Emakhuwa-FLORES
收藏arXiv2024-08-21 更新2024-08-23 收录
下载链接:
https://huggingface.co/datasets/LIACC/Emakhuwa-FLORES
下载链接
链接失效反馈官方服务:
资源简介:
Emakhuwa-FLORES数据集由人工智能与计算机科学实验室(LIACC / LASI)创建,专门用于评估葡萄牙语到Emakhuwa语的机器翻译性能。该数据集包含2009条句子,分为dev和devtest两个子集,通过专业的翻译和多轮质量检查确保数据质量。数据集的创建过程包括数据准备、翻译和验证三个主要步骤,旨在解决Emakhuwa语这种低资源语言在机器翻译领域的挑战。
The Emakhuwa-FLORES dataset was created by the Laboratory for Artificial Intelligence and Computer Science (LIACC / LASI), specifically designed to evaluate machine translation performance from Portuguese to Emakhuwa. This dataset contains 2009 sentences, split into two subsets: dev and devtest. Its data quality is ensured through professional translation and multi-round quality inspections. The dataset creation process includes three main steps: data preparation, translation, and validation, aiming to address the challenges faced by low-resource languages like Emakhuwa in the field of machine translation.
提供机构:
人工智能与计算机科学实验室(LIACC / LASI)
创建时间:
2024-08-21
原始信息汇总
数据集卡片
描述
FLORES+ dev 和 devtest 集在 Emakhuwa 语言中。
许可证
CC-BY-SA-4.0
归属
Felermino D. M. Antonio Ali, Henrique Lopes Cardoso, 和 Rui Sousa-Silva 应被认为是该数据集的创建者。
bibtex @misc{ali2024expandingfloresbenchmarklowresource, title={Expanding FLORES+ Benchmark for more Low-Resource Settings: Portuguese-Emakhuwa Machine Translation Evaluation}, author={Felermino D. M. Antonio Ali and Henrique Lopes Cardoso and Rui Sousa-Silva}, year={2024}, eprint={2408.11457}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2408.11457}, }
