adam-narozniak/clothing
收藏Hugging Face2024-05-05 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/adam-narozniak/clothing
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
dataset_info:
features:
- name: image
dtype: image
- name: objects
sequence:
- name: bbox_id
dtype: int32
- name: category
dtype:
class_label:
names:
'0': shirt, blouse
'1': top, t-shirt, sweatshirt
'2': sweater
'3': cardigan
'4': jacket
'5': vest
'6': pants
'7': shorts
'8': skirt
'9': coat
'10': dress
'11': jumpsuit
'12': cape
'13': glasses
'14': hat
'15': headband, head covering, hair accessory
'16': tie
'17': glove
'18': watch
'19': belt
'20': leg warmer
'21': tights, stockings
'22': sock
'23': shoe
'24': bag, wallet
'25': scarf
'26': umbrella
'27': hood
'28': collar
'29': lapel
'30': epaulette
'31': sleeve
'32': pocket
'33': neckline
'34': buckle
'35': zipper
'36': applique
'37': bead
'38': bow
'39': flower
'40': fringe
'41': ribbon
'42': rivet
'43': ruffle
'44': sequin
'45': tassel
'46': earring
'47': ring
'48': bracelet
'49': necklace
'50': swimsuit
'51': underwear
'52': backpack
- name: bbox
sequence: int32
length: 4
- name: area
dtype: int32
- name: genre
dtype: string
- name: width
dtype: int64
- name: height
dtype: int64
splits:
- name: train
num_bytes: 566512000.628
num_examples: 3332
download_size: 566302792
dataset_size: 566512000.628
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
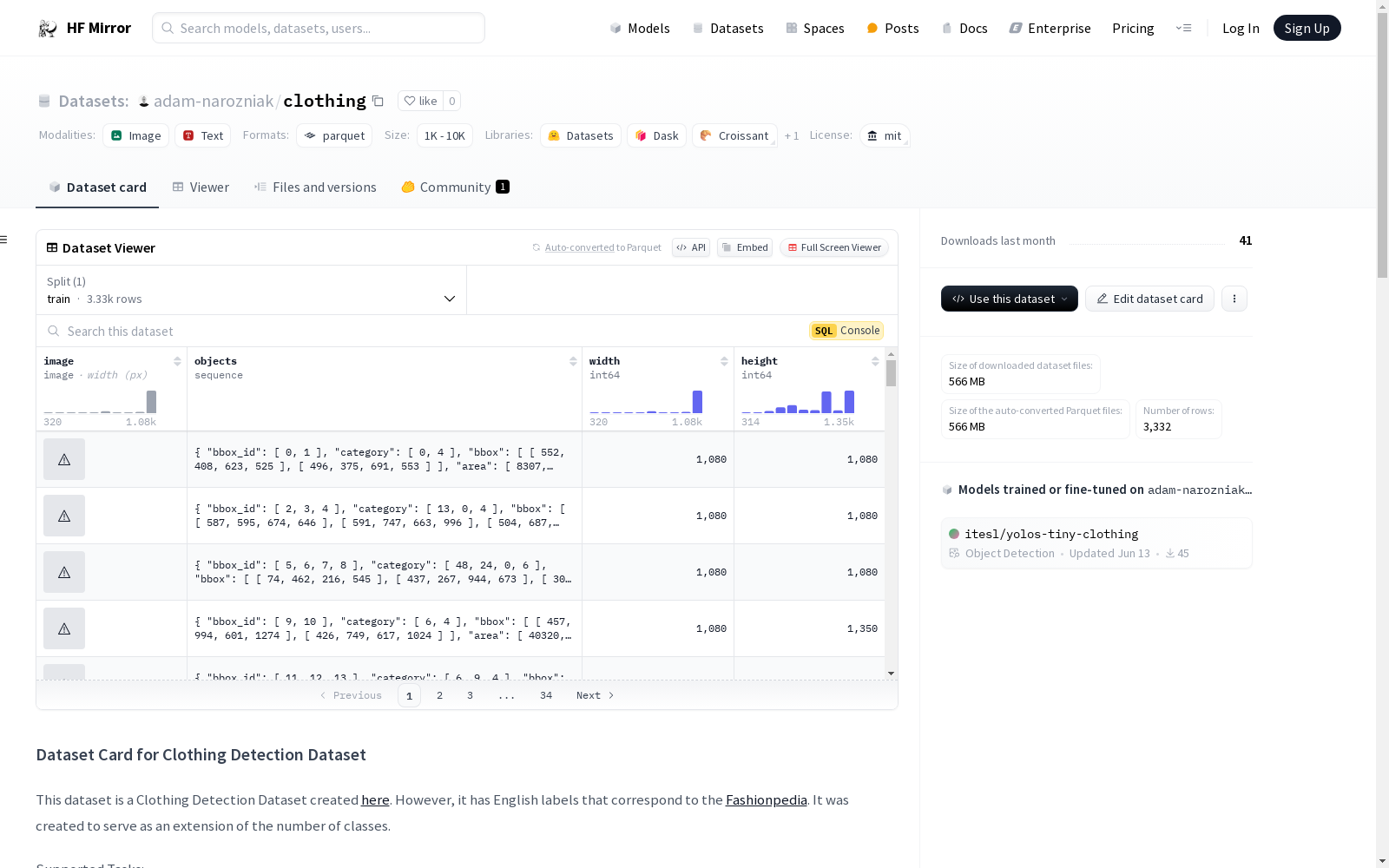
# Dataset Card for Clothing Detection Dataset
This dataset is a Clothing Detection Dataset created [here](https://github.com/seralexger/clothing-detection-dataset). However, it has English labels that correspond to the [Fashionpedia](https://huggingface.co/datasets/detection-datasets/fashionpedia). It was created to serve as an extension of the number of classes.
