cc12m-cleaned
收藏Hugging Face2024-11-02 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/opendiffusionai/cc12m-cleaned
下载链接
链接失效反馈官方服务:
资源简介:
该数据集基于Conceptual Captions 12million数据集和CaptionEmporium的LLaVa标注子集构建,通过过滤和手动移除带有水印、艺术家签名等的图像,得到一个大部分没有图像内标注、水印和其他干扰因素的数据集。当前大小约为900万张图像,提供了一个脚本用于下载实际图像。
This dataset is constructed based on the Conceptual Captions 12M dataset and the LLaVa-annotated subset of CaptionEmporium. By filtering and manually removing images containing watermarks, artist signatures and other similar disturbances, a dataset largely free of in-image annotations, watermarks and other interfering factors is obtained. Currently, it contains approximately 9 million images, and a script is provided for downloading the actual image files.
创建时间:
2024-10-31
原始信息汇总
CC12m-cleaned 数据集概述
基本信息
- 许可证: CC BY-SA 4.0
- 语言: 英语 (en)
- 任务类别:
- 文本到图像生成
- 图像分类
- 标签: 合成字幕 (synthetic-captions)
- 数据集大小: 1M < n < 10M
数据集来源
- 基于两个数据集构建:
- Conceptual Captions 12million
- CaptionEmporium 提供的 LLaVa 字幕子集
数据集处理
- 使用 LLaVa 字幕作为基础,过滤掉包含水印、艺术家签名等干扰因素的图像。
- 手动移除所有来自 "dreamstime.com" 及其他类似网站的图像,因为这些图像中心通常带有水印。
当前规模
- 截至 2024/10/31,数据集包含约 900 万张图像。
下载方式
- 数据集仅提供图像的网络引用,未包含实际图像文件。
- 提供了一个示例脚本
crawl.sh,用户可根据需要调整以下载所有图像。
搜集汇总
数据集介绍
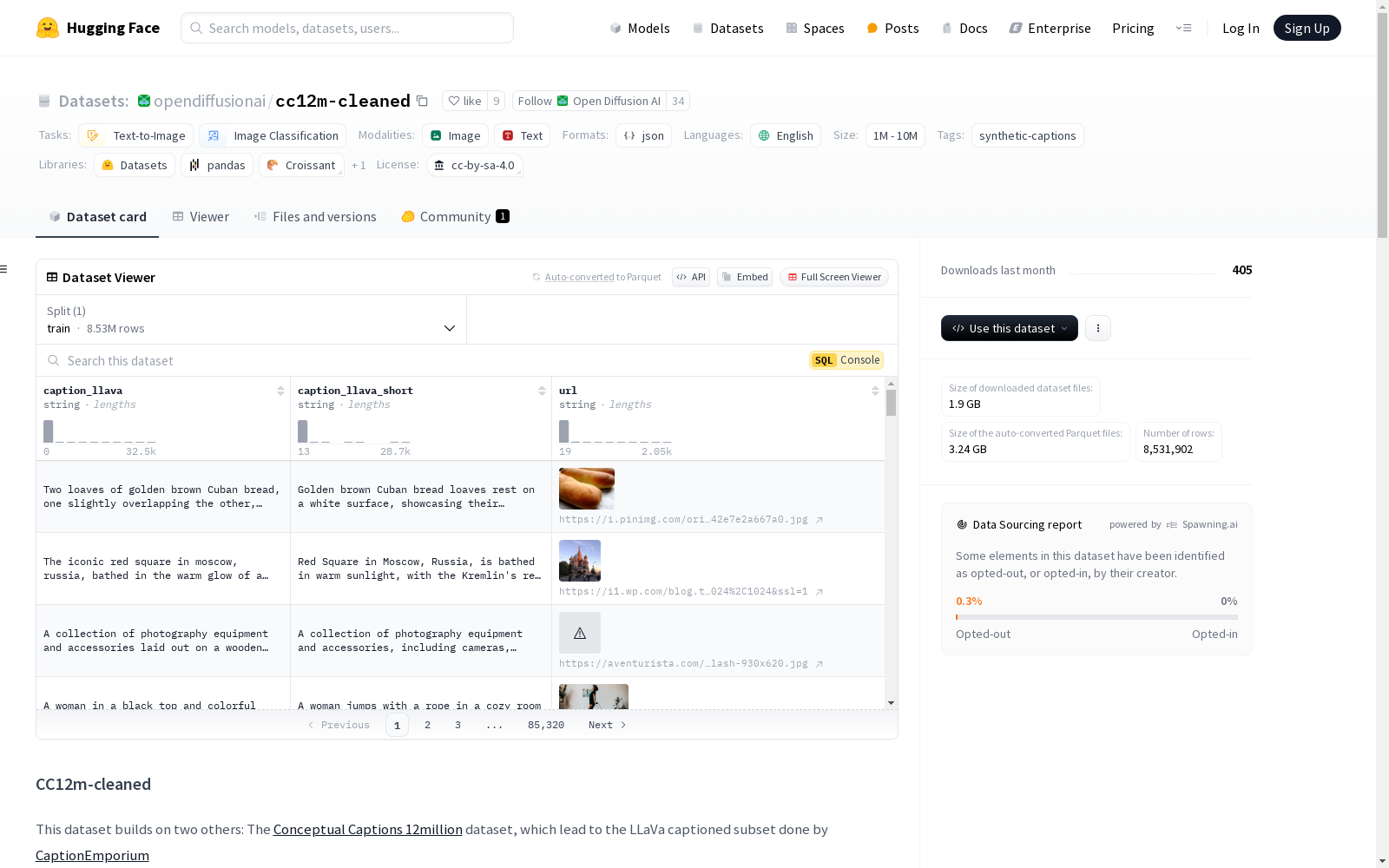
构建方式
CC12m-cleaned数据集基于Conceptual Captions 12million数据集构建,并通过CaptionEmporium项目生成的LLaVa标注子集进行优化。在此基础上,作者进一步筛选了包含水印、艺术家签名等干扰因素的图像,并手动剔除了所有来自dreamstime.com等带有中心水印的图片。最终,该数据集在保留高质量图像的同时,显著减少了可能影响AI图像模型训练的干扰元素。