语言代码
- 语言(NLP): Emakhuwa (vmw), Portuguese (pt)
- ISO 639-3: vmw
- ISO 15924: Latn
- Glottocode: cent2033
工作流程
数据从葡萄牙语翻译而来,由两名双语翻译人员完成。所有翻译人员都是专业翻译人员。100% 的数据由三名独立的翻译人员进行了检查。
工作流程分为三个主要步骤:
-
数据准备:
- 从 devtest 和 dev 集中编译句子并加载到 Matecat CAT 工具中。
- 准备了指南和词汇表以标准化翻译过程。指南改编自 OLDI 指南,用葡萄牙语编写,重点关注 Emakhuwa 的中央变体。词汇表通过数字化现有的双语词典和莫桑比克广播电台的词汇表创建,确保翻译的一致性并最小化借词使用。
-
翻译:
- 翻译任务由两名翻译人员分担。他们使用拼写检查系统识别潜在的拼写错误,并根据反馈进行纠正。
-
验证:
- 这一步骤包括修订和判断。翻译作品在翻译人员之间交换进行后期编辑。
- 还使用了直接评估方法,三位评分员在 0 到 100 的范围内评估翻译的充分性,以衡量翻译对原始含义的保留程度。
额外指南
我们还要求翻译人员在翻译每个段落时标记适应到 Emakhuwa 中的借词。
- 资助方: 该数据集是在 Lacuna Fund 的支持下创建的,Lacuna Fund 是全球首个合作努力,旨在为全球低收入和中等收入背景的数据科学家、研究人员和社会企业家提供他们所需的资源,以生产解决其社区紧迫问题的标记数据集。Lacuna Fund 是一个资助者合作组织,包括 The Rockefeller Foundation、Google.org、加拿大国际发展研究中心、德国联邦经济合作与发展部(BMZ)与 GIZ 作为执行机构、Wellcome Trust、Gordon and Betty Moore Foundation、Patrick J. McGovern Foundation 和 The Robert Wood Johnson Foundation。更多信息请参见 https://lacunafund.org/about/。
搜集汇总
数据集介绍
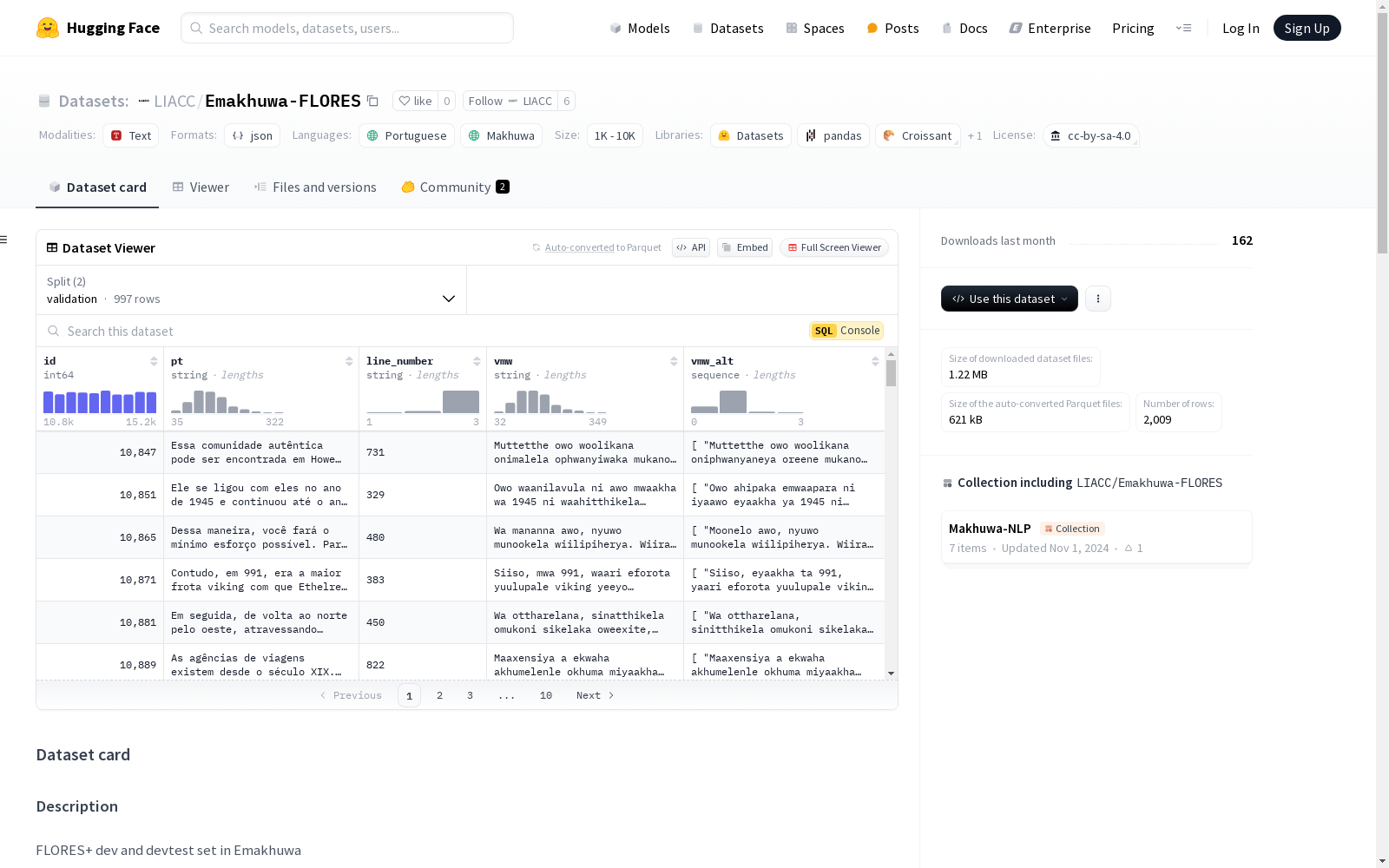
构建方式
Emakhuwa-FLORES数据集的构建是通过将葡萄牙语翻译成Emakhuwa语来实现的。这个数据集包括由Open Language Data Initiative (OLDI)管理的dev和devtest集,分别包含997个和1012个句子。翻译过程包括由专业人士进行的翻译、修订和验证。为了保证翻译质量,研究人员采用了多种质量检查措施,包括后期编辑和充足性评估。最终的数据集包含了每个源句的多个参考句子。
