NomaDamas/asqa_origin
收藏Hugging Face2024-01-07 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/NomaDamas/asqa_origin
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
- config_name: dev
features:
- name: ambiguous_question
dtype: string
- name: qa_pairs
list:
- name: context
dtype: string
- name: question
dtype: string
- name: short_answers
sequence: string
- name: wikipage
dtype: string
- name: wikipages
list:
- name: title
dtype: string
- name: url
dtype: string
- name: annotations
list:
- name: knowledge
list:
- name: content
dtype: string
- name: wikipage
dtype: string
- name: long_answer
dtype: string
- name: __index_level_0__
dtype: string
splits:
- name: validation
num_bytes: 2986266
num_examples: 948
download_size: 1460867
dataset_size: 2986266
- config_name: train
features:
- name: ambiguous_question
dtype: string
- name: qa_pairs
list:
- name: context
dtype: string
- name: question
dtype: string
- name: short_answers
sequence: string
- name: wikipage
dtype: string
- name: wikipages
list:
- name: title
dtype: string
- name: url
dtype: string
- name: annotations
list:
- name: knowledge
list:
- name: content
dtype: string
- name: wikipage
dtype: string
- name: long_answer
dtype: string
- name: __index_level_0__
dtype: string
splits:
- name: train
num_bytes: 9765983
num_examples: 4353
download_size: 5336235
dataset_size: 9765983
configs:
- config_name: dev
data_files:
- split: validation
path: dev/validation-*
- config_name: train
data_files:
- split: train
path: train/train-*
---
# Dataset Card for "asqa_origin"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
dataset_info:
- 配置名称: dev
特征字段:
- 歧义问题(ambiguous_question): 数据类型为字符串
- 问答对(qa_pairs): 列表类型,包含以下子字段:
- 上下文(context): 数据类型为字符串
- 问题(question): 数据类型为字符串
- 简短答案(short_answers): 字符串序列
