talby/spamassassin
收藏Hugging Face2023-07-11 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/talby/spamassassin
下载链接
链接失效反馈官方服务:
资源简介:
---
license: unknown
---
# Dataset Card for the SpamAssassin public mail corpus
## Dataset Description
- **Homepage:** https://spamassassin.apache.org/old/publiccorpus/readme.html
### Dataset Summary
This is a selection of mail messages, suitable for use in testing spam filtering systems assembled by members of the SpamAssassin project.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
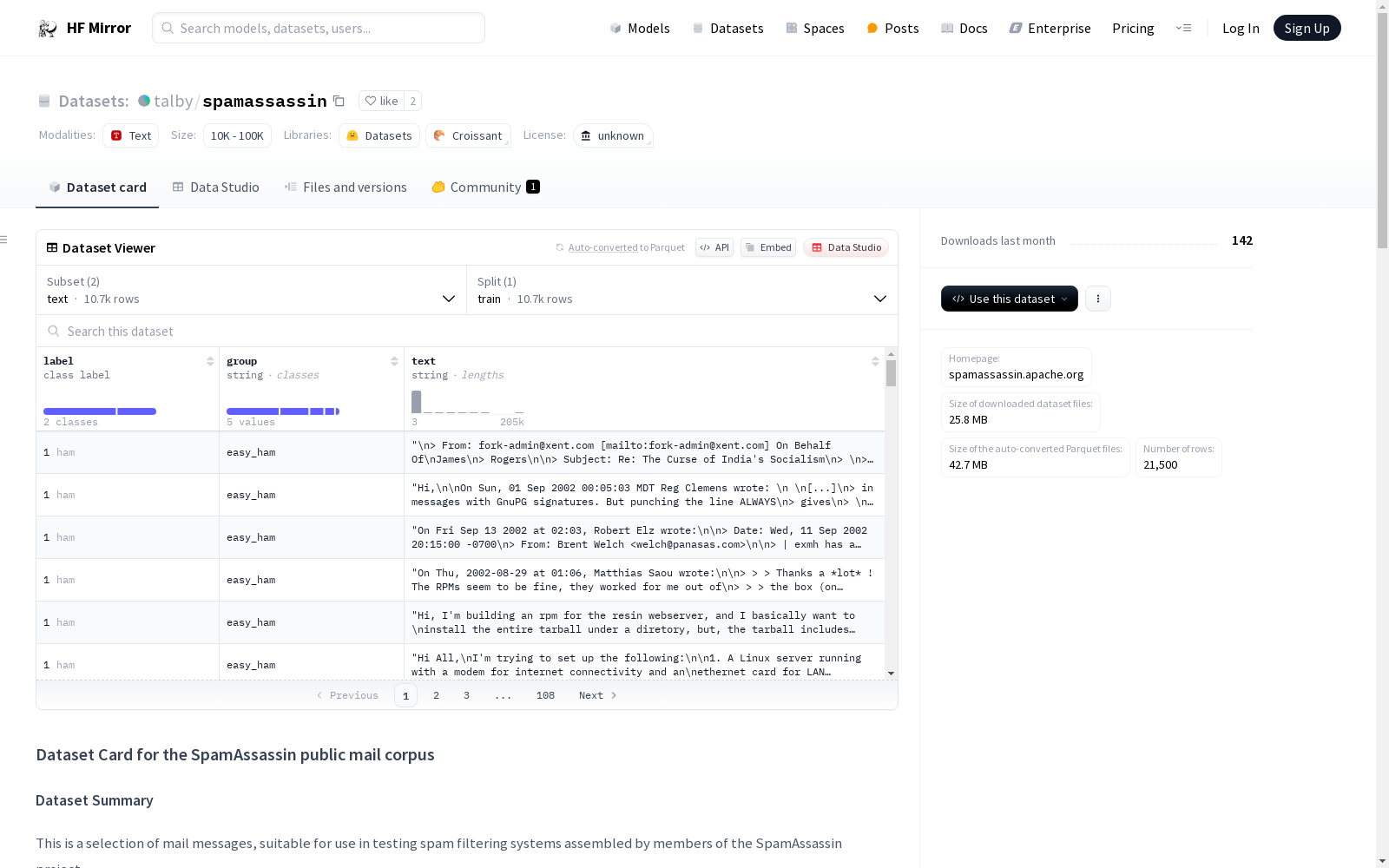
### Data Instances
- The `text` config normalizes all character sets to utf8 and dumps the
MIME tree as a JSON list of lists.
