AmanMussa/kazakh-instruction-v2
收藏Hugging Face2023-11-16 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/AmanMussa/kazakh-instruction-v2
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
task_categories:
- question-answering
- text-generation
language:
- kk
size_categories:
- 10K<n<100K
---
# Dataset Card for Dataset Name
Self-instruct data pairs for Kazakh language
## Dataset Details
The dataset is translated from Standford Alpaca instruction dataset via Google Translations API.
1. Manually fixed the translation error.
2. Common names and places of Kazakhstan were added.
3. Intructions of kazakhstan history and cultures were added.
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
- **Curated by:** Mussa Aman
- **Language(s) (NLP):** Kazakh
- **License:** MIT
## Uses
This dataset is curated to fine-tune the LLaMA 2 model for the Kazakh language. It aims to enhance the model's understanding and processing capabilities of Kazakh, addressing a gap in the Low Resource Lanuguages for solving the NLP resources for Kazakh language.
The dataset includes the self-instruct approach, there is commonly one "instruction","input" and "output" which is crucial for improving language comprehension and task performance of the model.
## Citation
**BibTeX:**
@misc{aman_2023,
author = {Aman Mussa},
title = {Self-instruct data pairs for Kazakh language},
year = {2023},
howpublished = {\url{https://huggingface.co/datasets/AmanMussa/instructions_kaz_version_1}},
}
**APA:**
Aman, M. (2023). Self-instruct data pairs for Kazakh language. Retrieved from https://huggingface.co/datasets/AmanMussa/instructions_kaz_version_1