- 维基页面(wikipage): 数据类型为字符串
- 维基页面列表(wikipages): 列表类型,包含以下子字段:
- 标题(title): 数据类型为字符串
- 统一资源定位符(url): 数据类型为字符串
- 标注信息(annotations): 列表类型,包含以下子字段:
- 知识(knowledge): 列表类型,包含以下子字段:
- 内容(content): 数据类型为字符串
- 维基页面(wikipage): 数据类型为字符串
- 长答案(long_answer): 数据类型为字符串
- __index_level_0__: 数据类型为字符串
划分集:
- 名称: 验证集(validation),字节数: 2986266,样本数量: 948
下载大小: 1460867
数据集占用大小: 2986266
- 配置名称: train
特征字段:
- 歧义问题(ambiguous_question): 数据类型为字符串
- 问答对(qa_pairs): 列表类型,包含以下子字段:
- 上下文(context): 数据类型为字符串
- 问题(question): 数据类型为字符串
- 简短答案(short_answers): 字符串序列
- 维基页面(wikipage): 数据类型为字符串
- 维基页面列表(wikipages): 列表类型,包含以下子字段:
- 标题(title): 数据类型为字符串
- 统一资源定位符(url): 数据类型为字符串
- 标注信息(annotations): 列表类型,包含以下子字段:
- 知识(knowledge): 列表类型,包含以下子字段:
- 内容(content): 数据类型为字符串
- 维基页面(wikipage): 数据类型为字符串
- 长答案(long_answer): 数据类型为字符串
- __index_level_0__: 数据类型为字符串
划分集:
- 名称: 训练集(train),字节数: 9765983,样本数量: 4353
下载大小: 5336235
数据集占用大小: 9765983
configs:
- 配置名称: dev
数据文件:
- 划分集: 验证集(validation),路径: dev/validation-*
- 配置名称: train
数据文件:
- 划分集: 训练集(train),路径: train/train-*
---
# "asqa_origin" 数据集卡片(Dataset Card)
[需要更多信息](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
提供机构:
NomaDamas
原始信息汇总
数据集概述
配置信息
-
dev
- 特征
ambiguous_question: 类型为字符串。qa_pairs: 列表类型,包含以下子特征:context: 类型为字符串。question: 类型为字符串。short_answers: 序列类型,元素为字符串。wikipage: 类型为字符串。
wikipages: 列表类型,包含以下子特征:title: 类型为字符串。url: 类型为字符串。
annotations: 列表类型,包含以下子特征:knowledge: 列表类型,包含以下子特征:content: 类型为字符串。wikipage: 类型为字符串。
long_answer: 类型为字符串。
__index_level_0__: 类型为字符串。
- 分割
validation: 字节数为2986266,示例数为948。
- 下载大小: 1460867字节
- 数据集大小: 2986266字节
- 特征
-
train
- 特征
ambiguous_question: 类型为字符串。qa_pairs: 列表类型,包含以下子特征:context: 类型为字符串。question: 类型为字符串。short_answers: 序列类型,元素为字符串。wikipage: 类型为字符串。
wikipages: 列表类型,包含以下子特征:title: 类型为字符串。url: 类型为字符串。
annotations: 列表类型,包含以下子特征:knowledge: 列表类型,包含以下子特征:content: 类型为字符串。wikipage: 类型为字符串。