Supported Tasks:
* Object detection
* Image classification
## Languages
All of the annotations were translated and adjusted from Spanish to English (and match the Fashionpedia dataset annotations).
### Dataset Sources
- **Repository:** https://github.com/seralexger/clothing-detection-dataset
## Dataset Structure
```
DatasetDict({
train: Dataset({
features: ['image', 'objects', 'width', 'height'],
num_rows: 3332
})
})
```
## Dataset Instances
An example of the data for one image is:
```
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=1080x1080 at 0x13E257700>, 'objects': {'bbox_id': [0, 1], 'category': [0, 4], 'bbox': [[552, 408, 623, 525], [496, 375, 691, 553]], 'area': [8307, 34710], 'genre': ['man', 'man']}, 'width': 1080, 'height': 1080}
```
with the type of each field defined as:
```
{'image': Image(decode=True, id=None), 'objects': Sequence(feature={'bbox_id': Value(dtype='int32', id=None), 'category': ClassLabel(names=['shirt, blouse', 'top, t-shirt, sweatshirt', 'sweater', 'cardigan', 'jacket', 'vest', 'pants', 'shorts', 'skirt', 'coat', 'dress', 'jumpsuit', 'cape', 'glasses', 'hat', 'headband, head covering, hair accessory', 'tie', 'glove', 'watch', 'belt', 'leg warmer', 'tights, stockings', 'sock', 'shoe', 'bag, wallet', 'scarf', 'umbrella', 'hood', 'collar', 'lapel', 'epaulette', 'sleeve', 'pocket', 'neckline', 'buckle', 'zipper', 'applique', 'bead', 'bow', 'flower', 'fringe', 'ribbon', 'rivet', 'ruffle', 'sequin', 'tassel', 'earring', 'ring', 'bracelet', 'necklace', 'swimsuit', 'underwear', 'backpack'], id=None), 'bbox': Sequence(feature=Value(dtype='int32', id=None), length=4, id=None), 'area': Value(dtype='int32', id=None), 'genre': Value(dtype='string', id=None)}, length=-1, id=None), 'width': Value(dtype='int64', id=None), 'height': Value(dtype='int64', id=None)}
```
## Categories
The first 46 categories correspond to the original categories from the Fashionpedia.
