Assemblage
收藏arXiv2024-05-07 更新2024-06-21 收录
下载链接:
https://assemblage-dataset.net/
下载链接
链接失效反馈官方服务:
资源简介:
Assemblage是一个云基础分布式系统,用于自动构建高质量的Windows PE二进制数据集,适用于训练最先进的二进制分析模型。该数据集包括890k Windows PE和428k Linux ELF二进制文件,覆盖了多种编译器版本和优化设置。Assemblage通过爬取代码托管平台,下载开源项目,并使用多种编译器版本和设置进行编译,记录必要信息以重建从输出到源代码的字节级映射。数据集的应用领域包括逆向工程、恶意软件分类和漏洞发现等。
Assemblage is a cloud-based distributed system designed to automatically construct high-quality Windows PE binary datasets for training state-of-the-art binary analysis models. The dataset consists of 890k Windows PE and 428k Linux ELF binary files, covering a wide range of compiler versions and optimization settings. Assemblage crawls code hosting platforms to download open-source projects, compiles these projects using multiple compiler versions and settings, and records necessary information to reconstruct byte-level mappings between the compiled outputs and their corresponding source code. The dataset has applications in multiple domains including reverse engineering, malware classification, vulnerability discovery, and other related fields.
提供机构:
雪城大学
创建时间:
2024-05-07
搜集汇总
数据集介绍
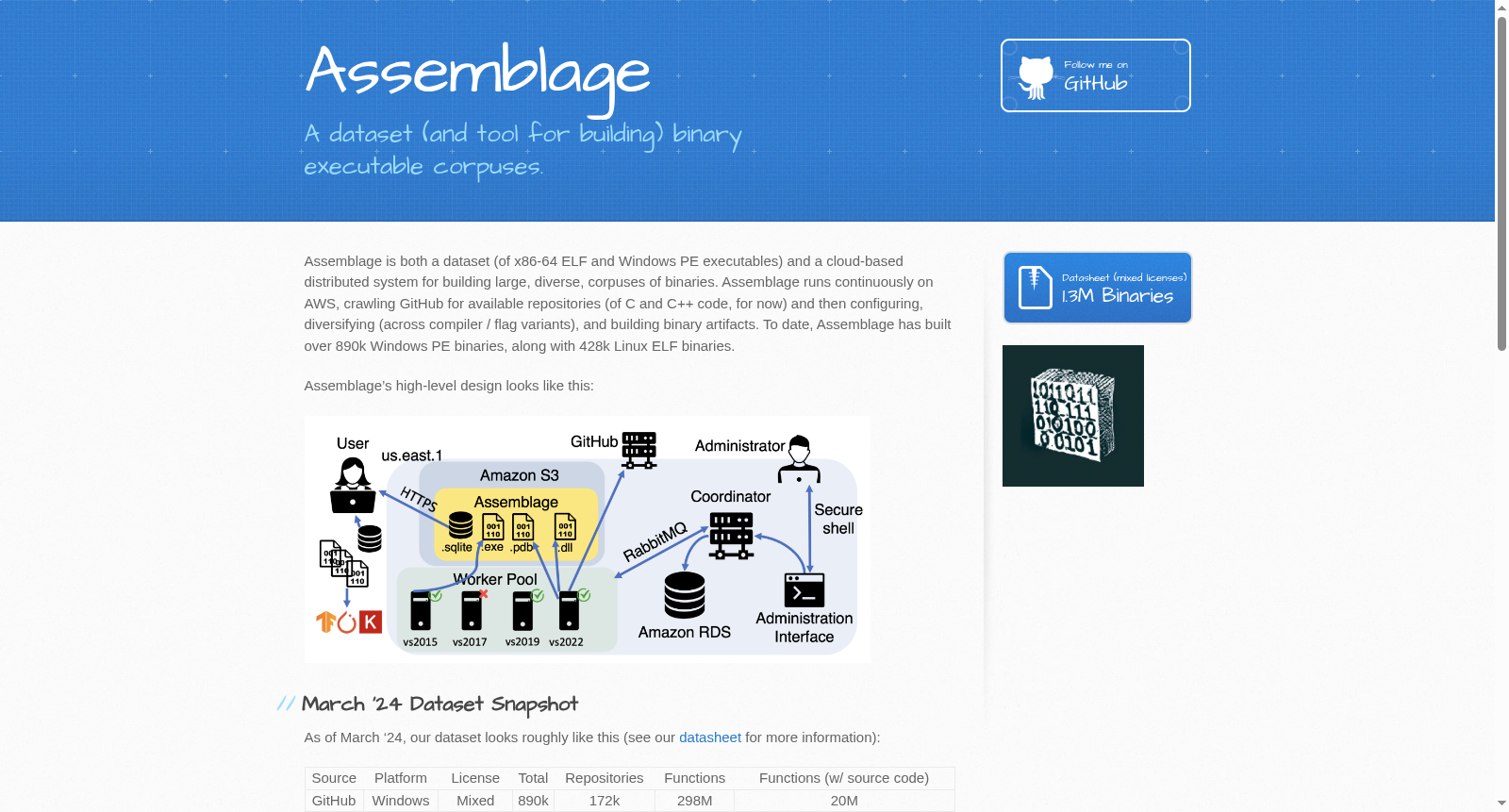
构建方式
