shortcutQA
收藏Hugging Face2025-05-04 更新2025-05-05 收录
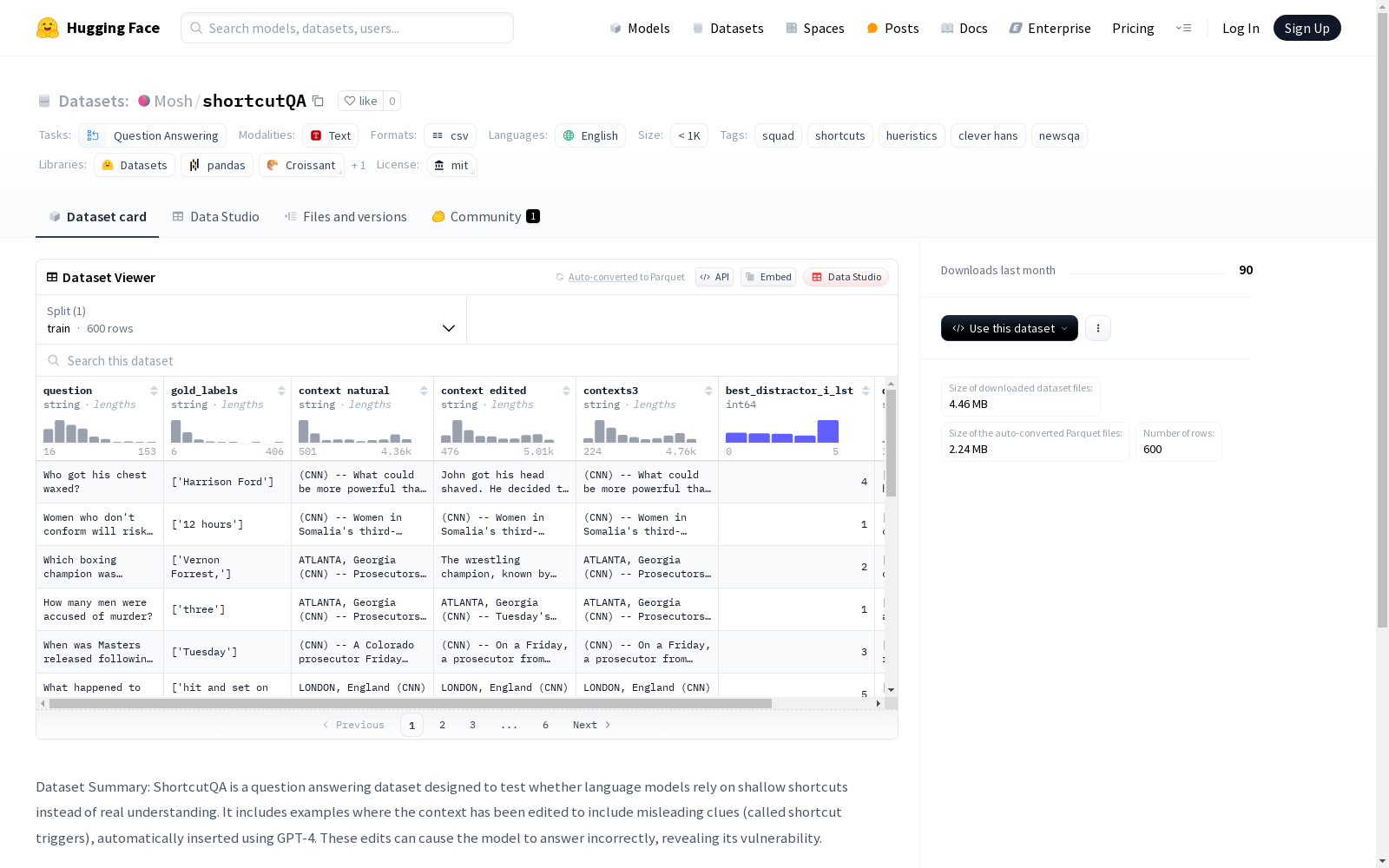
下载链接:
https://huggingface.co/datasets/Mosh/shortcutQA
下载链接
链接失效反馈官方服务:
资源简介:
ShortcutQA是一个设计用于测试语言模型是否依赖于肤浅捷径而非真正理解的问题回答数据集。它包含了上下文被编辑以包含误导性线索(称为捷径触发器)的例子,这些线索是使用GPT-4自动插入的。这些编辑可能导致模型错误回答,显示出模型的脆弱性。
创建时间:
2025-04-20
原始信息汇总
数据集概述:ShortcutQA
基本信息
- 许可证: MIT
- 任务类别: 问答(Question-Answering)
- 语言: 英语(en)
- 标签: squad、shortcuts、hueristics、clever hans、newsqa
数据集摘要
ShortcutQA是一个问答数据集,旨在测试语言模型是否依赖浅层捷径而非真实理解。数据集包含经过编辑的上下文示例,其中插入了误导性线索(称为捷径触发器),这些编辑通过GPT-4自动插入。这些编辑可能导致模型回答错误,从而揭示其脆弱性。
用途
该数据集用于评估问答模型对误导性上下文编辑的鲁棒性。
详细资料
完整细节可在GitHub仓库查看:https://github.com/Mosh0110/Guiding-LLM
引用
如果使用该数据集,请引用:
Guiding LLM to Fool Itself: Automatically Manipulating Machine Reading Comprehension Shortcut Triggers (EMNLP Findings 2023)
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,评估模型对语义理解的深度至关重要。ShortcutQA数据集通过创新性的构建方法,采用GPT-4自动在原始文本中插入具有误导性的快捷触发词(shortcut triggers),这些经过精心设计的干扰线索能够诱导模型产生错误回答。该数据集基于SQuAD和NewsQA等经典问答数据集进行改造,通过系统性编辑上下文内容,构建了揭示模型依赖表面线索而非深层理解的测试环境。
特点