## Translation
The original annotations were changed according to the following dictionary:
```
{
"camisas": "shirt, blouse",
"camisas ocultas debajo de la chaqueta": "shirt, blouse",
"chaquetas": "jacket",
"cazadoras": "jacket",
"pantalones": "pants",
"pantalones cortos": "shorts",
"falda": "skirt",
"abrigos": "coat",
"vestidos": "dress",
"monos": "jumpsuit",
"gafas de sol": "glasses",
"sombreros": "hat",
"corbatas": "tie",
"guantes y manopla": "glove",
"relojes": "watch",
"cinturones": "belt",
"calcetines y medias": "tights, stockings",
"zapatos": "shoe",
"bolso": "bag, wallet",
"carteras monederos": "bag, wallet",
"bufandas": "scarf",
"pendientes": "earring",
"anillos": "ring",
"pulseras": "bracelet",
"collares": "necklace",
"trajes de baño": "swimsuit",
"ropa interior": "underwear",
"mochilas": "backpack",
"botas": "shoe"
}
```
---
许可证:MIT许可证
数据集信息:
特征:
- 名称:image(图像),数据类型:图像
- 名称:objects(目标对象序列),包含以下子特征:
- bbox_id(边界框ID):数据类型为int32
- category(类别标签):数据类型为ClassLabel(类别标签),其类别名称映射如下:
0: 衬衫、女式衬衫(shirt, blouse)
1: 上衣、T恤、运动衫(top, t-shirt, sweatshirt)
2: 毛衣(sweater)
3: 开襟羊毛衫(cardigan)
4: 夹克(jacket)
5: 背心(vest)
6: 长裤(pants)
7: 短裤(shorts)
8: 半身裙(skirt)
9: 外套(coat)
10: 连衣裙(dress)
11: 连体衣(jumpsuit)
12: 斗篷(cape)
13: 眼镜(glasses)
14: 帽子(hat)
15: 发带、头部遮盖物、发饰(headband, head covering, hair accessory)
16: 领带(tie)
17: 手套(glove)
18: 手表(watch)
19: 腰带(belt)
20: 腿套(leg warmer)
21: 紧身裤、长筒袜(tights, stockings)
22: 短袜(sock)
23: 鞋履(shoe)
24: 包袋、钱包(bag, wallet)
25: 围巾(scarf)
26: 雨伞(umbrella)
27: 兜帽(hood)
28: 衣领(collar)
29: 翻领(lapel)
30: 肩章(epaulette)
31: 衣袖(sleeve)
32: 口袋(pocket)
33: 领口(neckline)
34: 搭扣(buckle)
35: 拉链(zipper)
36: 贴花饰(applique)
37: 串珠(bead)
38: 蝴蝶结(bow)
39: 花朵装饰(flower)
40: 流苏饰边(fringe)
41: 饰带(ribbon)
42: 铆钉(rivet)
43: 褶边(ruffle)
44: 亮片(sequin)
45: 穗饰(tassel)
46: 耳环(earring)
47: 戒指(ring)
48: 手链(bracelet)
49: 项链(necklace)
50: 泳衣(swimsuit)
51: 内衣(underwear)
52: 背包(backpack)
- bbox(边界框):长度为4的int32序列,对应边界框坐标[x1, y1, x2, y2]
- area(目标区域面积):数据类型为int32
- genre(目标所属领域/人物类别):数据类型为字符串
- 名称:width(图像宽度):数据类型为int64
- 名称:height(图像高度):数据类型为int64
数据集拆分:
- 拆分名称:train(训练集),占用字节数:566512000.628,样本数量:3332
数据集下载大小:566302792字节,数据集总大小:566512000.628字节
配置信息:
- 配置名称:default(默认配置),数据文件:
- 拆分名称:train(训练集),对应路径:data/train-*
---
# 《服装检测数据集》数据集卡片
本数据集为服装检测数据集,创建于[https://github.com/seralexger/clothing-detection-dataset](https://github.com/seralexger/clothing-detection-dataset)。其标注标签采用英文体系,与[Fashionpedia](https://huggingface.co/datasets/detection-datasets/fashionpedia)数据集的标注规则一致,旨在拓展该数据集的类别数量。
支持任务:
* 目标检测
* 图像分类
## 语言说明
所有标注均从西班牙语翻译并调整为英语,且与Fashionpedia数据集的标注完全匹配。
## 数据集来源
- 代码仓库:https://github.com/seralexger/clothing-detection-dataset
## 数据集结构
DatasetDict({
train: Dataset({