## Dataset Card Contact
Please contact in email: a_mussa@kbtu.kz
许可证:MIT许可证
任务类别:
- 问答
- 文本生成
语言:
- 哈萨克语(ISO 639-1代码:kk)
规模类别:
- 10000 < 数据量 < 100000
---
# 数据集卡片(数据集名称)
## 哈萨克语自指令数据对
### 数据集详情
本数据集基于斯坦福Alpaca指令数据集(Stanford Alpaca instruction dataset)通过谷歌翻译API(Google Translations API)翻译所得。
1. 手动修正了翻译错误;
2. 补充了哈萨克斯坦常见人名与地名;
3. 新增了哈萨克斯坦历史与文化相关的指令。
#### 数据集描述
- **数据整理者:** 穆萨·阿曼(Mussa Aman)
- **自然语言处理语言:** 哈萨克语
- **许可证:** MIT许可证
### 应用场景
本数据集专为哈萨克语场景下的LLaMA 2模型微调任务整理而成,旨在提升模型对哈萨克语的理解与处理能力,填补哈萨克语自然语言处理资源匮乏的空白。
本数据集采用自指令构建范式,核心包含「指令(instruction)」、「输入(input)」与「输出(output)」三类字段,这一结构对提升模型的语言理解能力与任务执行性能至关重要。
### 引用信息
**BibTeX格式:**
@misc{aman_2023,
author = {Aman Mussa},
title = {Self-instruct data pairs for Kazakh language},
year = {2023},
howpublished = {url{https://huggingface.co/datasets/AmanMussa/instructions_kaz_version_1}},
}
**APA格式:**
Aman, M. (2023). 哈萨克语自指令数据对. 检索自: https://huggingface.co/datasets/AmanMussa/instructions_kaz_version_1
### 数据集卡片联系方式
请发送邮件至:a_mussa@kbtu.kz
提供机构:
AmanMussa
原始信息汇总
数据集卡片 for Dataset Name
数据集详情
该数据集是从Standford Alpaca指令数据集通过Google翻译API翻译而来的。
- 手动修正了翻译错误。
- 添加了哈萨克斯坦的常见名称和地点。
- 添加了关于哈萨克斯坦历史和文化的指令。
数据集描述
- 策划者: Mussa Aman
- 语言(NLP): 哈萨克语
- 许可证: MIT
用途
该数据集旨在微调LLaMA 2模型以适应哈萨克语。它旨在增强模型对哈萨克语的理解和处理能力,解决低资源语言在哈萨克语NLP资源方面的缺口。
数据集包括自指令方法,通常包括一个“指令”、“输入”和“输出”,这对提高模型的语言理解和任务执行能力至关重要。
引用
BibTeX:
@misc{aman_2023, author = {Aman Mussa}, title = {Self-instruct data pairs for Kazakh language}, year = {2023}, howpublished = {url{https://huggingface.co/datasets/AmanMussa/instructions_kaz_version_1}}, }
APA:
Aman, M. (2023). Self-instruct data pairs for Kazakh language. Retrieved from https://huggingface.co/datasets/AmanMussa/instructions_kaz_version_1