- The `unprocessed` config does not parse messages at all, leaving the
full headers and content as binary.
### Data Fields
- `label`: `spam` or `ham`
- `group`: SpamAssassin has grouped these samples into categories
{'hard_ham', 'spam_2', 'spam', 'easy_ham', 'easy_ham_2'}
- `text`: normalized text of the message bodies
- `raw`: full binary headers and contents of messages
### Data Splits
Only a _train_ split has been provided.
## Dataset Creation
### Curation Rationale
It is hoped this dataset can help verify that modern NLP tools can solve
old NLP problems.
### Source Data
#### Initial Data Collection and Normalization
[The upstream corpus description](https://spamassassin.apache.org/old/publiccorpus/readme.html)
goes into detail on collection methods. The work here to recover text bodies
is largely done with [email.parser](https://docs.python.org/3/library/email.parser.html)
and [ftfy](https://pypi.org/project/ftfy/).
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed]
---
license: 未知
---
# SpamAssassin公开邮件语料库数据集卡片
## 数据集说明
- **Homepage:** https://spamassassin.apache.org/old/publiccorpus/readme.html
### 数据集概述
本数据集为精选邮件样本集,适用于测试由SpamAssassin项目成员搭建的垃圾邮件过滤系统。
### 支持任务与排行榜
[需补充更多信息]
### 涉及语言
[需补充更多信息]
## 数据集结构
### 数据实例
- `text` 配置项会将所有字符集统一规范化为UTF-8,并将MIME树形结构导出为JSON嵌套列表格式。
- `unprocessed` 配置项则不会对邮件进行任何解析,保留完整的邮件头与内容为二进制格式。
### 数据字段
- `label`:取值为`spam`(垃圾邮件)或`ham`(正常邮件)
- `group`:SpamAssassin将样本划分为以下类别:{'hard_ham', 'spam_2', 'spam', 'easy_ham', 'easy_ham_2'}
- `text`:邮件正文的规范化文本
- `raw`:邮件完整头信息与内容的二进制数据
### 数据划分
仅提供了训练集(_train_)划分。
## 数据集构建
### 筛选初衷
本数据集旨在助力验证现代自然语言处理(Natural Language Processing,以下简称NLP)工具能否解决经典自然语言处理问题。
### 源数据
#### 初始数据收集与规范化
[上游语料库说明文档](https://spamassassin.apache.org/old/publiccorpus/readme.html) 详细阐述了数据收集方法。本数据集的正文文本恢复工作主要借助[email.parser](https://docs.python.org/3/library/email.parser.html)与[ftfy](https://pypi.org/project/ftfy/)完成。
#### 源文本创作者身份?
[需补充更多信息]
### 标注信息
#### 标注流程
[需补充更多信息]