特点
CC12m-cleaned数据集的主要特点在于其高度净化的图像内容。通过严格的筛选机制,数据集剔除了水印、拼贴画、分屏图像等可能干扰模型训练的元素,确保了图像数据的纯净性。此外,数据集以JSONL格式存储,便于用户通过grep等工具快速提取子集,极大提升了数据处理的灵活性。
使用方法
使用CC12m-cleaned数据集时,用户可通过提供的crawl.sh脚本下载实际图像。脚本支持自定义下载选项,例如排除极端宽高比的图像。数据集以JSONL格式存储,用户可通过grep命令快速筛选特定子集,并结合img2dataset工具进行图像下载。此外,用户还可利用提供的工具进行水印检测等进一步处理,以满足特定研究需求。
背景与挑战
背景概述
CC12m-cleaned数据集是基于Conceptual Captions 12million数据集构建的,后者由Google Research开发,旨在为图像生成高质量的文本描述。该数据集的核心研究问题在于如何通过改进图像描述的质量,提升图像生成模型的性能。CC12m-cleaned数据集进一步优化了原始数据集,通过使用LLaVa生成的描述,过滤掉带有水印、艺术家签名等干扰因素的图像,从而为图像生成和分类任务提供了更为纯净的数据资源。该数据集的创建时间为2024年,由CaptionEmporium团队主导,其影响力主要体现在为图像生成模型的训练提供了更为可靠的数据支持,推动了相关领域的研究进展。
当前挑战
CC12m-cleaned数据集在构建过程中面临多重挑战。首先,原始数据集中的图像描述质量参差不齐,许多描述无法准确反映图像内容,这为数据清洗带来了巨大困难。其次,尽管通过LLaVa生成的描述进行了初步过滤,但仍存在部分水印和干扰元素未被完全剔除,这可能导致模型训练时产生偏差。此外,数据集中的图像具有极端的长宽比,这可能影响某些模型的训练效果。最后,数据集的规模庞大,包含约850万张图像,这使得数据清洗和标注工作极为耗时,尤其是在检测水印等细节时,自动化工具的效率和准确性仍需进一步提升。
常用场景
经典使用场景
在计算机视觉领域,CC12m-cleaned数据集广泛应用于文本到图像生成和图像分类任务。该数据集通过过滤掉带有水印、签名等干扰因素的图像,提供了一个相对纯净的图像资源库,特别适合用于训练高质量的生成模型和分类器。研究人员可以利用该数据集进行图像生成模型的预训练和微调,提升模型在生成图像时的细节表现力和真实性。
实际应用
在实际应用中,CC12m-cleaned数据集被广泛用于图像生成和分类系统的开发。例如,在广告设计、艺术创作和虚拟现实等领域,该数据集可以为生成模型提供高质量的图像素材,帮助生成更加逼真和多样化的图像。此外,该数据集还可以用于图像分类器的训练,提升分类器在实际应用中的准确性和鲁棒性。
衍生相关工作
CC12m-cleaned数据集衍生了许多相关的研究工作,特别是在图像生成和分类领域。基于该数据集,研究人员开发了多种先进的生成模型和分类算法,进一步推动了计算机视觉技术的发展。例如,一些研究利用该数据集进行生成对抗网络(GAN)的预训练,显著提升了生成图像的质量和多样性。此外,该数据集还被用于图像分类器的优化研究,帮助提升了分类器在实际应用中的性能。
以上内容由遇见数据集搜集并总结生成


