Nemotron-Cascade-SFT-Stage-1
收藏Hugging Face2025-12-16 更新2025-12-18 收录
下载链接:
https://huggingface.co/datasets/nvidia/Nemotron-Cascade-SFT-Stage-1
下载链接
链接失效反馈官方服务:
资源简介:
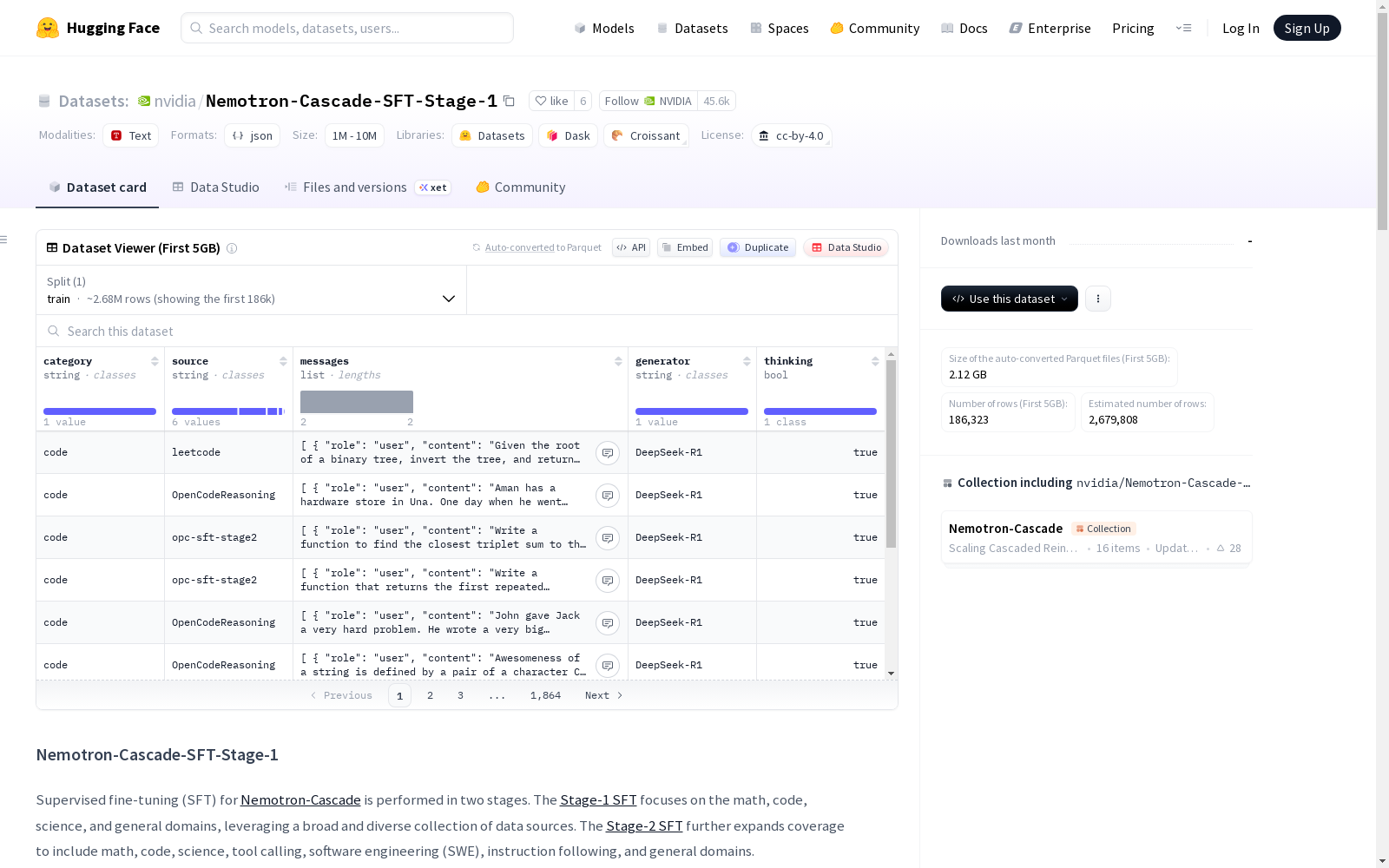
Nemotron-Cascade-SFT-Stage-1数据集是用于Nemotron-Cascade模型有监督微调(SFT)的第一阶段数据集,主要涵盖数学、代码、科学和通用领域。数据集利用了多种数据源,包括OpenMathReasoning、NuminaMath-CoT、OpenCodeReasoning、MagicoderEvolInstruct等。所有回答均由DeepSeek-R1生成,并包含明确的推理过程。数据集还提供了详细的统计信息,展示了各领域的问题数量和样本数量。
提供机构:
NVIDIA
创建时间:
2025-12-16
原始信息汇总
Nemotron-Cascade-SFT-Stage-1 数据集概述
数据集简介
本数据集是用于NVIDIA Nemotron-Cascade模型的两阶段监督微调(SFT)中的第一阶段数据集。该阶段主要聚焦于数学、代码、科学和通用领域,利用了广泛且多样化的数据源集合。所有回答均由DeepSeek-R1生成,并包含显式的推理(思考)过程。
领域与数据来源
数学领域
- OpenMathReasoning: 包含270,534个问题,2,147,570个样本。
- NuminaMath-CoT: 包含78,880个问题,521,171个样本。
代码领域
- OpenCodeReasoning: 包含35,374个问题,763,495个样本。
- MagicoderEvolInstruct: 包含27,625个问题,27,625个样本。
- opc-sft-stage2: 包含79,938个问题,323,163个样本。
- leetcode: 包含5,571个问题,126,878个样本。
- TACO: 包含16,726个问题,56,694个样本。
- apps: 包含159个问题,3,736个样本。
科学领域
- s1k: 包含826个问题,1,904个样本。
- synthetic: 包含3,653个问题,80,046个样本。
- Nemotron-Post-Training-Dataset-v1-stem: 包含62,903个问题,213,232个样本。
通用领域
- mmlu auxiliary train: 包含94,039个问题,103,973个样本。
- SlimOrca: 包含294,412个问题,294,412个样本。
- UltraInteract: 包含28,916个问题,28,916个样本。
- GPTeacher: 包含17,192个问题,17,192个样本。
- ShareGPT_Vicuna_unfiltered: 包含133,658个问题,140,870个样本。
- Magpie-Pro-300K-Filtered-H4: 包含269,869个问题,532,884个样本。
