vcrop-smoke-dataset
收藏Hugging Face2026-05-18 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/ArielPorath/vcrop-smoke-dataset
下载链接
链接失效反馈官方服务:
资源简介:
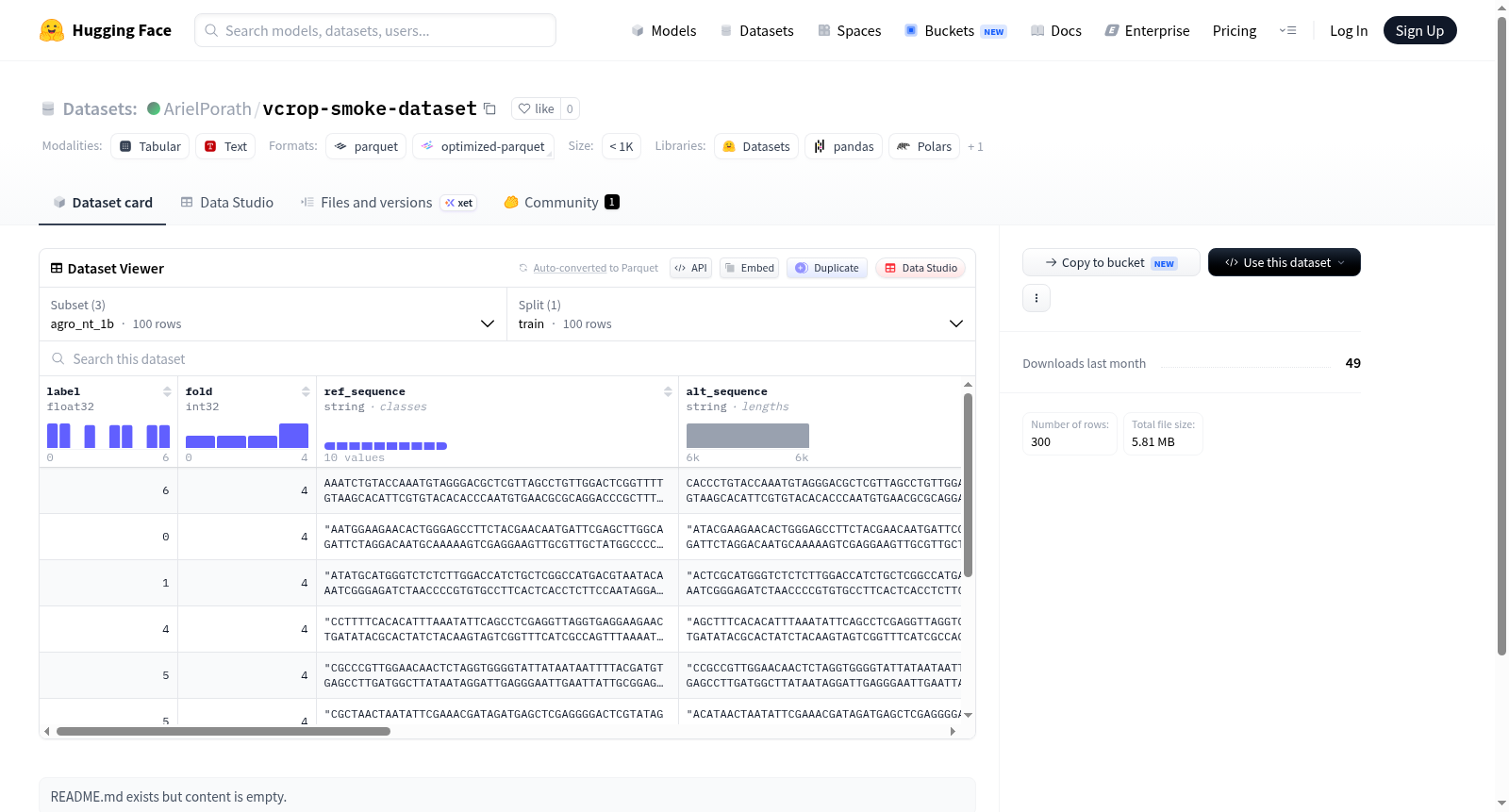
该数据集包含三个配置(raw、agro_nt_1b、ntv3_650m),主要用于序列变异相关的分析或预测任务。核心数据由成对的参考序列(ref_sequence)和替代序列(alt_sequence)组成,每个样本包含一个浮点型标签(label)和一个整型折叠标识(fold)。raw配置仅提供原始序列对和标签;agro_nt_1b和ntv3_650m配置在原始序列基础上,额外提供了从特定模型(如1b、650m规模)计算得到的嵌入向量特征,包括参考序列和替代序列的均值嵌入(ref_embedding_mean, alt_embedding_mean)以及SNP位置嵌入(ref_embedding_snp, alt_embedding_snp)。ntv3_650m配置还包含余弦相似度特征(cosine_mean, cosine_snp)。所有配置的训练集均包含100个样本。数据集适用于需要序列对输入并可能利用预训练嵌入进行回归或分类的机器学习任务,例如预测序列变异的生物学效应。
This dataset includes three configurations (raw, agro_nt_1b, ntv3_650m), primarily designed for sequence variation analysis or prediction tasks. The core data consists of paired reference sequences (ref_sequence) and alternative sequences (alt_sequence), with each sample containing a floating-point label and an integer fold identifier. The raw configuration provides only the raw sequence pairs and labels; the agro_nt_1b and ntv3_650m configurations additionally offer embedding vector features computed from specific models (e.g., 1b, 650m scale), including mean embeddings for reference and alternative sequences (ref_embedding_mean, alt_embedding_mean) and SNP position embeddings (ref_embedding_snp, alt_embedding_snp). The ntv3_650m configuration also includes cosine similarity features (cosine_mean, cosine_snp). All configurations have a training set containing 100 samples. The dataset is suitable for machine learning tasks that require sequence pair inputs and may leverage pre-trained embeddings for regression or classification, such as predicting the biological effects of sequence variations.
创建时间:
2026-05-17
搜集汇总
数据集介绍
构建方式
在农业基因组学与机器学习交叉领域,vcrop-smoke-dataset数据集应运而生,旨在为基因组序列功能预测模型提供训练与评估的基础。该数据集通过精心设计的三种配置(agro_nt_1b、ntv3_650m和raw)来构建,每种配置均包含100条训练样本。其中,raw配置仅保留原始的参考序列(ref_sequence)、替代序列(alt_sequence)、标签(label)及折叠信息(fold),而agro_nt_1b和ntv3_650m配置则在此基础上,融入了由预训练模型提取的嵌入向量,如ref_embedding_mean、ref_embedding_snp以及对应的alt变体,以捕捉序列的深层语义特征。此外,ntv3_650m配置还额外计算了余弦相似度度量(cosine_mean和cosine_snp),进一步丰富了特征空间。这种差异化构建策略,使得数据集能够灵活适应从基础序列比对到高级特征融合的多种研究需求。
特点
vcrop-smoke-dataset数据集的核心特点在于其多层次的特征表示与配置多样性。首先,raw配置提供了最纯粹的序列对信息,适合用于开发或基准测试基础的变异效应预测模型。其次,agro_nt_1b和ntv3_650m配置通过嵌入向量(如均值嵌入和SNP位点嵌入),将原始序列映射到高维连续空间,从而能够捕捉到序列间微妙的功能差异。特别地,ntv3_650m配置中引入的余弦相似度指标,为衡量参考与替代序列在嵌入空间中的关系提供了直观的量化依据。此外,所有配置均包含折叠(fold)字段,支持交叉验证以增强模型评估的稳健性。这些特征共同构建了一个兼具灵活性与深度分析能力的数据资源。
使用方法
使用vcrop-smoke-dataset数据集时,研究者可根据特定任务选择相应的配置。对于仅需序列与标签的简单分类任务,可直接加载raw配置,并通过fold字段划分训练与验证集。若需利用预训练嵌入来提升模型性能,应选用agro_nt_1b或ntv3_650m配置,将嵌入向量作为模型的输入特征。例如,在PyTorch中,可通过HuggingFace Datasets库的load_dataset函数指定config_name参数(如'agro_nt_1b'),并按需处理列表类型的嵌入数据。对于ntv3_650m配置,余弦相似度指标可直接作为距离度量或拼接至特征向量。此外,所有配置均支持从提供的parquet文件(如train-*.parquet)中高效加载,并易于集成到现有的机器学习管道中,从而加速基因组功能预测的研究进程。
背景与挑战
