根据具体实验需求灵活划分训练、验证及测试子集的自由度。作为英文文本集合,它天然适用于生成歌词、风格模仿及文本分析等计算语言学任务。
使用方法
利用该数据集进行学术研究或模型开发,操作流程极为便捷。研究者可通过Hugging Face的`datasets`库,使用`load_dataset("huggingartists/eminem")`指令直接加载。鉴于数据最初仅提供单一训练分割,用户可依据提供的示例代码,采用numpy进行随机或按比例划分,从而构建出包含训练集、验证集和测试集的完整DatasetDict对象,为模型训练与评估奠定基础。
背景与挑战
背景概述
在自然语言生成领域,艺术家歌词数据集为研究个性化文本生成提供了重要资源。huggingartists/eminem数据集由Aleksey Korshuk于2022年构建,专注于说唱歌手Eminem的歌词文本。该数据集源自Genius平台的歌词解析,旨在支持基于Transformer架构的歌词生成模型训练,为音乐信息检索和创造性语言生成研究提供了特定艺术家的语料库。其核心研究问题在于探索如何利用有限但风格鲜明的文本数据,模拟特定艺术家的语言风格与创作模式,对计算创造力与个性化文本生成领域具有示范意义。
当前挑战
该数据集旨在解决个性化歌词生成的挑战,即如何准确捕捉艺术家独特的语言风格、韵律结构和情感表达。构建过程中面临多重挑战:源数据来自非结构化的歌词文本,需进行清洗与规范化以消除标注噪声;Eminem歌词中包含大量俚语、文化隐喻和复杂叙事结构,对语言模型的语义理解能力提出更高要求;数据规模相对有限,可能影响生成文本的多样性与泛化能力。此外,数据集的构建缺乏详细的标注流程与偏差分析文档,在可复现性与伦理考量方面存在完善空间。
常用场景
经典使用场景
在自然语言生成领域,特定艺术家的歌词数据集为风格化文本生成提供了宝贵资源。huggingartists/eminem数据集收录了著名说唱歌手Eminem的歌词文本,其经典使用场景在于训练基于Transformer架构的语言模型,以模仿Eminem独特的韵律、词汇和叙事风格,生成具有相似艺术特质的歌词内容。这类应用不仅展示了生成模型在捕捉个人语言风格方面的潜力,也为音乐创作和文学研究提供了自动化工具。
实际应用
在实际应用中,基于该数据集训练的模型可服务于音乐创作辅助、个性化内容生成和娱乐产业。例如,音乐制作人可利用模型生成灵感片段或补充歌词;教育领域可将其用于分析现代诗歌和说唱文化的语言结构;娱乐平台则可集成此类模型为用户提供互动式的歌词创作体验。这些应用不仅拓展了人工智能在创意领域的边界,也促进了艺术表达形式的数字化创新。
衍生相关工作
围绕huggingartists系列数据集,已衍生出多项经典研究工作。例如,基于类似艺术家歌词数据训练的模型被用于研究语言风格的可控生成、跨领域文本迁移以及音乐信息检索。相关项目如HuggingArtists开源框架,进一步标准化了从歌词抓取到模型训练的全流程,推动了社区在艺术家人工智能领域的协作与创新,为后续的个性化生成模型研究提供了可复现的范例。
以上内容由遇见数据集搜集并总结生成


