linfeng302/RacketVision
收藏Hugging Face2026-04-11 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/linfeng302/RacketVision
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
language:
- en
pretty_name: RacketVision Dataset
size_categories:
- 10K<n<100K
task_categories:
- object-detection
- video-classification
tags:
- sports-analytics
- computer-vision
- object-tracking
- trajectory-prediction
- ball-tracking
- racket-pose-estimation
- badminton
- table-tennis
- tennis
- racket-sports
---
# RacketVision Dataset
[](https://arxiv.org/abs/2511.17045)
[](https://aaai.org/)
[](https://github.com/OrcustD/RacketVision/)
[](https://huggingface.co/datasets/linfeng302/RacketVision)
[](https://huggingface.co/linfeng302/RacketVision-Models)
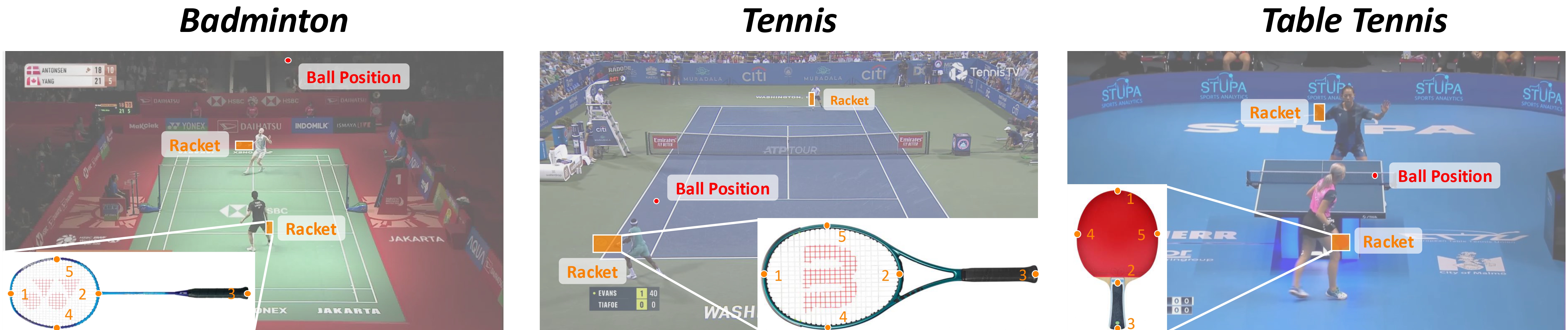
**RacketVision** is a large-scale, multi-sport dataset and benchmark for advancing computer vision in sports analytics, covering **badminton**, **table tennis**, and **tennis**. It is the first dataset to provide large-scale, fine-grained annotations for racket pose alongside traditional ball positions, enabling research into complex human-object interactions. The benchmark tackles three interconnected tasks: fine-grained **ball tracking**, articulated **racket pose estimation**, and predictive ball **trajectory forecasting**.
## Using this Hub repository
This dataset is distributed as **static files** (videos, CSV, JSON, PKL). Download it with the Hugging Face CLI, then follow the [project README](https://github.com/OrcustD/RacketVision/blob/main/README.md) for environment setup and training:
```bash
# Official code layout (clone https://github.com/OrcustD/RacketVision ): from repo root
hf download linfeng302/RacketVision --repo-type dataset --local-dir source/data
# Stand-alone data folder only (you must point module configs or --data_root to this directory)
hf download linfeng302/RacketVision --repo-type dataset --local-dir data
```
The in-browser Dataset Viewer may not fully load all assets: COCO detection and pose JSON files use different annotation schemas, so they are not merged into a single `datasets`-style table. Use the files on disk as documented below.
## Directory Layout
```
data/
├── annotations/
│ └── dataset_info.json # Global dataset metadata (clip list, splits)
│
├── info/ # COCO-format annotations for RacketPose
│ ├── train_det_coco.json # Detection: bbox annotations (train split)
│ ├── val_det_coco.json
│ ├── test_det_coco.json
│ ├── train_pose_coco.json # Pose: keypoint annotations (train split)
│ ├── val_pose_coco.json
│ └── test_pose_coco.json
│
├── <sport>/ # badminton / tabletennis / tennis
│ ├── videos/
│ │ └── <match>_<rally>.mp4 # Raw video clips
│ ├── all/
│ │ └── <match>/
│ │ ├── csv/<rally>_ball.csv # Ball ground truth annotations
│ │ └── racket/<rally>/*.json # Racket ground truth annotations
│ ├── interp_ball/ # Interpolated ball trajectories (for rebuilding TrajPred data)
│ ├── merged_racket/ # Merged racket predictions (for rebuilding TrajPred data)
│ └── info/
│ ├── metainfo.json # Sport-specific metadata
│ ├── train.json # [[match_id, rally_id], ...] for training
│ ├── val.json # Validation split
│ └── test.json # Test split
│
└── data_traj/ # Pre-built trajectory prediction datasets
├── ball_racket_<sport>_h20_f5.pkl # Short-horizon: 20 history → 5 future
└── ball_racket_<sport>_h80_f20.pkl # Long-horizon: 80 history → 20 future
```
**Local preprocessing (required for BallTrack):** after download, generate per-match `frame/<rally>/` (JPG frames) and `median.npz` from the videos using `DataPreprocess/extract_frames.py` and `DataPreprocess/create_median.py`. These are omitted from the Hub release to save space; see the [project README](https://github.com/OrcustD/RacketVision/blob/main/README.md).
