Occ3D
收藏arXiv2023-12-14 更新2024-06-21 收录
下载链接:
https://tsinghua-mars-lab.github.io/Occ3D/
下载链接
链接失效反馈官方服务:
资源简介:
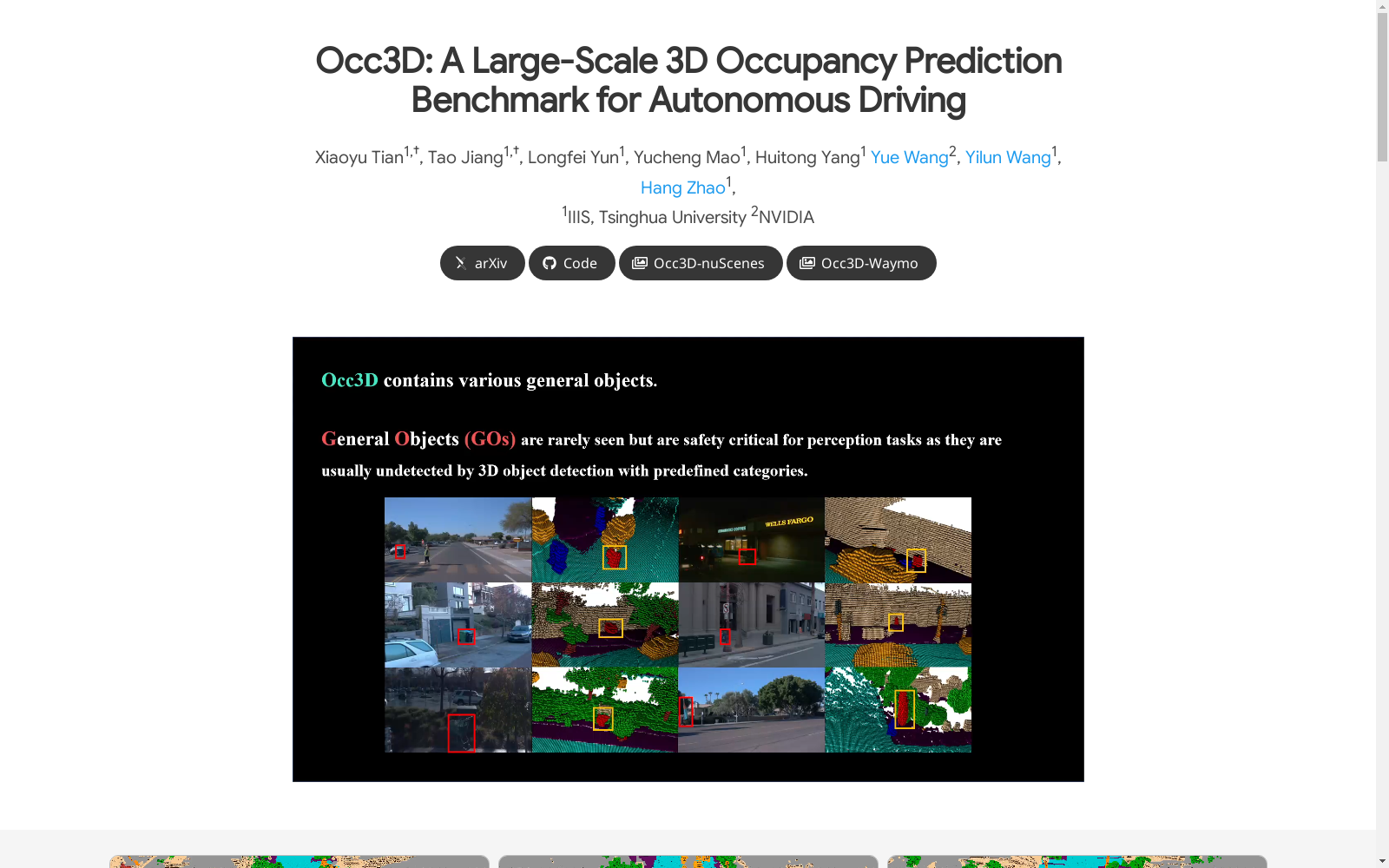
Occ3D数据集是由清华大学智能系统实验室开发的一个大规模3D占用预测基准,专为自动驾驶感知设计。该数据集包含200,000帧,涵盖了丰富的场景多样性和几何表达性,包括无法在现实世界中广泛枚举的词汇外对象和3D边界框无法准确表示其精确几何形状的不规则形状对象。数据集的创建过程涉及三个阶段:体素密集化、遮挡推理和图像引导的体素细化。Occ3D数据集的应用领域主要集中在自动驾驶技术中,旨在解决3D空间中对象的详细几何和语义建模问题,特别是在处理预定义类别之外的对象时。
The Occ3D dataset is a large-scale 3D occupancy prediction benchmark developed by the Intelligent Systems Laboratory of Tsinghua University, specifically designed for autonomous driving perception. This dataset contains 200,000 frames, covering rich scene diversity and geometric expressiveness, including out-of-vocabulary objects that cannot be extensively enumerated in the real world and irregularly shaped objects whose precise geometry cannot be accurately represented by 3D bounding boxes. The development process of the Occ3D dataset involves three stages: voxel densification, occlusion reasoning, and image-guided voxel refinement. The main application scenarios of the Occ3D dataset focus on autonomous driving technologies, aiming to address the detailed geometric and semantic modeling of objects in 3D space, especially when handling objects outside predefined categories.
