tricky-tts-public
收藏Hugging Face2026-03-31 更新2026-04-01 收录
下载链接:
https://huggingface.co/datasets/Trelis/tricky-tts-public
下载链接
链接失效反馈官方服务:
资源简介:
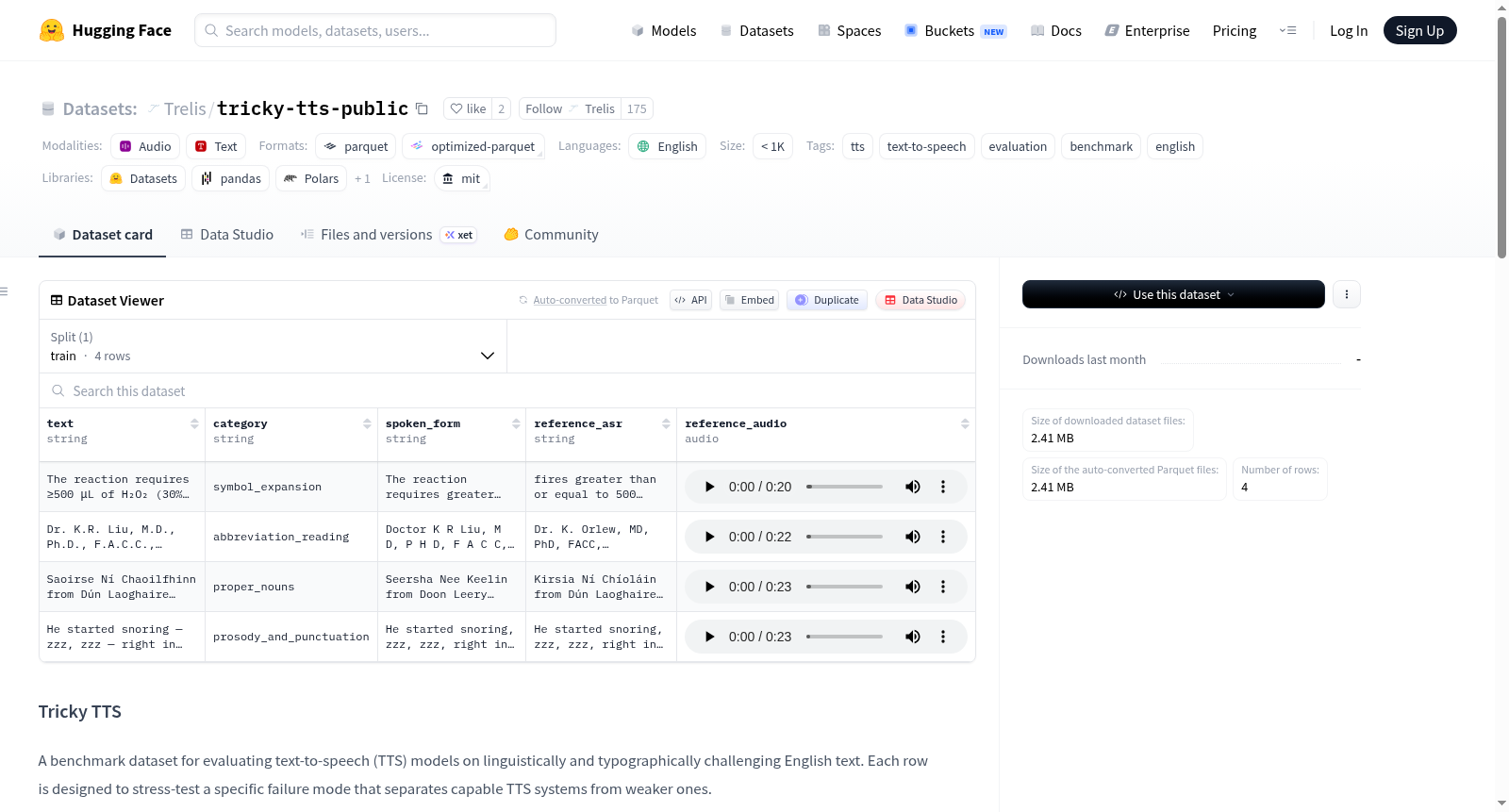
Tricky TTS 是一个用于评估文本转语音(TTS)模型在语言学和排版挑战性英语文本上的基准数据集。该数据集旨在通过特定的挑战类别来测试TTS系统的能力,区分性能强弱。数据集包含四类挑战:符号扩展(如Unicode符号、单位和运算符)、缩写阅读(如首字母缩略词、罗马数字和带点标题)、专有名词(如爱尔兰/凯尔特名称、HuggingFace模型路径和品牌名称)以及韵律和标点(如长破折号、省略号、拟声词和节奏)。每行数据包含以下字段:文本(text)、类别(category)、口语形式(spoken_form,即标准化参考转录)、参考音频(reference_audio,人类语音录音,webm格式)和参考ASR(reference_asr,通过Trelis Studio ASR评估的参考音频转录)。数据集使用MIT许可证发布,适用于TTS模型的评估和基准测试。
提供机构:
Trelis创建时间:
2026-03-31
原始信息汇总
Tricky TTS 数据集概述
基本信息
- 数据集名称: Tricky TTS
- 托管地址: https://huggingface.co/datasets/Trelis/tricky-tts-public
- 许可证: MIT
- 语言: 英语 (en)
- 标签: tts, text-to-speech, evaluation, benchmark, english
数据集简介
Tricky TTS 是一个用于评估文本转语音(TTS)模型在语言学和排版学上具有挑战性的英文文本上的性能的基准数据集。每一行数据都旨在对特定的失败模式进行压力测试,以区分能力强和较弱的 TTS 系统。
评估方法
- 往返 ASR 字符错误率 (CER): TTS 模型生成音频 → Whisper 转录回文本 → 与人工参考转录计算 CER。
- 平均意见得分 (MOS,自然度): 对生成音频使用 UTMOS 评分。
数据集内容
数据集包含 4 行数据,覆盖四个挑战类别:
| 类别 | 测试内容 |
|---|---|
symbol_expansion |
Unicode 符号、单位、运算符 — 例如 ≥, μL, ±, ×10⁶ |
abbreviation_reading |
首字母缩略词、缩写词、罗马数字、带点的头衔 — 例如 IEEE, Vol. XII, F.A.C.C. |
proper_nouns |
爱尔兰/凯尔特名字、HuggingFace 模型路径、品牌名称 |
prosody_and_punctuation |
长破折号、省略号、拟声词、节奏 — 例如 zzz, Psst, whoosh |
数据列:
text: 挑战性文本。category: 文本所属的挑战类别。spoken_form: 归一化的参考转录文本。reference_audio: 人工录制的语音(webm 格式)。reference_asr: 通过 Trelis Studio ASR 评估(使用openai/whisper-large-v3)对参考音频的转录。