Assemblage 数据集构建于一个可扩展的云原生分布式系统之上,该系统通过爬取代码托管平台(如 GitHub)上的开源项目,自动完成配置、编译与打包流程。系统采用星型拓扑架构,由中央协调节点、自适应工作节点池及数据库接口组成。协调节点负责任务分发与状态管理,工作节点则监听特定通道,执行克隆仓库、编译二进制文件的任务。针对 Windows PE 二进制文件,Assemblage 利用 Microsoft Visual Studio 工具链并编写自动化脚本以克服图形界面依赖;针对 Linux ELF 文件,则通过 Docker 容器化部署 GCC 与 Clang 编译器。最终,系统将生成的二进制文件、PDB 文件及编译元数据存储于 SQLite 数据库中,形成结构化的数据集。
特点
Assemblage 数据集的核心特点在于其规模宏大、来源多样且标注精细。该数据集包含超过 89 万 Windows PE 二进制文件与 42.8 万 Linux ELF 二进制文件,覆盖 29 种不同的编译配置组合,涉及多种编译器版本、优化级别及 CPU 架构。尤为突出的是,Assemblage 详尽记录了从源代码到二进制文件的完整编译溯源信息,包括指令级别的映射关系,并通过 PDB 文件提供精确的函数边界与名称,克服了传统反汇编工具(如 IDA Pro)在 Windows 二进制文件上信息丢失的缺陷。此外,数据集通过“配方”机制实现可重现性,允许用户仅凭轻量级脚本即可复现整个构建过程,同时规避了许可证分发难题。
使用方法
Assemblage 数据集的使用方法灵活多样,用户可通过其提供的 SQLite 数据库进行高效查询与定制。数据库包含 binaries、functions、rvas 与 lines 四个核心表,分别存储二进制文件元数据、函数哈希与名称、相对虚拟地址以及源代码行到字节地址的映射。研究人员可根据任务需求,例如编译器溯源或二进制函数相似性检测,通过 SQL 查询筛选特定编译配置、许可证类型或文件大小的子集。数据集还支持与主流机器学习框架(如 PyTorch、TensorFlow)无缝集成,用户可直接将二进制文件及其标注信息输入模型进行训练或评估。此外,Assemblage 提供的“配方”脚本允许用户在不同环境下复现数据集,或通过修改配置实现增量构建与扩展。
背景与挑战
背景概述
二进制分析是逆向工程、恶意软件分类和漏洞发现中的关键任务,然而高质量良性二进制数据集的匮乏长期制约着该领域的发展。现有数据集或依赖成本高昂的商业服务(如VirusTotal),或局限于少量开源二进制文件(如coreutils),且绝大多数研究集中于Linux ELF格式,忽视了在全球操作系统市场中占据约70%份额的Windows平台。为填补这一空白,来自雪城大学、博思艾伦汉密尔顿公司及物理科学实验室的研究团队于2024年提出了Assemblage系统,这是一种可扩展的云原生分布式框架,能够自动爬取、配置并构建Windows PE与Linux ELF二进制文件。通过一年多的AWS部署,Assemblage生成了89万Windows PE和42.8万Linux ELF二进制文件,覆盖29种编译配置,并提供了从源代码到二进制指令级别的完整溯源信息。该数据集不仅解决了许可分发难题,更通过“配方”机制确保了可复现性,为现代基于大语言模型的二进制分析研究提供了前所未有的数据支撑。
当前挑战
