ChineseClassicalPoetryDatabase
收藏Hugging Face2026-01-17 更新2026-01-18 收录
下载链接:
https://huggingface.co/datasets/PoetryMTEB/ChineseClassicalPoetryDatabase
下载链接
链接失效反馈官方服务:
资源简介:
一个包含中国古典诗歌及其元数据和基于DeepSeek-V3.1大模型分析结果的综合数据库。数据集分为两部分:'corpus'部分包含诗歌的基本信息(如朝代、作者、标题、类型和正文),'analysis'部分包含对诗歌的创作意图、题材、主题、思想和情感的分析。数据来源于搜韵网和知识图谱网,使用DeepSeek-V3.1进行诗歌分析。
创建时间:
2026-01-15
原始信息汇总
Chinese Classical Poetry Database 数据集概述
数据集简介
这是一个包含中国古典诗歌及其元数据和LLM分析结果的综合性数据库。数据集内容由DeepSeek-V3.1模型生成分析结果。
数据集结构
数据集包含两个主要配置:
1. 语料库配置 (corpus)
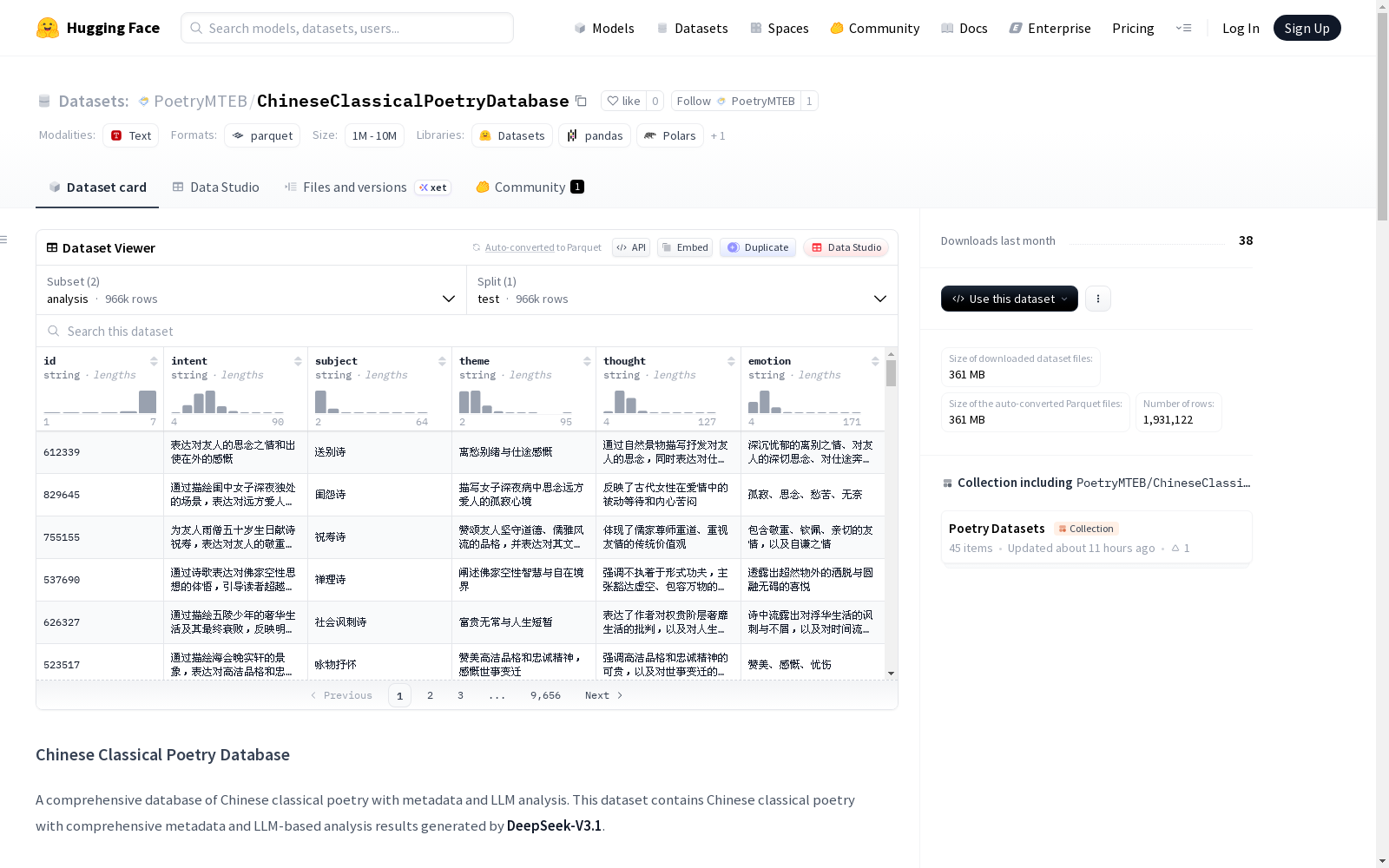
包含每首诗的基本元数据和文本,共965,561个示例,数据集大小为180,559,406字节。 特征字段:
id: 诗歌唯一标识符dynasty: 朝代/时期author: 作者姓名title: 诗歌标题type: 诗歌类型/体裁text: 诗歌内容
2. 分析配置 (analysis)
包含每首诗的LLM分析结果,共965,561个示例,数据集大小为180,627,204字节。 特征字段:
id: 诗歌标识符(与语料库关联)intent: 创作意图分析subject: 题材分析theme: 主题分析thought: 哲学思想分析emotion: 情感表达分析
数据来源
- 搜韵网: https://sou-yun.com/
- 知识图谱网: https://cnkgraph.com/Home/OpenResources
LLM分析详情
分析结果使用DeepSeek-V3.1生成,提示词结构要求模型以严格JSON格式返回创作意图、题材、主题、思想和情感的分析结果。
使用示例
可通过datasets库加载数据集,支持分别加载corpus或analysis配置,也可合并使用。
数据集统计
| 分割名称 | 配置 | 示例数量 | 内容 |
|---|---|---|---|
| 语料库 | corpus |
965,561 | 元数据和文本 |
| 分析 | analysis |
965,561 | LLM分析结果 |
引用要求
使用本数据集时需引用:
- 数据来源:搜韵网(https://sou-yun.com/)和知识图谱网(https://cnkgraph.com/Home/OpenResources)
- LLM模型:DeepSeek-V3.1
许可协议
本数据集基于cc-by-nc-4.0许可证发布。
搜集汇总
数据集介绍
构建方式
在古典文学数字化浪潮中,ChineseClassicalPoetryDatabase的构建体现了系统化与智能化的结合。其基础语料源自搜韵网与知识图谱网等权威公开资源,涵盖了近百万首诗词的原始文本与元数据。构建过程的核心创新在于运用DeepSeek-V3.1大语言模型对全部诗作进行深度分析,通过精心设计的结构化提示词,自动化地解析每首诗的创作意图、题材、主题、思想与情感,并将分析结果以标准JSON格式输出,最终形成与原始语料一一对应的分析数据集。
使用方法