使用方法
python from datasets import load_dataset ds = load_dataset("Trelis/tricky-tts-public", split="train") for row in ds: print(row["category"], row["text"])
排行榜
评估使用往返 ASR(以 Whisper large-v3 转录人工参考音频,使用 fireworks/whisper-v3 评分)和 UTMOS 的 MOS 分。人工参考音频的 MOS 得分为 4.22。
| 排名 | 模型 | MOS ↑ | CER ↓ | 评估数据集 |
|---|---|---|---|---|
| 1 | Gemini Pro TTS | 4.227 | 0.112 | https://huggingface.co/datasets/Trelis/tricky-tts-gemini-pro-tts |
| 2 | GPT-4o mini TTS | 4.330 | 0.121 | https://huggingface.co/datasets/Trelis/tricky-tts-gpt-4o-mini-tts |
| 3 | Gemini Flash TTS | 4.184 | 0.122 | https://huggingface.co/datasets/Trelis/tricky-tts-gemini-flash-tts |
| 4 | ElevenLabs | 4.273 | 0.192 | https://huggingface.co/datasets/Trelis/tricky-tts-elevenlabs |
| 5 | Kokoro | 4.511 | 0.209 | https://huggingface.co/datasets/Trelis/tricky-tts-kokoro |
| 6 | Orpheus | 4.152 | 0.229 | https://huggingface.co/datasets/Trelis/tricky-tts-orpheus |
| 7 | Cartesia Sonic-3 | 4.019 | 0.259 | https://huggingface.co/datasets/Trelis/tricky-tts-cartesia-sonic-3 |
| 8 | Piper (en-gb) | 3.777 | 0.323 | https://huggingface.co/datasets/Trelis/tricky-tts-piper-en-gb |
| 9 | Mistral Voxtral-Mini | 4.289 | 0.569 | https://huggingface.co/datasets/Trelis/tricky-tts-mistral |
| 10 | Chatterbox | 4.100 | 0.583 | https://huggingface.co/datasets/Trelis/tricky-tts-chatterbox |
搜集汇总
数据集介绍
构建方式
