有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
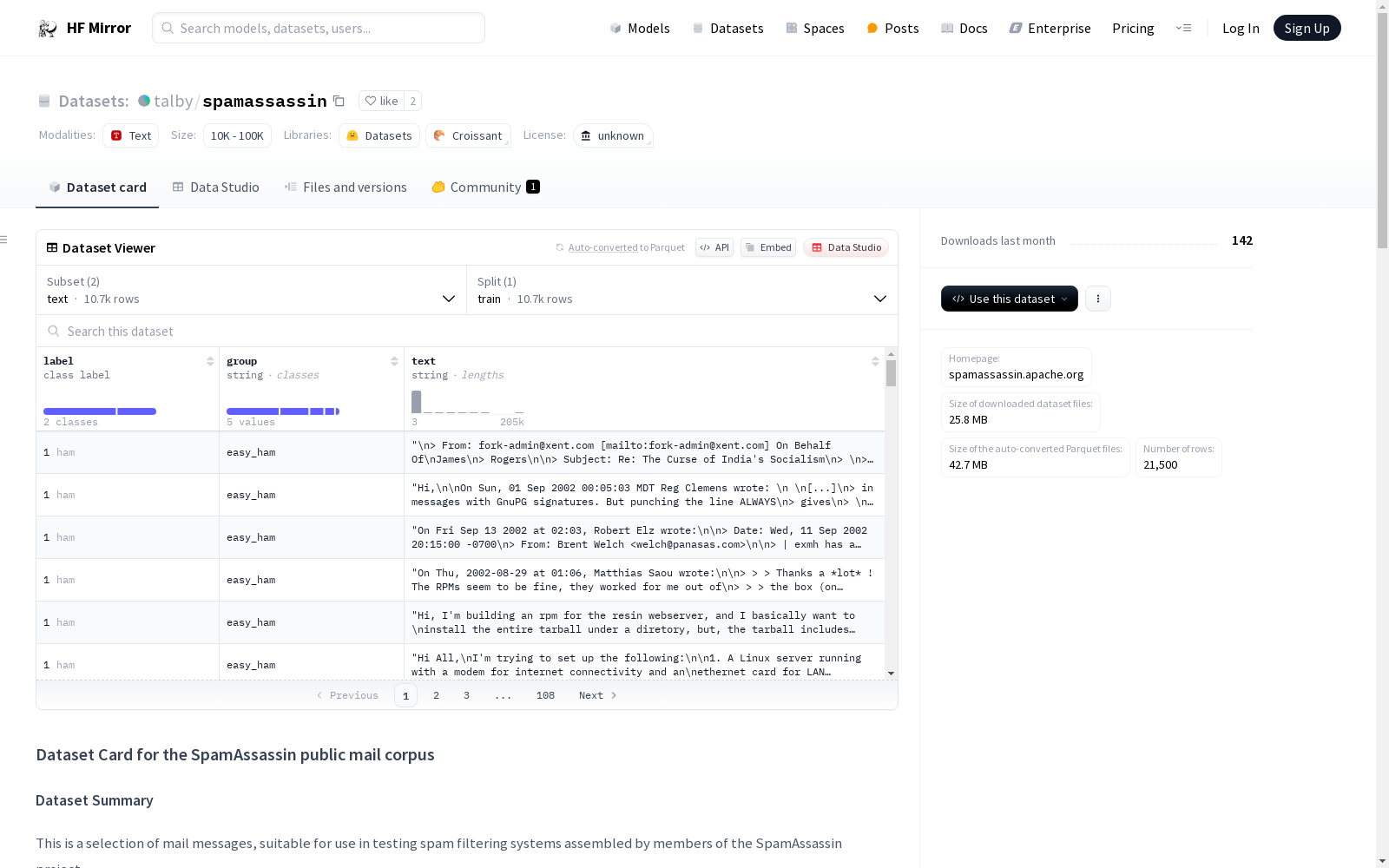
SpamAssassin公共邮件语料库
这是一个由SpamAssassin项目成员组装的邮件消息选择,适合用于测试垃圾邮件过滤系统。
text 配置将所有字符集标准化为utf8,并将MIME树转储为JSON列表的列表。unprocessed 配置不解析消息,保留完整的标题和内容为二进制格式。label: 标记为spam或hamgroup: 样本被SpamAssassin归类为{hard_ham, spam_2, spam, easy_ham, easy_ham_2}text: 消息正文的规范化文本raw: 消息的完整二进制标题和内容仅提供了_train_分割。
希望此数据集能帮助验证现代NLP工具是否能解决旧的NLP问题。
上游语料库描述详细说明了收集方法。恢复文本正文的工作主要使用email.parser和ftfy完成。
未知
中国区域交通网络数据集
该数据集包含中国各区域的交通网络信息,包括道路、铁路、航空和水路等多种交通方式的网络结构和连接关系。数据集详细记录了各交通节点的位置、交通线路的类型、长度、容量以及相关的交通流量信息。
data.stats.gov.cn 收录
WorldClim
WorldClim是一个全球气候数据集,提供了全球范围内的气候数据,包括温度、降水、生物气候变量等。数据集的分辨率从30秒到10分钟不等,适用于各种尺度的气候分析和建模。
www.worldclim.org 收录
中国逐日格点降水数据集V2(1960–2024,0.1°)
CHM_PRE V2数据集是一套高精度的中国大陆逐日格点降水数据集。该数据集基于1960年至今共3476个观测站的长期日降水观测数据,并纳入11个降水相关变量,用于表征降水的相关性。数据集采用改进的反距离加权方法,并结合基于机器学习的LGBM算法构建。CHM_PRE V2与现有的格点降水数据集(包括CHM_PRE V1、GSMaP、IMERG、PERSIANN-CDR和GLDAS)表现出良好的时空一致性。数据集基于63,397个高密度自动雨量站2015–2019年的观测数据进行验证,发现该数据集显著提高了降水测量精度,降低了降水事件的高估,为水文建模和气候评估提供了可靠的基础。CHM_PRE V2 数据集提供分辨率为0.1°的逐日降水数据,覆盖整个中国大陆(18°N–54°N,72°E–136°E)。该数据集涵盖1960–2024年,并将每年持续更新。日值数据以NetCDF格式提供,为了方便用户,我们还提供NetCDF和GeoTIFF格式的年度和月度总降水数据。
国家青藏高原科学数据中心 收录
MMAUD
MMAUD是一个综合的多模态反无人机数据集,用于检测、分类、跟踪和轨迹估计紧凑型商用无人机威胁。数据集包含多种传感器数据,如3D激光雷达、同步相机、毫米波雷达和音频阵列节点。
github 收录
LIDC-IDRI
LIDC-IDRI 数据集包含来自四位经验丰富的胸部放射科医师的病变注释。 LIDC-IDRI 包含来自 1010 名肺部患者的 1018 份低剂量肺部 CT。
OpenDataLab 收录