features: ['image', 'objects', 'width', 'height'],
num_rows: 3332
})
})
翻译为:
数据集字典({
训练集: Dataset({
特征: ['图像(image)', '目标对象序列(objects)', '图像宽度(width)', '图像高度(height)'],
样本总数: 3332
})
})
## 数据集实例
单张图像的数据示例如下:
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=1080x1080 at 0x13E257700>, 'objects': {'bbox_id': [0, 1], 'category': [0, 4], 'bbox': [[552, 408, 623, 525], [496, 375, 691, 553]], 'area': [8307, 34710], 'genre': ['man', 'man']}, 'width': 1080, 'height': 1080}
优化后示例:
{'image(图像)': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=1080x1080 at 0x13E257700>, 'objects(目标对象)': {'bbox_id(边界框ID)': [0, 1], 'category(类别)': [0, 4], 'bbox(边界框)': [[552, 408, 623, 525], [496, 375, 691, 553]], 'area(区域面积)': [8307, 34710], 'genre(人物类别)': ['男性', '男性']}, 'width(图像宽度)': 1080, 'height(图像高度)': 1080}
各字段类型定义如下:
{'image': Image(decode=True, id=None), 'objects': Sequence(feature={'bbox_id': Value(dtype='int32', id=None), 'category': ClassLabel(names=['shirt, blouse', 'top, t-shirt, sweatshirt', 'sweater', 'cardigan', 'jacket', 'vest', 'pants', 'shorts', 'skirt', 'coat', 'dress', 'jumpsuit', 'cape', 'glasses', 'hat', 'headband, head covering, hair accessory', 'tie', 'glove', 'watch', 'belt', 'leg warmer', 'tights, stockings', 'sock', 'shoe', 'bag, wallet', 'scarf', 'umbrella', 'hood', 'collar', 'lapel', 'epaulette', 'sleeve', 'pocket', 'neckline', 'buckle', 'zipper', 'applique', 'bead', 'bow', 'flower', 'fringe', 'ribbon', 'rivet', 'ruffle', 'sequin', 'tassel', 'earring', 'ring', 'bracelet', 'necklace', 'swimsuit', 'underwear', 'backpack'], id=None), 'bbox': Sequence(feature=Value(dtype='int32', id=None), length=4, id=None), 'area': Value(dtype='int32', id=None), 'genre': Value(dtype='string', id=None)}, length=-1, id=None), 'width': Value(dtype='int64', id=None), 'height': Value(dtype='int64', id=None)}
优化后类型定义:
{'image(图像)': Image(解码=True, id=None), 'objects(目标对象序列)': Sequence(特征={'bbox_id(边界框ID)': Value(数据类型='int32', id=None), 'category(类别标签)': ClassLabel(类别名称=['衬衫、女式衬衫', '上衣、T恤、运动衫', '毛衣', '开襟羊毛衫', '夹克', '背心', '长裤', '短裤', '半身裙', '外套', '连衣裙', '连体衣', '斗篷', '眼镜', '帽子', '发带、头部遮盖物、发饰', '领带', '手套', '手表', '腰带', '腿套', '紧身裤、长筒袜', '短袜', '鞋履', '包袋、钱包', '围巾', '雨伞', '兜帽', '衣领', '翻领', '肩章', '衣袖', '口袋', '领口', '搭扣', '拉链', '贴花饰', '串珠', '蝴蝶结', '花朵装饰', '流苏饰边', '饰带', '铆钉', '褶边', '亮片', '穗饰', '耳环', '戒指', '手链', '项链', '泳衣', '内衣', '背包'], id=None), 'bbox(边界框)': Sequence(特征=Value(数据类型='int32', id=None), 长度=4, id=None), 'area(区域面积)': Value(数据类型='int32', id=None), 'genre(人物类别)': Value(数据类型='string', id=None)}, 长度=-1, id=None), 'width(图像宽度)': Value(数据类型='int64', id=None), 'height(图像高度)': Value(数据类型='int64', id=None)}
## 类别说明
前46个类别对应Fashionpedia数据集的原始类别。
## 标注转换规则
原始标注按照以下字典进行了翻译调整:
{
"camisas": "衬衫、女式衬衫",