在文本转语音技术日益精进的背景下,Tricky TTS数据集的构建旨在系统性地评估模型在复杂语言场景下的表现。该数据集通过精心设计的四行文本,覆盖了符号扩展、缩写朗读、专有名词以及韵律与标点四大挑战类别,每一行文本均针对特定的失败模式进行压力测试。构建过程中,借助Trelis Studio平台进行评测,并采用人类参考音频与Whisper转录作为基准,确保了数据集的科学性与可靠性。
使用方法
使用Tricky TTS数据集时,研究人员可通过Hugging Face的datasets库直接加载,便捷地访问数据集中的文本与类别信息。该数据集主要用于评估文本转语音模型的性能,通过循环自动语音识别错误率与平均意见得分等指标,量化模型在复杂文本上的生成质量。用户可参照提供的评测方法,将模型输出与人类参考音频进行对比,从而深入分析模型在特定挑战类别上的表现,推动语音合成技术的精准改进。
背景与挑战
背景概述
Tricky TTS数据集由Trelis机构构建,旨在为文本到语音合成模型的评估提供专业基准。该数据集聚焦于英语中语言学和排版学层面的复杂文本,通过精心设计的测试用例,系统性地揭示TTS模型在特定失败模式上的性能差异。其核心研究问题在于如何准确评估TTS系统在处理非常规文本元素时的鲁棒性与自然度,从而推动语音合成技术向更高精度与泛化能力发展。该数据集的建立为学术界与工业界提供了一个标准化测试平台,显著促进了TTS模型评估方法的科学化与精细化。
当前挑战
该数据集致力于解决文本到语音合成领域在处理复杂语言现象时面临的挑战,具体包括模型对Unicode符号、单位与运算符的正确扩展,对缩写、首字母缩略词及罗马数字的准确朗读,以及对特定专有名词与品牌名称的发音一致性。在构建过程中,挑战主要集中于设计能够全面覆盖各类语言边缘案例的测试文本,并确保人类参考音频与转写标注的高质量与一致性,以建立可靠评估基准。这些挑战共同指向了提升TTS系统在真实世界复杂语境下实用性与可靠性的核心难题。
常用场景
解决学术问题
该数据集有效解决了语音合成研究中模型泛化能力不足的学术难题。传统评估往往忽视语言学和排版上的边缘案例,导致模型在实际应用中表现不稳定。Tricky TTS通过引入Unicode符号、专业缩写、文化特定名称及复杂标点等挑战,填补了评估体系的空白,推动了模型在细粒度语言理解方面的进步,为提升合成语音的准确性与自然度奠定了实证基础。
实际应用
在实际应用中,Tricky TTS数据集为智能助手、有声读物生成和辅助技术等场景提供了关键的质量保障。例如,在医疗或工程领域,系统需准确朗读包含“μL”或“IEEE”等专业术语的文本;在跨文化交互中,正确发音爱尔兰人名或品牌名称至关重要。该数据集帮助开发者识别并修复模型在这些边缘案例中的缺陷,确保语音输出在多样化的现实环境中保持可靠与清晰。
数据集最近研究
最新研究方向
在语音合成领域,随着模型性能的普遍提升,评估焦点正从基础的自然度转向对复杂语言现象的鲁棒性处理。Tricky TTS数据集应运而生,专门针对符号扩展、缩写读法、专有名词及韵律标点等挑战性文本设计,旨在系统性地揭示TTS系统在边缘场景下的失败模式。当前研究前沿紧密围绕该数据集展开,通过结合循环ASR错误率与UTMOS自然度评分,构建了多维度评估基准,驱动模型在语义理解与发音准确性上的协同优化。相关热点事件体现在各大科技公司如Google、OpenAI及ElevenLabs等竞相在此基准上测试其最新TTS模型,形成了公开的排行榜竞争,这不仅加速了模型迭代,也为实际应用如无障碍服务与多语言交互提供了关键的可靠性验证。
以上内容由遇见数据集搜集并总结生成