利用该数据集进行研究,通常从加载特定的配置开始。通过Hugging Face的`datasets`库,可以分别加载`corpus`或`analysis`配置,获取原始语料或分析结果。研究者可将两者通过唯一的诗歌标识符`id`进行关联与合并,从而构建一个包含原始文本与多维度分析标签的完整数据框架。这种使用方法支持灵活的探索,既可进行大规模的统计分析与主题建模,也能针对特定诗人、朝代或主题进行深入的个案研究,为古典诗词的计算人文研究提供了高效的工具。
背景与挑战
背景概述
中国古典诗歌数据库(Chinese Classical Poetry Database)是数字人文领域的一项重要资源,由PoetryMTEB团队构建并于近期发布。该数据集旨在系统性地整理与解析中国古典诗歌,其核心研究问题聚焦于如何利用现代计算技术对浩瀚的古典诗歌文本进行结构化存储与深度语义分析。数据集收录了自搜韵网与知识图谱网获取的近百万首诗歌,并借助DeepSeek-V3.1大语言模型为每首作品生成了涵盖创作意图、题材、主题、思想与情感的多维度分析。这一工作不仅为古典文学研究提供了大规模、可计算的数据基础,也推动了自然语言处理技术在文化遗产数字化领域的创新应用,对诗歌自动分析、风格建模及跨时代文学研究产生了深远影响。
当前挑战
该数据集致力于解决中国古典诗歌计算分析领域的核心挑战,即如何超越传统的字词统计,实现对诗歌深层语义、美学价值与文化内涵的自动化理解。具体挑战包括:诗歌语言的凝练性、隐喻性与历史语境依赖性,使得自动解析创作意图与哲学思想极为困难;不同朝代、体裁与作者风格的巨大差异,对构建统一的语义表示模型提出了严峻考验。在构建过程中,团队亦面临诸多工程挑战:从异构网络源整合近百万首诗歌的元数据与文本,需确保数据的完整性、准确性与版权合规;利用大语言模型进行批量分析时,需设计精准的提示工程以控制生成内容的稳定性与一致性,并处理大规模计算带来的资源与效率问题。
常用场景
经典使用场景
在古典文学与计算语言学交叉领域,ChineseClassicalPoetryDatabase为研究者提供了大规模、结构化的诗歌文本及其深度分析。该数据集最经典的使用场景在于支持基于机器学习的古典诗歌自动分类与情感分析任务。通过其包含的朝代、作者、体裁等元数据,结合由DeepSeek-V3.1生成的创作意图、主题、情感等分析标签,研究者能够训练模型以识别诗歌的文学风格、时代特征与情感倾向,为古典文学的定量研究奠定了数据基础。
解决学术问题
该数据集有效解决了古典文学研究中文本分析规模有限、主观解读难以量化等常见学术问题。通过提供近百万首诗歌的结构化文本及机器生成的标准化分析,它使得大规模的风格演变研究、作者 attribution 考证以及跨朝代主题比较成为可能。其意义在于将传统文献学方法与现代自然语言处理技术相结合,为文学研究提供了可重复、可扩展的实证分析框架,推动了数字人文领域的方法论创新。
实际应用
在实际应用层面,ChineseClassicalPoetryDatabase为文化教育、智能创作与知识服务提供了核心资源。教育机构可基于其构建交互式诗歌学习平台,帮助学生理解诗歌的深层内涵与历史背景;在人工智能领域,该数据集可作为训练数据,支撑诗歌自动生成、风格模仿或文学问答系统;此外,博物馆、数字图书馆等文化机构也能利用其丰富的元数据与分析结果,开发沉浸式的文化展示与检索工具。
数据集最近研究
最新研究方向
在数字人文与计算文学研究领域,ChineseClassicalPoetryDatabase凭借其大规模古典诗歌文本与深度大语言模型分析结果,正推动前沿研究向智能化、细粒度方向发展。当前研究热点聚焦于利用其分析分割中的意图、主题、情感等多维度标注,训练或微调专用模型以进行诗歌风格迁移、情感演化脉络追踪及跨朝代文学思想比较。这一数据集将传统文学分析与现代人工智能技术深度融合,为古典诗歌的自动化阐释、知识图谱构建以及文化传承的数字化创新提供了关键数据支撑,显著提升了该领域研究的可计算性与解释深度。
以上内容由遇见数据集搜集并总结生成