特点
Emakhuwa-FLORES数据集的主要特点是它是一个针对低资源语言的机器翻译评估数据集,特别是针对莫桑比克的Emakhuwa语。该数据集的构建采用了严格的质量保证机制,包括详尽的后期编辑。数据集包含了多个参考翻译,这些翻译是从后期编辑的努力中产生的。此外,该数据集还揭示了Emakhuwa语拼写不一致的挑战,这对于语言技术处理构成了重大障碍。
使用方法
Emakhuwa-FLORES数据集可以用于训练和评估神经机器翻译模型。研究人员可以使用这个数据集来训练模型,并使用BLEU和ChrF等指标来评估模型的性能。此外,该数据集还可以用于研究Emakhuwa语的特点,以及如何提高低资源语言的机器翻译质量。
背景与挑战
背景概述
自然语言处理领域,尤其是机器翻译,长期受到资源丰富语言与低资源语言之间发展不平衡的挑战。为了解决这一问题,FLORES+评价集应运而生,旨在为低资源语言提供更多的评估工具。FLORES+评价集最初由Guzmán等人于2019年提出,随后经过多次扩展,包含了越来越多的语言对。本研究聚焦于将FLORES+评价集扩展至莫桑比克广泛使用的低资源语言——Emakhuwa。研究人员通过翻译葡萄牙语至Emakhuwa,建立了包含997个句子和1012个句子的dev和devtest数据集。在数据收集过程中,他们实施了严格的质量保证机制,包括彻底的后期编辑。最终形成的数据集包含多个参考翻译,为低资源语言的机器翻译研究提供了宝贵资源。
当前挑战
尽管Emakhuwa数据集的建立为低资源语言的机器翻译研究提供了重要支持,但仍面临一些挑战。首先,Emakhuwa的数字化资源稀缺,拼写标准尚未完全建立。这导致了拼写不一致的问题,特别是在标记声调时。其次,Emakhuwa的粘着性特征和复杂的形态学进一步加剧了拼写差异。此外,Emakhuwa文本语料库中经常出现来自葡萄牙语的借词,这些借词的改编方式不统一,也影响了数据的一致性。在构建数据集的过程中,研究人员通过翻译、后期编辑和验证等步骤,努力提高翻译质量,但仍需进一步研究以提高Emakhuwa的机器翻译质量。
常用场景
经典使用场景
在低资源语言的机器翻译领域中,Emakhuwa-FLORES数据集的经典使用场景是作为评估和训练神经机器翻译模型的标准数据集。该数据集包含了从葡萄牙语到Emakhuwa语的平行文本,为研究者提供了宝贵的资源,以评估和改进低资源语言的机器翻译系统的性能。
实际应用
Emakhuwa-FLORES数据集在实际应用中,可以用于构建和改进面向Emakhuwa语的机器翻译系统。该数据集可以帮助开发人员训练更准确的翻译模型,从而促进跨语言交流和信息的传播。此外,该数据集还可以用于开发面向低资源语言的文本处理工具,如拼写检查器和语法检查器。
衍生相关工作
Emakhuwa-FLORES数据集的发布,为低资源语言机器翻译领域的研究提供了重要的推动力。基于该数据集的研究工作已经取得了一系列成果,包括改进的翻译模型和评估指标。此外,该数据集还激发了更多研究者关注和探索低资源语言NLP技术,为该领域的发展做出了重要贡献。
以上内容由遇见数据集搜集并总结生成