"camisas ocultas debajo de la chaqueta": "衬衫、女式衬衫",
"chaquetas": "夹克",
"cazadoras": "夹克",
"pantalones": "长裤",
"pantalones cortos": "短裤",
"falda": "半身裙",
"abrigos": "外套",
"vestidos": "连衣裙",
"monos": "连体衣",
"gafas de sol": "眼镜",
"sombreros": "帽子",
"corbatas": "领带",
"guantes y manopla": "手套",
"relojes": "手表",
"cinturones": "腰带",
"calcetines y medias": "紧身裤、长筒袜",
"zapatos": "鞋履",
"bolso": "包袋、钱包",
"carteras monederos": "包袋、钱包",
"bufandas": "围巾",
"pendientes": "耳环",
"anillos": "戒指",
"pulseras": "手链",
"collares": "项链",
"trajes de baño": "泳衣",
"ropa interior": "内衣",
"mochilas": "背包",
"botas": "鞋履"
}
提供机构:
adam-narozniak
原始信息汇总
数据集概述
数据集名称
- 名称: Clothing Detection Dataset
数据集特征
- 主要特征:
- image: 图像数据
- objects: 对象信息,包括:
- bbox_id: 边界框ID,数据类型为int32
- category: 类别标签,数据类型为分类标签,包含53个类别,如shirt, blouse, top, t-shirt, sweatshirt等
- bbox: 边界框坐标,数据类型为int32,长度为4
- area: 边界框面积,数据类型为int32
- genre: 类别,数据类型为string
- width: 图像宽度,数据类型为int64
- height: 图像高度,数据类型为int64
数据集划分
- 训练集:
- 示例数量: 3332
- 数据大小: 566512000.628字节
数据集大小
- 下载大小: 566302792字节
- 数据集大小: 566512000.628字节
数据集配置
- 默认配置:
- 数据文件路径:
data/train-*
- 数据文件路径:
数据集实例
- 示例结构:
- image: 图像数据
- objects: 对象信息,包括边界框ID、类别、边界框坐标、面积和类别
- width: 图像宽度
- height: 图像高度
类别信息
- 类别数量: 53个
- 类别对应: 包括服装、配饰等多个类别
搜集汇总
数据集介绍
构建方式
该数据集的构建基于对原始西班牙语标注的翻译与调整,使其与Fashionpedia数据集的标注体系相匹配。具体而言,数据集从源代码库中提取图像及其相关对象信息,包括边界框、类别、面积和性别等特征。通过将西班牙语标签转换为英语,并确保其与Fashionpedia的类别一致,数据集得以扩展其类别数量,从而为服装检测任务提供更为丰富的数据支持。
特点
此数据集的显著特点在于其广泛的类别覆盖和精细的对象标注。不仅涵盖了从衣物到配饰的53个类别,还详细标注了每个对象的边界框、面积和性别信息。此外,数据集的图像分辨率高,确保了检测任务的准确性。其与Fashionpedia的兼容性也使得该数据集成为服装检测领域的重要资源。
使用方法
该数据集适用于多种计算机视觉任务,包括对象检测和图像分类。用户可以通过加载数据集的训练部分,利用图像及其详细标注信息进行模型训练。具体操作时,可使用Python的PIL库处理图像数据,并结合深度学习框架如TensorFlow或PyTorch进行模型构建与训练。数据集的结构清晰,便于快速集成到现有的机器学习工作流中。
背景与挑战
背景概述
在时尚与计算机视觉的交叉领域,衣物检测数据集的构建显得尤为重要。adam-narozniak/clothing数据集由Seralexger团队创建,旨在扩展Fashionpedia数据集的类别数量,以支持更广泛的对象检测和图像分类任务。该数据集包含了52个衣物及配饰类别,涵盖了从日常穿着到时尚配饰的广泛范围。通过将原始西班牙语标签翻译为英语,并与Fashionpedia数据集的注释相匹配,该数据集不仅丰富了现有的衣物类别,还为研究人员提供了一个标准化的数据资源,以推动衣物检测技术的发展。
当前挑战
尽管adam-narozniak/clothing数据集在衣物检测领域具有显著的贡献,但其构建过程中仍面临诸多挑战。首先,多语言标签的翻译和匹配过程需要高度的准确性,以确保数据的一致性和可用性。其次,数据集中包含的52个类别在实际应用中可能面临类别不平衡的问题,某些类别可能样本较少,影响模型的泛化能力。此外,衣物检测任务本身具有较高的复杂性,涉及多种材质、颜色和纹理的识别,这对算法的鲁棒性和精确度提出了更高的要求。
常用场景
经典使用场景
在时尚与计算机视觉的交叉领域,adam-narozniak/clothing数据集被广泛应用于对象检测和图像分类任务。该数据集通过提供丰富的服装类别及其详细属性,如衣领、袖口和口袋等,为研究人员提供了一个全面的资源,以训练和评估服装识别模型。其经典使用场景包括但不限于:服装识别、时尚推荐系统以及虚拟试衣应用。
实际应用
在实际应用中,adam-narozniak/clothing数据集被用于开发智能零售系统、时尚推荐引擎和虚拟试衣间。例如,零售商可以利用该数据集训练的模型来识别顾客试穿的服装,从而提供个性化的购物建议。此外,时尚品牌和设计师也可以利用这些数据来分析流行趋势,优化产品设计和市场策略。
衍生相关工作
基于adam-narozniak/clothing数据集,许多相关研究工作得以展开。例如,有研究者利用该数据集开发了基于深度学习的服装推荐系统,通过分析用户的服装偏好来提供个性化的时尚建议。此外,还有研究聚焦于跨文化服装识别,通过该数据集的多语言标注,探索不同文化背景下服装识别的差异和共性。
以上内容由遇见数据集搜集并总结生成