## Data Formats
### Ball Annotations (`csv/<rally>_ball.csv`)
| Column | Type | Description |
|--------|------|-------------|
| Frame | int | 0-indexed frame number |
| X | int | Ball center X in pixels (1920×1080) |
| Y | int | Ball center Y in pixels |
| Visibility | int | 1 = visible, 0 = not visible |
### Racket Annotations (`racket/<rally>/<frame_id>.json`)
Per-frame JSON with a list of racket instances, each containing:
```json
{
"category": "badminton_racket",
"bbox_xywh": [x, y, w, h],
"keypoints": [[x1, y1, vis], [x2, y2, vis], ...]
}
```
**5 keypoints** are defined: `top`, `bottom`, `handle`, `left`, `right`.
### COCO Annotations (`info/*_coco.json`)
Standard COCO format used by RacketPose for training/evaluation:
- **Detection** (`*_det_coco.json`): 3 categories — `badminton_racket`, `tabletennis_racket`, `tennis_racket`.
- **Pose** (`*_pose_coco.json`): 1 category (`racket`) with 5 keypoints.
### Trajectory PKL (`data_traj/*.pkl`)
Pickle files containing pre-processed sliding-window samples. Each PKL has:
```python
{
'train_samples': [...], # List of sample dicts
'test_samples': [...],
'train_dataset': ..., # Legacy Dataset objects
'test_dataset': ...,
'metadata': {
'history_len': 80,
'future_len': 20,
'sports': ['badminton'],
'total_samples': N,
'train_size': ...,
'test_size': ...
}
}
```
Each sample dict:
```python
{
'history': np.array(shape=(H, 2)), # Normalised [X, Y] in [0, 1]
'future': np.array(shape=(F, 2)),
'history_rkt': np.array(shape=(H, 10)), # 5 keypoints × 2 coords, normalised
'future_rkt': np.array(shape=(F, 10)),
'sport': str,
'match': str,
'sequence': str,
'start_frame': int
}
```
**Normalisation**: Ball coordinates are divided by (1920, 1080). Racket keypoints are divided by the same values.
### Split Files (`<sport>/info/train.json`)
JSON list of `[match_id, rally_id]` pairs:
```json
[["match1", "000"], ["match1", "001"], ...]
```
## Generating Data from Scratch
If you have the raw videos, use `DataPreprocess/` scripts in the [code repository](https://github.com/OrcustD/RacketVision/) to prepare all intermediate files:
```bash
cd DataPreprocess
# 1. Extract video frames to JPG
python extract_frames.py --data_root ../data --sport badminton
# 2. Compute median background frame
python create_median.py --data_root ../data --sport badminton
# 3. Generate dataset_info.json and per-sport split files
python generate_dataset_info.py --data_root ../data
# 4. Generate COCO annotations for RacketPose
python generate_coco_annotations.py --data_root ../data
```
## Generating Trajectory Data
After running BallTrack and RacketPose inference, build `data_traj/` PKLs:
```bash
cd TrajPred
# Interpolate short gaps in ball predictions
python linear_interpolate_ball_traj.py --data_root ../data --sport badminton
