有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
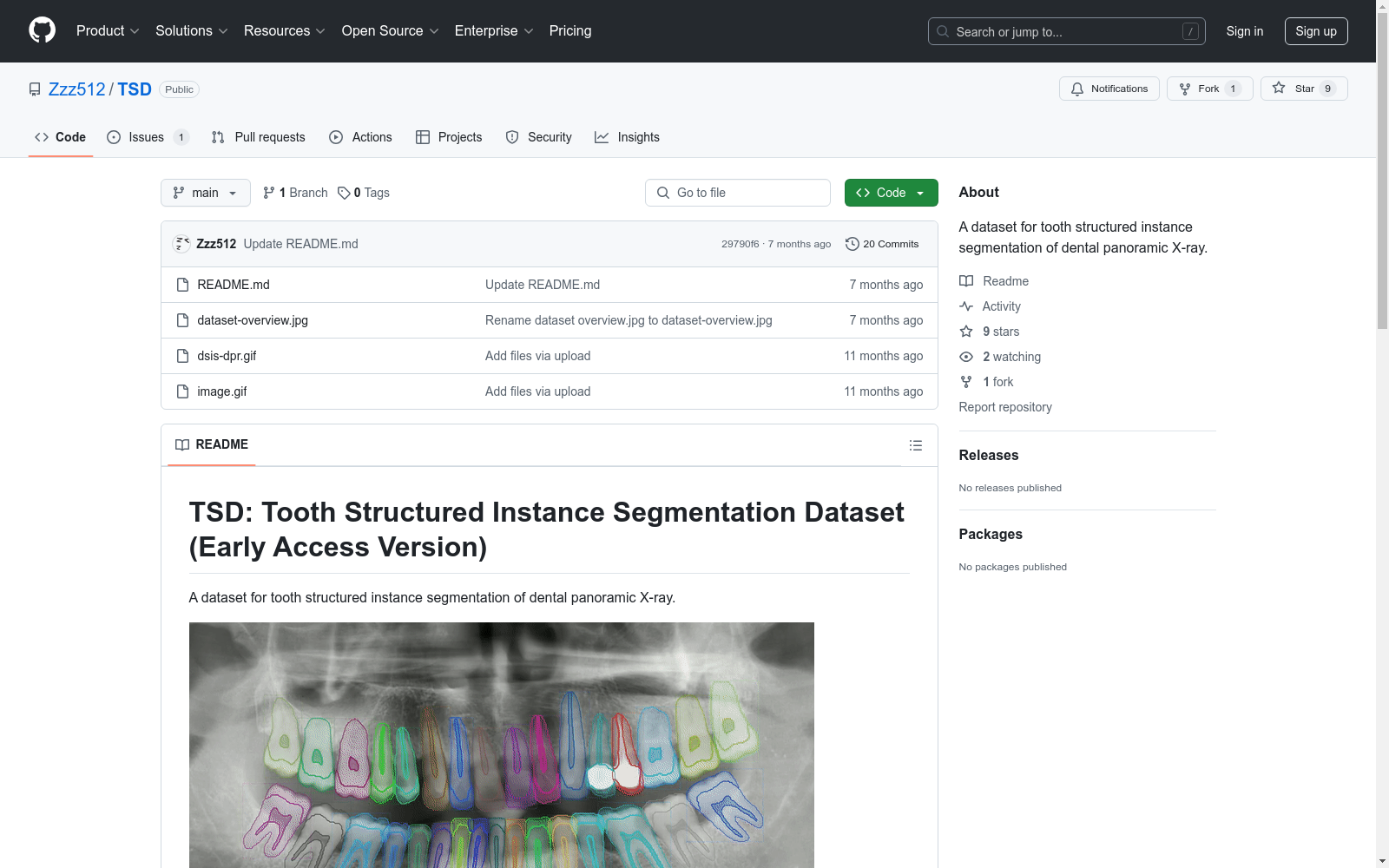
目录结构:
TSD/ ├── images │ ├── img_001.png │ ├── img_002.png │ ├── img_003.png │ └── ... ├── train/val/test_json_files/ │ ├── info │ ├── license │ ├── images_reference │ ├── annotations/ │ │ ├── instance 1 │ │ ├── instance 2 │ │ │ ├── segmentation (list) │ │ │ │ ├── instance_polygons │ │ │ │ ├── dentin_polygons │ │ │ │ ├── pulp_polygons │ │ │ │ ├── materials_polygons │ │ │ │ └── decay_polygons │ │ │ ├── image_id (image ref of instance) │ │ │ ├── instance_bounding_box │ │ │ └── instance_id │ │ └── ... instance n
标注格式: 每个分割标注包含5个项目,所有多边形由一系列点表示,格式为(x1, y1, x2, y2, ...)。
UniProt
UniProt(Universal Protein Resource)是全球公认的蛋白质序列与功能信息权威数据库,由欧洲生物信息学研究所(EBI)、瑞士生物信息学研究所(SIB)和美国蛋白质信息资源中心(PIR)联合运营。该数据库以其广度和深度兼备的蛋白质信息资源闻名,整合了实验验证的高质量数据与大规模预测的自动注释内容,涵盖从分子序列、结构到功能的全面信息。UniProt核心包括注释详尽的UniProtKB知识库(分为人工校验的Swiss-Prot和自动生成的TrEMBL),以及支持高效序列聚类分析的UniRef和全局蛋白质序列归档的UniParc。其卓越的数据质量和多样化的检索工具,为基础研究和药物研发提供了无可替代的支持,成为生物学研究中不可或缺的资源。
www.uniprot.org 收录
CatMeows
该数据集包含440个声音样本,由21只属于两个品种(缅因州库恩猫和欧洲短毛猫)的猫在三种不同情境下发出的喵声组成。这些情境包括刷毛、在陌生环境中隔离和等待食物。每个声音文件都遵循特定的命名约定,包含猫的唯一ID、品种、性别、猫主人的唯一ID、录音场次和发声计数。此外,还有一个额外的zip文件,包含被排除的录音(非喵声)和未剪辑的连续发声序列。
huggingface 收录
多个球状星团的光谱和测光数据集
该数据集是多个球状星团的光谱和测光综合数据集,由意大利国家天体物理学院-帕多瓦天体物理观测站等研究机构的研究人员整理。数据集包含了38个球状星团的恒星在14种化学元素上的丰度信息,包括锂、碳、氮、氧、钠、镁、铝、硅、钾、钙、钛、铁、镍和钡。这些数据来源于多个光谱测量项目,如Apache Point Observatory Galactic Evolution Experiment (APOGEE)、Gaia-ESO Survey (GES)和Galactic Archaeology with HERMES (GALAH)。数据集的目的是研究球状星团中不同恒星星族的化学组成,以揭示其形成和演化的机制。
arXiv 收录
Tropicos
Tropicos是一个全球植物名称数据库,包含超过130万种植物的名称、分类信息、分布数据、图像和参考文献。该数据库由密苏里植物园维护,旨在为植物学家、生态学家和相关领域的研究人员提供全面的植物信息。
www.tropicos.org 收录
中国近海台风路径集合数据集(1945-2024)
1945-2024年度,中国近海台风路径数据集,包含每个台风的真实路径信息、台风强度、气压、中心风速、移动速度、移动方向。 数据源为获取温州台风网(http://www.wztf121.com/)的真实观测路径数据,经过处理整合后形成文件,如使用csv文件需使用文本编辑器打开浏览,否则会出现乱码,如要使用excel查看数据,请使用xlsx的格式。
国家海洋科学数据中心 收录