- Nemotron-Post-Training-Dataset-v1: 包含44,073个问题,52,857个样本。
许可信息
本数据集采用知识共享署名 4.0 国际许可协议(CC BY 4.0)进行许可。许可协议全文可在 https://creativecommons.org/licenses/by/4.0/legalcode 获取。
发布日期
2025年12月15日
引用格式
@article{Nemotron_Cascade_Scaling_Cascaded_Reinforcement_Learning, title={Nemotron-Cascade: Scaling Cascaded Reinforcement Learning for General-Purpose Reasoning Models}, author={Wang, Boxin and Lee, Chankyu and Lee, Nayeon and Lin, Sheng-Chieh and Dai, Wenliang and Chen, Yang and Chen, Yangyi and Yang, Zhuolin and Liu, Zihan and Shoeybi, Mohammad and Catanzaro, Bryan and Ping, Wei}, year={2025} }
搜集汇总
数据集介绍
构建方式
在大型语言模型监督微调领域,Nemotron-Cascade-SFT-Stage-1数据集的构建体现了多源异构数据的系统性整合策略。该数据集聚焦于数学、代码、科学与通用四大核心领域,通过精心遴选并融合了多个权威开源数据集作为问题来源。具体而言,数学部分整合了OpenMathReasoning与NuminaMath-CoT的题目;代码部分汇集了来自OpenCodeReasoning、MagicoderEvolInstruct及多个编程竞赛数据集的问题;科学领域则基于Nemotron-Post-Training-Dataset-v1与S1K构建;通用领域广泛吸纳了MMLU、ShareGPT、SlimOrca等多样化指令数据。所有问题的答案均由DeepSeek-R1模型生成,并明确包含了推理思考过程,从而形成了结构清晰、来源可靠的大规模指令微调语料。
使用方法
该数据集专为大型语言模型的监督微调阶段设计,尤其适用于提升模型在特定专业领域的指令遵循与复杂推理能力。研究人员或开发者可直接加载该数据集,用于对预训练基础模型进行有监督的微调训练。在实际使用中,建议将数据按领域划分进行混合或分阶段训练,以均衡各领域知识的吸收。由于数据已包含清晰的指令输入与带有推理过程的输出,训练目标可设定为让模型学会在给定问题上生成类似的、步骤详尽的答案。使用者需遵循CC BY 4.0许可协议,并可结合后续的Stage-2数据集,构建从广泛能力到专项深化的完整微调流程。
背景与挑战
背景概述