Assemblage面临的核心挑战体现在三个层面。首先,领域问题层面,现有机器学习驱动的二进制分析方法几乎完全依赖Linux ELF数据集训练,但实验表明,在Linux上表现优异的模型(如PassTell的编译器溯源模型与jTrans的二进制相似性检测模型)迁移至Windows PE领域时性能急剧下降,这揭示了跨平台泛化能力的严重不足。其次,数据构建层面,Windows PE二进制文件的获取面临多重障碍:Visual Studio工具链依赖图形界面难以自动化;开源仓库许可混杂(如GPL与BSD协议冲突)导致合规分发困难;GitHub上大量项目因缺少正确配置或依赖缺失而构建失败(Windows构建成功率仅30%)。此外,现代大语言模型对数据量的需求呈指数级增长,而现有最大公开数据集BinaryCorp仅包含48k Linux二进制文件,远不能满足训练需求。Assemblage虽以89万Windows PE二进制文件缓解了数据饥荒,但其构建过程中仍面临SDK版本不匹配、解决方案配置无效等基础设施错误,且需持续应对GitHub仓库动态更新带来的复现性挑战。
常用场景
经典使用场景
在二进制分析领域,Assemblage数据集最经典的使用场景是作为大规模、高质量良性Windows PE二进制文件的来源,用于训练和评估基于机器学习的逆向工程、恶意软件检测和漏洞发现模型。由于长期以来缺乏公开可用的良性Windows PE语料库,现有研究多依赖于有限的Linux ELF二进制文件或昂贵的商业数据集。Assemblage通过自动化爬取和编译GitHub上的开源项目,提供了超过89万个Windows PE二进制文件,覆盖多种编译器版本、优化级别和架构配置,为现代深度学习模型提供了前所未有的数据规模和多样性。
实际应用
在实际应用中,Assemblage数据集可直接用于提升恶意软件检测系统的性能。由于Windows是恶意软件攻击的主要目标,安全厂商需要大量良性样本来训练分类器以区分恶意与正常程序。Assemblage提供的近90万个经过编译溯源标注的良性Windows PE二进制文件,克服了传统上依赖VirusTotal等付费服务或小型开源集合的局限。此外,该数据集还可支撑自动化逆向工程工具的开发,例如通过其丰富的函数级标注信息训练编译器版本识别模型,帮助安全分析师快速了解未知二进制文件的生成背景,从而加速漏洞分析与应急响应流程。
衍生相关工作
Assemblage数据集的发布催生了一系列重要的衍生研究工作。首先,它被用于复现和评估PassTell编译器溯源模型,实验表明该模型在Windows PE数据上的准确率显著低于Linux数据,揭示了现有方法对Windows平台的适用性缺陷。其次,基于Assemblage构建的1.78百万函数级数据集,研究者检验了图神经网络在二进制函数相似性检测中的跨平台泛化能力,发现Linux训练模型在Windows测试集上的AUC得分大幅下降。此外,Assemblage还支撑了jTrans等Transformer模型的微调实验,证明了大规模Windows数据对于提升现代二进制代码表示学习的关键价值,为后续开发跨平台二进制分析系统奠定了数据基础。
以上内容由遇见数据集搜集并总结生成


