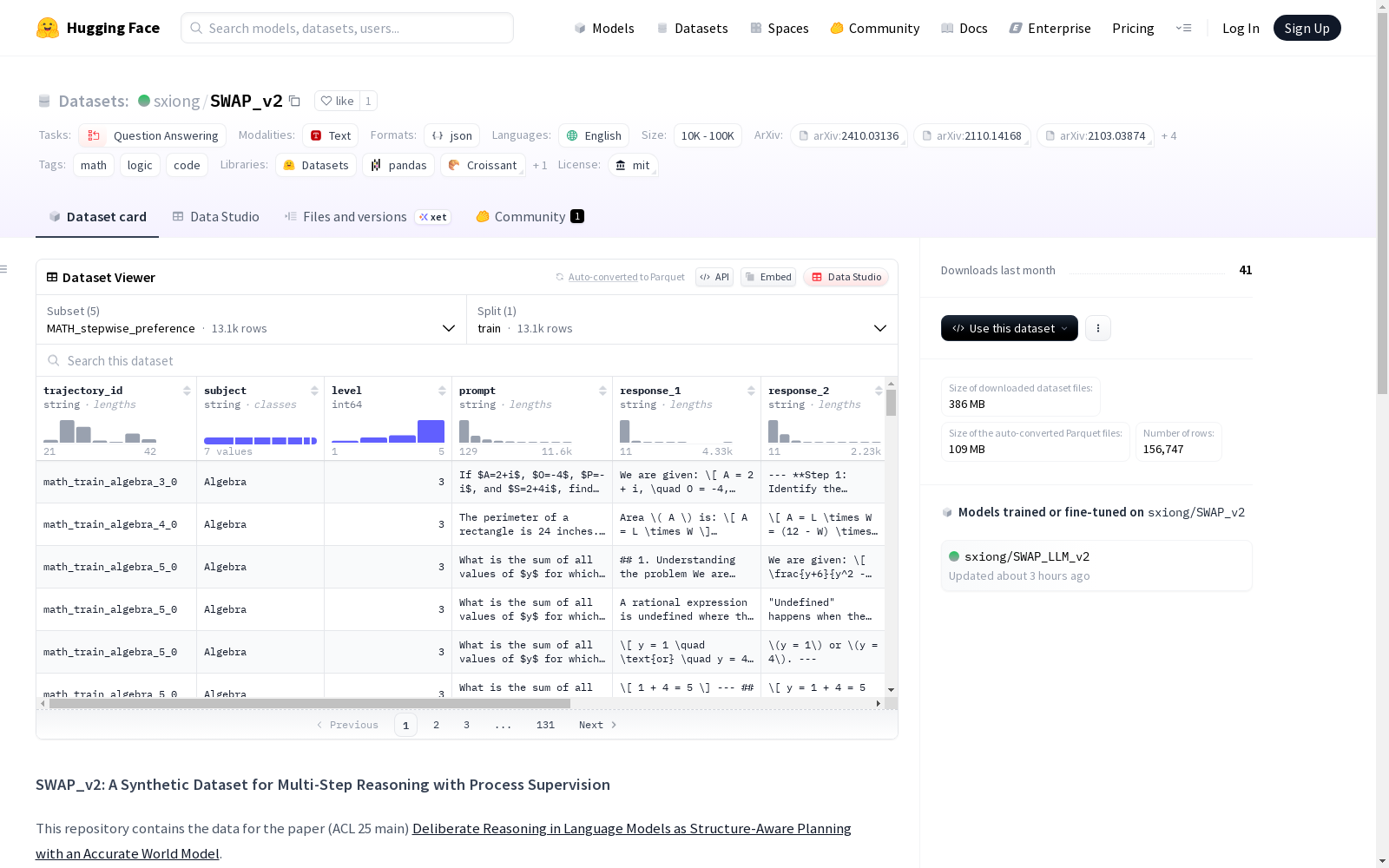
SWAP_v2
收藏SWAP_v2 数据集概述
基本信息
- 数据集名称: SWAP_v2
- 许可证: MIT
- 任务类别: 问答
- 语言: 英语
- 标签: 数学、逻辑、代码
数据集配置
- gsm8k_trajectory: 训练集路径 trajectory/gsm8k/train*
- MATH_trajectory: 训练集路径 trajectory/MATH/train*
- gsm8k_stepwise_preference: 训练集路径 stepwise_preference/gsm8k/train*
数据集描述
SWAP_v2 是一个用于多步推理过程监督的合成数据集,基于论文《Deliberate Reasoning in Language Models as Structure-Aware Planning with an Accurate World Model》构建。
数据生成
- 使用 DeepSeek-V3.2 在多个基准数据集上生成轨迹:
- gsm8k
- MATH
- FOLIO
- ReClor
- HumanEval
- MBPP
- 基于树搜索和语义等价比较自动获取过程监督
相关资源
- 代码仓库: https://github.com/xiongsiheng/SWAP
- 论文链接: https://arxiv.org/pdf/2410.03136
引用格式
bibtex @inproceedings{xiong-etal-2025-deliberate, title = "Deliberate Reasoning in Language Models as Structure-Aware Planning with an Accurate World Model", author = "Xiong, Siheng and Payani, Ali and Yang, Yuan and Fekri, Faramarz", booktitle = "Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)", month = jul, year = "2025", address = "Vienna, Austria", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/2025.acl-long.1540/", doi = "10.18653/v1/2025.acl-long.1540", pages = "31900--31931", ISBN = "979-8-89176-251-0" }