提供机构:
清华大学智能系统实验室
创建时间:
2023-04-28
搜集汇总
数据集介绍
构建方式
Occ3D数据集的构建方式主要依托于LiDAR扫描和图像标注。首先,通过多帧聚合分别对静态和动态物体进行点云密度提升,然后利用K最近邻算法为未标记点分配语义标签,并通过网格重建进行孔洞填充。其次,从LiDAR和相机两个视角进行遮挡推理,利用射线投射操作标记每个体素的占用状态。最后,通过图像引导的体素细化过程消除不准确的体素。整个流程通过3D-2D一致性指标进行验证,确保生成的标注密集且可见。
特点
Occ3D数据集的特点包括:1)提供环绕视图图像和高分辨率3D体素占用表示;2)包含最多样化的场景;3)支持对预定义类别之外的通用对象进行预测。与SemanticKITTI和KITTI-360等传统数据集相比,Occ3D提供了更全面的标注和更高的分辨率。
使用方法
Occ3D数据集的使用方法包括:1)下载数据集和基准;2)根据文档说明进行数据集的准备和预处理;3)选择合适的模型进行3D占用预测任务;4)使用提供的评估指标进行模型性能评估。数据集和代码已在官方网站和GitHub上公开发布,方便研究人员使用和复现实验结果。
背景与挑战
背景概述
在机器人感知领域,尤其是自动驾驶系统中,三维感知是一项关键任务。现有的方法通常专注于估计三维边界框,这些边界框虽然紧凑,但表达能力受限,难以处理通用的、超出词汇表的物体。三维占据预测,即估计场景中每个体素的详细占据状态和语义,是一项新兴任务,旨在克服这些局限性。为了支持三维占据预测,研究人员开发了一个标签生成流程,为任何给定场景生成密集的、可见性感知的标签。该流程包括三个阶段:体素加密、遮挡推理和图像引导的体素细化。基于Waymo公开数据集和nuScenes数据集,建立了两个基准,即Occ3D-Waymo和Occ3D-nuScenes基准。此外,还提供了对所提出数据集的各种基线模型的广泛分析。最后,提出了一种新的模型,称为粗到细占据(CTF-Occ)网络,该网络在Occ3D基准上表现出优异的性能。
当前挑战
尽管三维占据预测取得了进展,但高质量的基准数据集仍然缺乏。构建此类数据集具有挑战性,主要问题包括稀疏性、遮挡和三维到二维的错位。为了克服这些障碍,研究人员创建了一个半自动标签生成流程,包括三个步骤:体素加密、遮挡推理和图像引导的体素细化。每个步骤都通过三维到二维一致性指标进行验证,证明所提出的标签生成流程能够有效地生成密集的、可见性感知的注释。
常用场景
经典使用场景
Occ3D数据集是一个大规模的3D占用预测基准,主要用于自动驾驶领域的视觉感知研究。该数据集提供了丰富的语义和几何表达性,能够帮助研究人员更好地理解场景中的3D几何和语义信息。其经典使用场景包括自动驾驶中的3D物体检测、语义场景完成和3D占用网格映射等。通过使用Occ3D数据集,研究人员可以训练和评估3D占用预测模型,从而提高自动驾驶系统的感知能力,使其能够更好地理解周围环境并做出更安全的决策。
实际应用
Occ3D数据集的实际应用场景主要集中在自动驾驶领域。通过使用该数据集训练的3D占用预测模型,自动驾驶系统可以更好地理解周围环境,包括车辆、行人、建筑物、道路等。这有助于提高自动驾驶系统的感知能力,使其能够更准确地识别和跟踪目标,从而实现更安全的驾驶。此外,Occ3D数据集还可以用于其他需要3D场景理解的领域,如机器人、虚拟现实等。
衍生相关工作
Occ3D数据集的提出衍生了许多相关的经典工作。例如,基于Occ3D数据集,研究人员提出了Coarse-to-Fine Occupancy (CTF-Occ)网络,该网络通过将2D图像特征聚合到3D空间,并使用交叉注意力机制进行特征细化,实现了高效的粗到细3D占用预测。CTF-Occ网络在Occ3D基准上取得了优异的性能,为3D占用预测任务提供了新的思路和方法。此外,Occ3D数据集还为其他3D占用预测模型提供了基准,有助于推动相关领域的研究进展。
以上内容由遇见数据集搜集并总结生成


