CIGEval_sft_data
收藏CIGEval_sft_data 数据集概述
数据集描述
- 用途: 用于在论文CIGEval中微调LMMs(大型多模态模型)
- 构建过程:
- 使用GPT-4o + CIGEval评估完整的ImageHub数据集,生成4,903条评估轨迹
- 随机选择60%的轨迹,筛选出评估结果与人类评分差异小于0.3的样本,得到2.3k条轨迹
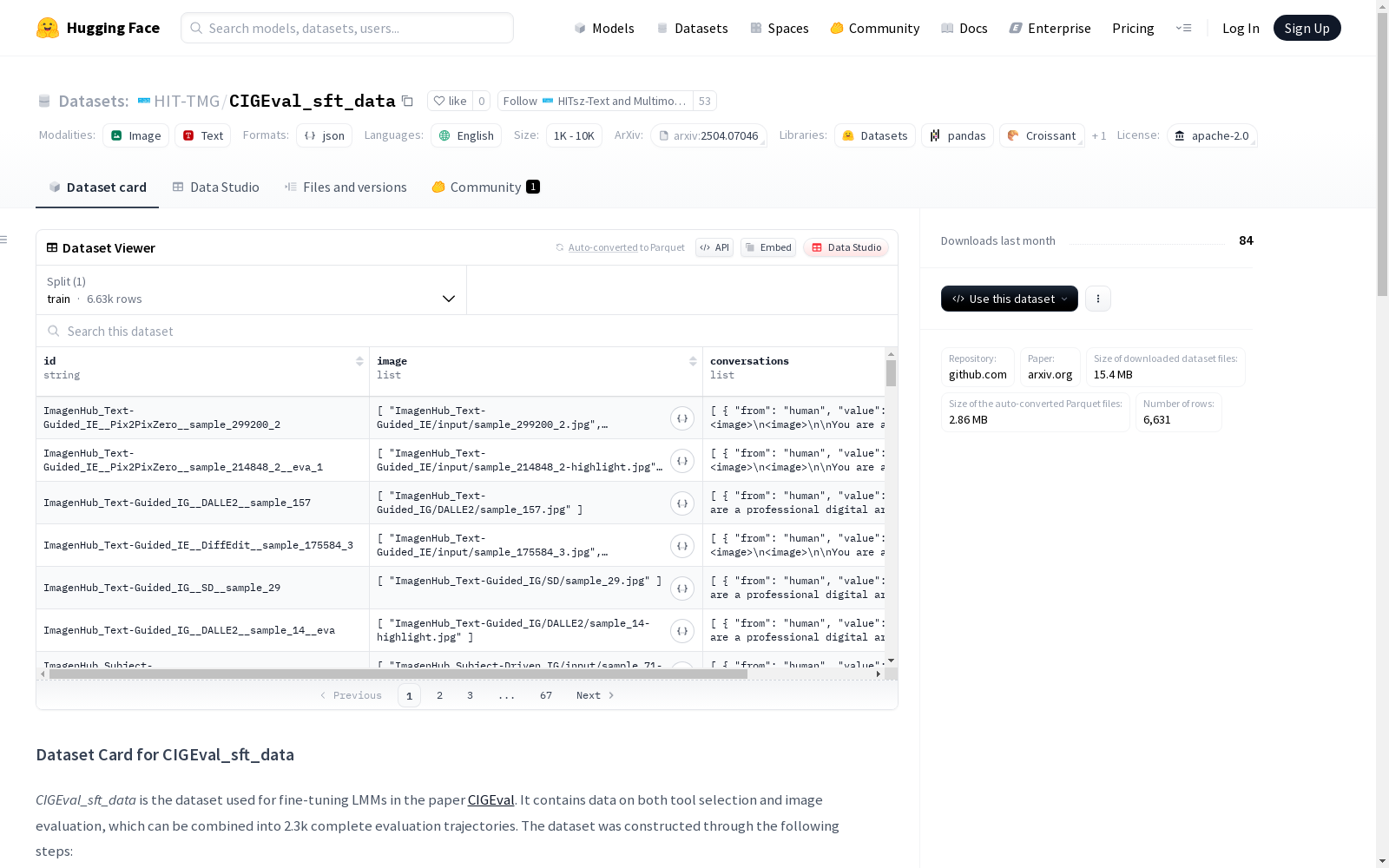
- 将这些轨迹分解为多轮工具选择和图像评估任务,共产生6.6k个样本
数据集结构
- 文件组成:
image_eva.json: 图像评估样本image_eva_out.json: 图像评估样本输出tool_use.json: 工具选择样本tool_use_out.json: 工具选择样本输出train.json: 包含所有工具选择和图像评估样本images/: 包含待评估图像和工具处理后的图像ImagenHub_Control-Guided_IG/ControlNet/sample_9_control_hed.jpg- ......
数据实例
工具选择示例
python { "id": "ImagenHub_Text-Guided_IG__DALLE2__sample_157", "image": ["ImagenHub_Text-Guided_IG/DALLE2/sample_157.jpg"], "conversations": [ {"from": "human", "value": "<image>
You are a professional digital artist..."}, {"from": "gpt", "value": " [{"task_id":"1","reasoning":"The task is to evaluate...","used":"yes","tool":"Highlight"}] "} ] }
图像评估示例
python { "id": "ImagenHub_Text-Guided_IG__DALLE2__sample_14__eva", "image": ["ImagenHub_Text-Guided_IG/DALLE2/sample_14-highlight.jpg"], "conversations": [ {"from": "human", "value": "<image>
You are a professional digital artist..."}, {"from": "gpt", "value": "{"score":7,"reasoning":"The image shows a car on the street..."}"} ] }
引用
bibtex @misc{wang2025cigeval, title={A Unified Agentic Framework for Evaluating Conditional Image Generation}, author={Jifang Wang and Xue Yang and Longyue Wang and Zhenran Xu and Yiyu Wang and Yaowei Wang and Weihua Luo and Kaifu Zhang and Baotian Hu and Min Zhang}, year={2025}, eprint={2504.07046}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2504.07046}, }