背景概述
在作物基因组学与精准农业的交叉领域,功能性变异位点的预测对于揭示作物表型多样性和环境适应性至关重要。vcrop-smoke-dataset由国际农业生物技术团队于2024年创建,旨在构建基于大规模蛋白语言模型嵌入特征的变异效应预测基准。该数据集通过整合AgroNT1B与NTV3_650M两类预训练模型对参考序列与替代序列的嵌入表征,将作物单核苷酸多态性的功能影响转化为可学习的回归任务。作为首个面向作物变异效应预测的标准化数据集,其发布推动了深度学习方法在农业基因组学中的应用,为理解作物产量、抗病性等重要农艺性状的分子机制提供了关键数据支撑。
当前挑战
数据集所解决的领域问题聚焦于作物基因组中数百万个SNP变异的功能注释自动化,传统依赖实验验证的方法通量低且成本高昂,难以满足现代育种对大规模变异效应快速评估的需求。构建过程中面临的核心挑战包括:不同蛋白语言模型(如AgroNT1B与NTV3_650M)产生的嵌入特征维度与语义空间不一致,需设计统一的多模态融合策略;仅包含100个训练样本的极小样本量极易导致模型过拟合,需采用迁移学习与正则化技术;原始序列数据与嵌入特征混合存储,需构建高效的批量加载管道以避免内存溢出。此外,标签来源于跨物种同源比对或弱监督信号,其噪声水平与置信度评估亦构成技术难点。
常用场景
经典使用场景
vcrop-smoke-dataset是专为农作物基因组变异效应预测而设计的高质量数据集,其核心应用在于利用大规模预训练基因组语言模型(如Agro-NT、NT-v3)的嵌入表征,训练能够判别单核苷酸多态性(SNP)对作物表型调控影响的分类或回归模型。该数据集中每一对参考与替代等位基因序列均附带从不同基因语言模型提取的均值与SNP位点嵌入向量,从而支持基于上下文语义的变异效应量化分析。研究人员通常采用该数据集构建跨作物、跨物种的变异效应预测框架,评估基因组语言模型在农业基因组学中的迁移能力。
衍生相关工作
基于vcrop-smoke-dataset,研究者衍生出多项经典工作,包括开发融合多种基因语言模型嵌入的集成变异效应预测器,以及构建面向作物全基因组范围的零样本效应打分框架。部分工作进一步将数据集扩展至多模态场景,整合表观基因组与转录组信息以提升预测精度。该数据集还催生了针对不同作物品种的微调迁移学习范式,验证了从大语言模型到农业基因组任务的知识迁移有效性,极大丰富了计算农业生物学的技术体系。
数据集最近研究
最新研究方向
在农业基因组与计算生物学交叉领域,vcrop-smoke-dataset聚焦于作物基因组变异的功能预测与模型解释性研究。该数据集整合了参考序列与替代序列的核苷酸级嵌入表示(如ref_embedding_mean与alt_embedding_snp),并结合了来自大规模预训练模型(agro_nt_1b与ntv3_650m)的深度特征,为探索单核苷酸多态性(SNP)对作物表型影响的分子机制提供了高质量基准。近期研究借助该数据集推动了对非编码区功能性变异效应的精细量化,尤其是在杂合位点的反事实推理方面,cosine_mean等相似性度量被用于评估变异前后嵌入空间的偏移程度,从而揭示潜在的关键调控位点。这一方向与当前作物育种中利用语言模型进行基因型-表型预测的热点紧密相关,能够有效弥合序列变异与农业性状之间的解释鸿沟,加速智能育种中的因果变异筛选进程。
以上内容由遇见数据集搜集并总结生成