数据集卡片联系
请联系邮箱:a_mussa@kbtu.kz
搜集汇总
数据集介绍
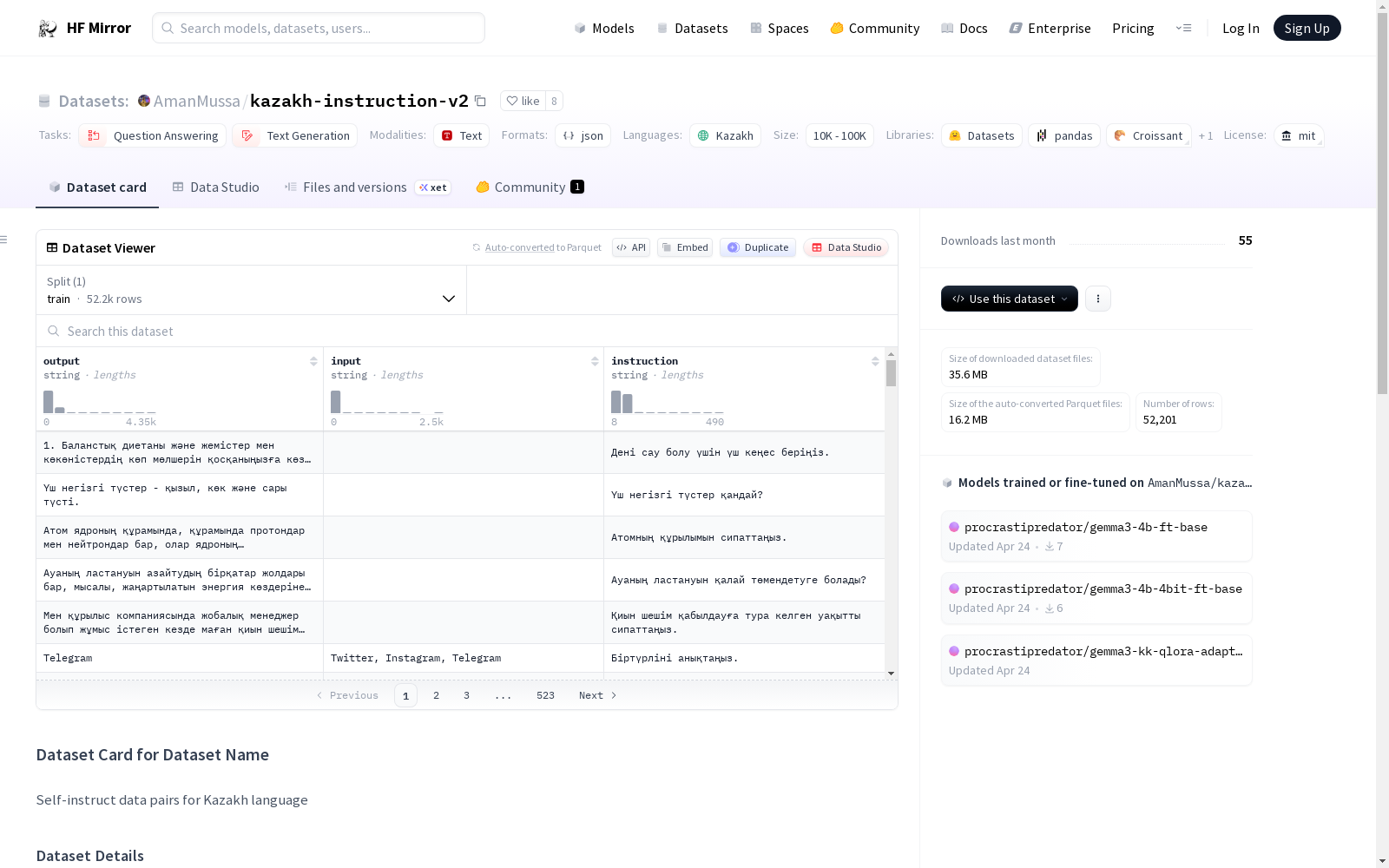
构建方式
在自然语言处理领域,针对低资源语言的指令数据集构建尤为关键。该数据集以斯坦福Alpaca指令数据集为基础,通过Google翻译API将其内容系统性地译为哈萨克语。构建过程中,研究团队不仅细致修正了翻译误差,还融入了哈萨克斯坦常见的人名与地名,并专门增添了涉及哈萨克历史与文化的指令条目,从而确保了数据的准确性与文化相关性。
特点
作为哈萨克语指令数据集,其显著特点在于专为低资源语言环境设计,填补了哈萨克语在自然语言处理资源上的空白。数据集采用自指令结构,每条数据通常包含“指令”、“输入”和“输出”三个部分,这种结构有助于模型深入理解语言逻辑并提升任务执行能力。内容上,它不仅涵盖通用指令,还特别整合了本土文化元素,增强了模型对特定语境的处理效果。
使用方法
该数据集主要用于微调LLaMA 2等大语言模型,以提升其对哈萨克语的理解与生成能力。使用者可直接加载数据集,将其应用于指令跟随、问答及文本生成等任务的训练流程中。通过结合自指令结构,模型能够学习从指令到输出的映射关系,从而优化在哈萨克语场景下的性能表现,为低资源语言的自然语言处理应用提供有力支持。
背景与挑战
背景概述
在自然语言处理领域,低资源语言的模型训练长期面临数据稀缺的困境。2023年,由Mussa Aman主导创建的Kazakh-instruction-v2数据集应运而生,旨在填补哈萨克语在指令微调数据方面的空白。该数据集基于斯坦福Alpaca指令数据集,通过谷歌翻译API进行转译,并融入了哈萨克斯坦的历史文化指令及本土专有名词,其核心研究问题聚焦于提升LLaMA 2等大语言模型对哈萨克语的理解与生成能力,为低资源语言的NLP资源建设提供了关键支持。
当前挑战
该数据集致力于解决低资源语言在指令跟随任务中的模型适配挑战,其构建过程亦伴随多重困难。一方面,哈萨克语作为黏着语,其复杂的形态变化和有限的标注资源对模型的语义捕捉与泛化能力提出了更高要求;另一方面,自动翻译产生的语义偏差需人工逐条校正,且文化特定内容的注入要求构建者具备深厚的语言学与地域知识底蕴,这些因素共同构成了数据集质量保障的核心难点。
常用场景
经典使用场景
在低资源语言的自然语言处理领域,哈萨克语作为代表性语言之一,长期面临数据稀缺的挑战。该数据集通过提供高质量的指令-输出对,为研究人员和开发者构建了一个标准化的基准测试平台。其经典使用场景主要集中于大语言模型的指令微调过程,例如基于LLaMA 2架构的模型优化,旨在提升模型对哈萨克语复杂语法结构和文化语境的理解能力。通过模拟真实交互场景,数据集支持模型在问答、文本生成等任务上进行端到端的性能评估与迭代改进。
衍生相关工作
围绕该数据集衍生的经典工作主要集中于低资源语言模型的创新微调策略。例如,研究者通过结合对比学习与指令数据,开发出适应哈萨克语形态复杂性的参数高效微调方法。同时,该数据集也催生了跨语言知识蒸馏框架的优化研究,促使如mT5、BLOOM等多语言模型在哈萨克语任务上实现性能突破。部分工作进一步探索了文化敏感内容的生成评估机制,为语言技术伦理研究提供了案例支持。
数据集最近研究
最新研究方向
在低资源语言处理领域,哈萨克语作为代表性语种,其数据集构建正成为自然语言处理的前沿热点。AmanMussa/kazakh-instruction-v2数据集通过自指令方法,结合本地化文化历史内容,为LLaMA 2等大语言模型的微调提供了关键支持。当前研究聚焦于跨语言指令对齐与知识迁移,旨在提升模型对哈萨克语的语义理解和任务执行能力,推动低资源语言在人工智能时代的数字化发展,具有重要的学术价值与社会意义。
以上内容由遇见数据集搜集并总结生成