long_answer: 类型为字符串。
__index_level_0__: 类型为字符串。
- 分割
train: 字节数为9765983,示例数为4353。
- 下载大小: 5336235字节
- 数据集大小: 9765983字节
- 特征
数据文件配置
- dev
validation: 路径为dev/validation-*
- train
train: 路径为train/train-*
搜集汇总
数据集介绍
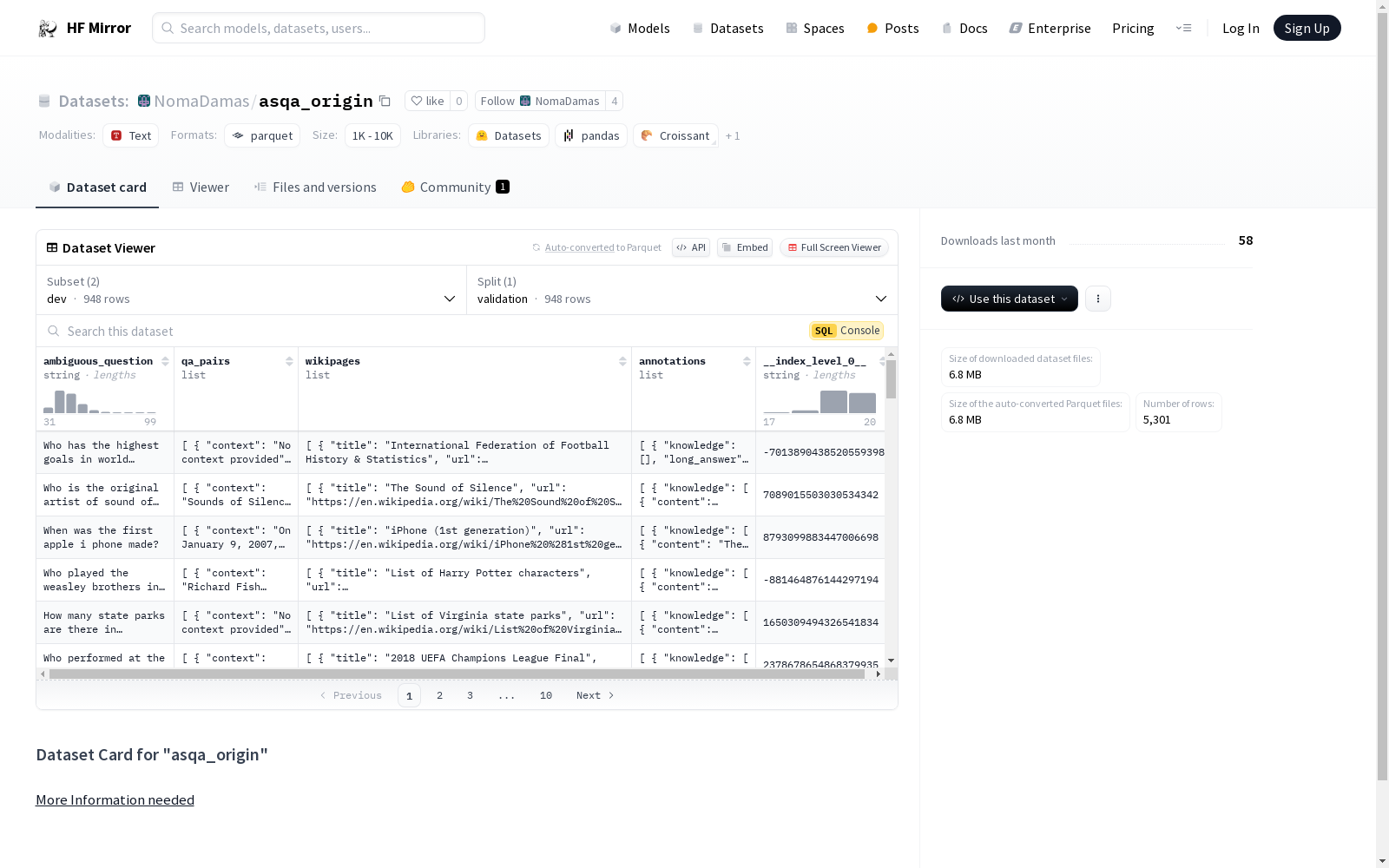
构建方式
NomaDamas/asqa_origin数据集的构建基于对歧义问题的深入分析与解答。该数据集通过收集具有歧义性的问题及其对应的问答对,结合上下文信息、简短答案、维基页面标题与URL等多维度数据,构建了一个多层次的知识库。此外,数据集还包含了详细的标注信息,包括知识内容、长答案等,以支持更复杂的问答任务。
使用方法
NomaDamas/asqa_origin数据集适用于多种自然语言处理任务,特别是歧义问题解析与问答系统开发。用户可以通过加载数据集中的不同配置(如dev和train)来获取相应的数据子集,并利用其中的歧义问题、问答对、上下文信息等进行模型训练与评估。数据集的详细标注信息可用于构建更复杂的问答模型,提升模型在处理歧义问题时的准确性和鲁棒性。
背景与挑战
背景概述
ASQA_Origin数据集由NomaDamas团队创建,专注于解决多义性问题在问答系统中的挑战。该数据集的核心研究问题是如何有效处理和解析具有多义性的问题,通过提供上下文、问题、简短答案、长答案以及相关维基页面信息,帮助模型更好地理解并回答这些问题。该数据集的创建旨在提升问答系统的准确性和鲁棒性,特别是在面对复杂和多义性问题时。其对自然语言处理领域的贡献在于为研究人员提供了一个标准化的测试平台,以评估和改进现有问答模型的性能。
当前挑战
ASQA_Origin数据集在构建过程中面临的主要挑战包括:首先,如何准确识别和标注多义性问题,确保数据集的多样性和代表性;其次,如何有效地整合和利用维基页面信息,以提供更全面和准确的答案。此外,数据集的规模和复杂性也带来了处理和存储上的挑战,特别是在处理大规模文本数据时,如何保证数据的一致性和高效性。这些挑战不仅影响了数据集的构建过程,也对后续的模型训练和评估提出了更高的要求。
常用场景
经典使用场景
在自然语言处理领域,NomaDamas/asqa_origin数据集的经典使用场景主要集中在多轮问答系统的构建与评估。该数据集通过提供模糊问题及其对应的问答对,帮助研究者训练和测试模型在复杂语境下的理解与推理能力。特别是,数据集中的'qa_pairs'特征包含了上下文、问题和简短答案,为模型提供了丰富的语境信息,使其能够在多轮对话中准确捕捉用户意图。
解决学术问题
NomaDamas/asqa_origin数据集解决了自然语言处理中多轮问答系统的核心问题,即如何在复杂语境下准确理解并生成合适的回答。通过提供模糊问题及其对应的问答对,该数据集为研究者提供了一个标准化的测试平台,用以评估和改进模型在多轮对话中的表现。这不仅推动了问答系统的发展,也为相关领域的学术研究提供了宝贵的资源。
实际应用
在实际应用中,NomaDamas/asqa_origin数据集被广泛用于开发智能客服系统、虚拟助手和在线教育平台等需要多轮对话功能的应用。通过利用该数据集训练的模型,这些系统能够更有效地处理用户的模糊查询,提供更精准的答案,从而提升用户体验。此外,该数据集还在信息检索和知识图谱构建等领域展现了其应用价值。
数据集最近研究
最新研究方向
在自然语言处理领域,NomaDamas/asqa_origin数据集的最新研究方向主要集中在多轮对话系统中的歧义问题解决与知识整合。该数据集通过提供模糊问题及其对应的问答对,促进了模型对复杂语境的理解与推理能力。研究者们正致力于开发更高效的算法,以从多源知识中提取并整合信息,从而提升问答系统的准确性与鲁棒性。这一研究方向不仅推动了对话系统的智能化发展,也为知识图谱与语义理解技术的融合提供了新的视角。
以上内容由遇见数据集搜集并总结生成