# Merge racket predictions with ground truth annotations
python merge_gt_with_predictions.py --data_root ../data --sport badminton
# Build PKL dataset
python build_dataset.py --data_root ../data --sport badminton --history 80 --future 20
```
## Citation
If you find this work useful, please consider citing:
```bibtex
@inproceedings{dong2026racket,
title={Racket Vision: A Multiple Racket Sports Benchmark for Unified Ball and Racket Analysis},
author={Dong, Linfeng and Yang, Yuchen and Wu, Hao and Wang, Wei and Hou, Yuenan and Zhong, Zhihang and Sun, Xiao},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence (AAAI)},
year={2026}
}
```
提供机构:
linfeng302
搜集汇总
数据集介绍

构建方式
在体育分析计算机视觉领域,RacketVision数据集的构建体现了系统化与精细化的工程理念。该数据集通过采集羽毛球、乒乓球和网球三种球类运动的原始视频素材,并运用自动化与人工标注相结合的方式,生成多层次注释。具体流程包括从视频中提取帧序列,计算背景中值帧以辅助分析,并针对每个回合(rally)生成球体轨迹的CSV文件以及球拍姿态的JSON文件。此外,通过专门的预处理脚本,数据集进一步转换为标准的COCO格式检测与姿态标注,以及为轨迹预测任务预构建的序列化PKL文件,确保了数据在不同任务间的兼容性与可用性。
特点
RacketVision数据集的核心特点在于其规模性与任务导向的多模态设计。作为首个大规模、细粒度标注球拍姿态与球体位置的多运动数据集,它涵盖了羽毛球、乒乓球和网球三种运动,提供了超过一万个样本。数据集不仅包含传统的二维球体中心坐标及可见性标注,更创新性地定义了球拍的五个关键点(顶部、底部、手柄、左侧、右侧),支持对复杂人-物交互的深入研究。其注释体系同时支持目标检测、姿态估计与轨迹预测三大相互关联的任务,并通过归一化坐标与预分割的训练、验证、测试集,为模型开发与基准测试提供了坚实基础。
使用方法
为有效利用RacketVision数据集,研究者需遵循其模块化的使用路径。首先通过Hugging Face CLI工具下载静态数据文件至本地目录。对于球体追踪任务,需运行项目提供的预处理脚本,从视频中提取帧图像并生成背景中值帧。对于球拍姿态估计,可直接使用COCO格式的标注文件进行模型训练与评估。对于轨迹预测任务,则可直接加载预处理的PKL文件,其中包含了历史与未来序列的归一化球体与球拍关键点坐标。数据集目录结构清晰,按运动类型与任务组织,用户需根据具体任务指引配置数据路径,并参考原项目代码库完成环境搭建与实验复现。
背景与挑战
背景概述
在体育分析领域,计算机视觉技术正逐步从传统的人体姿态估计扩展到复杂的人-物交互理解。RacketVision数据集于2026年由林峰等研究人员提出,并作为AAAI会议的口头报告成果,标志着多球拍运动分析进入新阶段。该数据集首次大规模整合了羽毛球、乒乓球和网球三种球拍运动,不仅提供球体轨迹的精细标注,更创新性地引入了球拍姿态的关键点注释,旨在解决动态场景中球与球拍相互作用的统一建模问题。其构建推动了体育分析从单一目标检测向多任务协同预测的范式转变,为轨迹预测、姿态估计等任务提供了关键数据支撑。
当前挑战
RacketVision数据集致力于应对球拍运动中多目标协同分析的固有难题,其核心挑战在于如何准确捕捉高速运动下球与球拍的细微交互关系。具体而言,球体追踪需克服运动模糊、遮挡和快速形变等视觉干扰;球拍姿态估计则面临非刚性物体在高速挥动中的形变建模困难,以及多关键点精确定位的挑战。在数据构建层面,跨运动类别的标注一致性、大规模视频序列中时空信息的对齐,以及不同任务间数据格式的标准化集成,均为数据集构建带来显著复杂性。这些挑战共同指向了动态场景理解中细粒度建模与多模态融合的前沿问题。
常用场景
经典使用场景
在体育计算机视觉领域,RacketVision数据集为研究者提供了一个统一的基准平台,尤其适用于球拍类运动的精细化分析。该数据集通过整合羽毛球、乒乓球和网球三种运动的视频片段,并标注了球体轨迹与球拍姿态的细粒度信息,使得模型能够同时处理球体追踪、球拍姿态估计和轨迹预测这三个相互关联的任务。这种多任务协同的设计,使得该数据集成为评估和开发复杂人-物交互模型的理想选择,推动了体育分析中视觉理解能力的边界拓展。
衍生相关工作
围绕RacketVision数据集,已衍生出一系列经典的算法研究工作。其基准任务直接催生了针对球拍姿态估计(RacketPose)、球体跟踪(BallTrack)和轨迹预测(TrajPred)的专用模型。这些工作不仅提升了各自子任务的性能,更探索了多模态信息(如球轨迹与球拍姿态)的融合方法,为理解运动中的因果链提供了新视角。后续研究可能进一步探索基于此数据集的球员行为识别、比赛策略挖掘乃至跨运动技能的迁移学习,持续拓展体育人工智能的研究疆域。
数据集最近研究
最新研究方向
在体育分析计算机视觉领域,RacketVision数据集的出现标志着对球拍类运动精细化理解的重大突破。该数据集首次大规模融合了球体轨迹与球拍姿态的细粒度标注,为研究复杂人机交互提供了前所未有的数据基础。当前前沿研究聚焦于三个相互关联的核心任务:高精度球体跟踪、关节化球拍姿态估计以及基于时序的轨迹预测。这些研究方向正推动着智能体育分析向更深的语义理解迈进,例如通过球拍关键点捕捉运动员的击球动作细节,结合长短期历史数据进行轨迹预报,从而为运动员训练、战术制定及赛事转播的实时增强提供技术支持。随着AAAI 2026等顶级会议的关注,该数据集已成为探索多任务学习、跨模态融合及预测模型在动态场景中应用的典型范例,其影响已延伸至智能教练系统、自动化裁判辅助等实际应用场景。
以上内容由遇见数据集搜集并总结生成