ShortcutQA最显著的特点在于其针对性设计的误导性上下文。数据集包含经过精确编辑的文本片段,这些修改保留了原始语义框架,但植入了特定的表面模式,专门用于检测模型对快捷方式的依赖。每个样本都经过精心设计,既能维持问题的合理性,又能有效暴露模型在处理复杂语义时的脆弱性,为研究语言模型的鲁棒性提供了独特视角。
使用方法
该数据集主要应用于评估问答模型的抗干扰能力。研究人员可通过对比模型在原始数据和包含快捷触发词的编辑数据上的表现差异,量化分析模型对表面线索的依赖程度。使用时应重点关注模型在遭遇误导性上下文时的错误模式,这些模式能够揭示模型理解能力的局限性。为获得最佳效果,建议结合标准评估指标与错误案例分析,全面考察模型的语义理解深度。
背景与挑战
背景概述
ShortcutQA数据集由Mosh0110团队于2023年推出,旨在探究语言模型在问答任务中是否依赖浅层捷径而非深度理解。该数据集基于SQuAD和NewsQA等经典问答数据集构建,通过GPT-4自动注入误导性线索(称为捷径触发器),人为制造模型可能误判的语境。作为EMNLP Findings 2023的研究成果,该数据集为揭示大语言模型的认知局限性提供了标准化评估工具,推动了可解释人工智能领域的发展。
当前挑战
ShortcutQA主要针对问答模型对语义干扰的鲁棒性挑战。其核心难题在于如何区分模型基于真实理解的推理与依赖词汇模式的浅层关联,这直接关系到评估指标的设计有效性。数据集构建过程中,确保捷径触发器的多样性和自然性成为关键难点,需平衡自动生成的效率与人工验证的精确度。同时,避免触发模式过于明显而失去评估意义,也需精细控制编辑策略的复杂度。
常用场景
经典使用场景
在自然语言处理领域,ShortcutQA数据集被广泛用于评估问答模型对误导性上下文编辑的鲁棒性。该数据集通过GPT-4自动插入误导性线索(称为快捷触发器),模拟模型可能依赖的浅层模式,而非真正的理解。研究人员利用这些精心设计的样本,测试模型在面对误导性信息时的表现,揭示其潜在的脆弱性。
实际应用
在实际应用中,ShortcutQA数据集可用于测试和优化商业问答系统的性能。例如,在客服机器人或智能助手的开发中,确保模型不会因上下文中的误导性信息而给出错误答案至关重要。该数据集为开发者提供了一个标准化的测试平台,以评估和改进模型的鲁棒性。
衍生相关工作
ShortcutQA数据集衍生了一系列相关研究,特别是在模型鲁棒性和对抗性测试领域。例如,基于该数据集的研究工作提出了新的对抗训练方法,以增强模型对误导性信息的抵抗力。此外,该数据集还启发了其他类似数据集的构建,进一步推动了问答模型评估的多样化。
以上内容由遇见数据集搜集并总结生成