在大型语言模型迈向通用人工智能的演进历程中,监督微调技术扮演着至关重要的角色,旨在提升模型在特定领域的专业能力与指令遵循精度。Nemotron-Cascade-SFT-Stage-1数据集由英伟达公司于2025年12月发布,作为其Nemotron-Cascade模型两阶段监督微调流程的初始环节,聚焦于数学、编程、科学及通用领域。该数据集汇聚了OpenMathReasoning、OpenCodeReasoning等众多高质量开源数据源,并利用DeepSeek-R1模型生成包含显式推理过程的响应,其核心研究问题在于通过大规模、多样化的领域数据对基础模型进行精细化对齐,以增强模型的复杂问题解决与跨领域泛化能力,为后续强化学习阶段奠定坚实基础,对推动通用推理模型的发展具有显著影响力。
当前挑战
该数据集旨在应对通用语言模型在数学推导、代码生成及科学推理等专业领域进行精细化能力对齐时所面临的挑战,其核心在于如何确保模型输出的逻辑严谨性、事实准确性以及跨领域知识的有效融合。在构建过程中,研究团队需整合来自多个异构数据源的庞大数据,并维持数据格式、质量与标注标准的一致性;同时,利用辅助模型生成响应时,需精心设计提示策略以诱导出高质量、可解释的思维链,并有效过滤可能存在的噪声或错误内容,这对数据清洗、去重与验证流程提出了极高的技术要求。
常用场景
经典使用场景
在大型语言模型监督微调的研究领域,Nemotron-Cascade-SFT-Stage-1数据集扮演着关键角色,其经典使用场景集中于模型在数学、代码、科学及通用领域的指令遵循与推理能力培养。该数据集通过整合OpenMathReasoning、OpenCodeReasoning等高质量来源,构建了覆盖广泛知识范畴的监督信号,为模型提供了从基础概念到复杂问题求解的渐进式学习路径。研究人员利用此数据集对预训练模型进行初步对齐,旨在提升模型在特定任务上的响应准确性与逻辑连贯性,为后续的强化学习阶段奠定坚实的性能基础。
解决学术问题
该数据集有效应对了通用大模型在专业领域知识泛化与推理能力不足的学术挑战。通过系统集成数学推导、代码生成、科学问答及通用对话等多模态数据,它为解决模型在复杂问题求解中的思维链缺失、指令理解偏差以及跨领域知识迁移困难等核心问题提供了标准化训练资源。其构建显著促进了模型推理透明化与可解释性的研究,为评估和提升人工智能系统的认知与逻辑能力设立了新的基准,推动了从通用对话到专业任务求解的技术演进。
实际应用
在实际应用层面,基于该数据集微调的模型能够服务于智能教育辅助、自动化代码开发、科研问题解答以及通用对话系统等多个场景。例如,在编程教育中,模型可提供带推理步骤的代码示例与错误分析;在科学研究中,它能协助研究人员梳理科学概念与实验逻辑。这些应用不仅提升了人机交互的智能化水平,也为企业级解决方案如智能客服、内容生成与数据分析工具注入了更强的专业性与可靠性,加速了人工智能技术向垂直行业的深度融合与落地。
数据集最近研究
最新研究方向
在大型语言模型监督微调领域,Nemotron-Cascade-SFT-Stage-1数据集代表了当前多领域知识整合的前沿探索。该数据集通过融合数学、代码、科学及通用领域的多样化高质量数据源,旨在构建具备深度推理能力的通用模型。其核心研究方向聚焦于利用DeepSeek-R1生成的显式思维链响应,推动模型在复杂问题解决中的可解释性与逻辑连贯性。这一数据构建范式正响应了当前人工智能研究对模型透明化与可靠性的迫切需求,尤其在需要严格逻辑验证的STEM领域,为后续的指令遵循、工具调用等高级能力微调奠定了坚实的知识基础。
以上内容由遇见数据集搜集并总结生成