#### 标注人员身份?
[需补充更多信息]
### 个人与敏感信息
[需补充更多信息]
## 数据使用注意事项
### 数据集社会影响
[需补充更多信息]
### 偏见相关讨论
[需补充更多信息]
### 其他已知局限性
[需补充更多信息]
## 补充信息
### 数据集整理者
[需补充更多信息]
### 许可证信息
[需补充更多信息]
### 引用信息
[需补充更多信息]
### 贡献信息
[需补充更多信息]
提供机构:
talby
原始信息汇总
数据集概述
数据集名称
SpamAssassin公共邮件语料库
数据集描述
这是一个由SpamAssassin项目成员组装的邮件消息选择,适合用于测试垃圾邮件过滤系统。
数据集结构
数据实例
text配置将所有字符集标准化为utf8,并将MIME树转储为JSON列表的列表。unprocessed配置不解析消息,保留完整的标题和内容为二进制格式。
数据字段
label: 标记为spam或hamgroup: 样本被SpamAssassin归类为{hard_ham, spam_2, spam, easy_ham, easy_ham_2}text: 消息正文的规范化文本raw: 消息的完整二进制标题和内容
数据分割
仅提供了_train_分割。
数据集创建
精选理由
希望此数据集能帮助验证现代NLP工具是否能解决旧的NLP问题。
源数据
初始数据收集和规范化
上游语料库描述详细说明了收集方法。恢复文本正文的工作主要使用email.parser和ftfy完成。
许可证
未知
搜集汇总
数据集介绍
构建方式
talby/spamassassin数据集的构建,旨在通过采集并整理电子邮件消息,为垃圾邮件过滤系统的测试提供支持。该数据集的构建主要依赖于邮件解析工具email.parser和文本修复库ftfy,以utf8编码进行字符集标准化,并对MIME树进行JSON格式化处理,同时保留了原始的 headers 和内容作为二进制形式。数据集分为训练集,并标注了邮件为垃圾邮件('spam')或正常邮件('ham'),以及根据SpamAssassin项目分类的组别信息。
使用方法
在使用talby/spamassassin数据集时,用户可以根据实际需求选择标准化文本或原始二进制格式的数据。数据集目前仅提供训练集,用户需自行进行数据划分以满足不同的模型训练需求。在使用过程中,建议用户关注数据集的潜在偏见和局限性,并在模型训练和应用中采取相应的策略来缓解这些问题。
背景与挑战
背景概述
talby/spamassassin数据集,诞生于 SpamAssassin 项目,旨在为垃圾邮件过滤系统提供测试邮件集合。该数据集的构建,源于对现代自然语言处理工具解决传统自然语言处理问题的验证需求。自推出以来,该数据集已成为研究邮件分类、垃圾邮件识别等领域的重要资源,对相关领域的研究与实践产生了深远影响。
当前挑战
该数据集在研究领域面临的挑战主要包括:如何利用现代NLP工具准确识别和处理垃圾邮件这一传统问题;在构建过程中,数据集的收集、清洗和标准化工作也颇具挑战,尤其是邮件内容的解析和字符集的统一。此外,数据集在处理个人敏感信息、避免偏见等方面亦存在一定的局限性,需要在实际应用中加以考量。
常用场景
经典使用场景
在自然语言处理领域,特别是在邮件分类任务中,talby/spamassassin数据集被广泛采用。该数据集包含经过筛选的邮件消息,用于测试垃圾邮件过滤系统的有效性。其经典的运用场景在于构建和评估基于文本内容的垃圾邮件检测模型,从而对邮件进行自动分类,区分正常邮件与垃圾邮件。
解决学术问题
该数据集解决了学术研究中如何准确评估垃圾邮件过滤算法性能的问题。通过提供标注好的邮件样本,研究者可以运用这一数据集对各种垃圾邮件检测模型进行训练和测试,进而提高模型的准确率和可靠性,推动邮件分类技术的发展。
实际应用
在现实世界中,talby/spamassassin数据集的应用场景广泛,包括但不限于邮件服务提供商的垃圾邮件过滤系统、企业级邮件安全解决方案以及个人邮件客户端的垃圾邮件检测功能。它帮助提升邮件处理系统的智能化水平,增强用户体验。
数据集最近研究
最新研究方向
在自然语言处理与机器学习领域,垃圾邮件识别作为一项经典任务,始终受到研究者的关注。talby/spamassassin数据集,作为测试垃圾邮件过滤系统的重要资源,近期研究聚焦于深度学习模型的优化与应用。学者们通过该数据集探索模型在处理邮件文本特征提取、分类效果以及模型泛化能力方面的表现,旨在提升垃圾邮件检测的准确性和效率。这一研究方向的深入,不仅有助于完善邮件安全系统,也进一步推动了文本分类技术的进步。
以上内容由遇见数据集搜集并总结生成


